
Abstract
- Next token prediction으로 학습한 GPT가 온갖 task를 잘한다.
- Computer Vision에서도 이런 만능 모델을 만들고 싶어서 새로운 task, model, data를 개발했다.
- Segmentation은 당연히 잘하고, 다른 테스크들에서도 성능이 높음.
CV 분야에서 파운데이션 모델(Foundation model)을 만드려는 시도
파운데이션 모델(Foundation model)이란 하나의 테스크로 학습시킨 모델이 학습하지 않았던 다양한 분야에 바로 적용될 수 있는 general한 모델 ( ex. gpt )
Motivation
최근에 출시된 대규모의 언어모델 (ex. chat GPT)은 Zero-shot / Few-shot Generalization 성능을 보이고 있습니다. 이러한 Foundation model 들은 종종 Prompt Engineering을 통해 여러가지 Task에 대해 적절한 텍스트 응답을 생성해주는 기능을 합니다.
이 논문에서는 Image Segmentation에서 Foundation model을 만드는 것을 목표로 합니다. Generalization을 바탕으로 Prompt Engineering을 통해 여러 종류의 Image Segmentation 문제를 해결하고 Chat GPT와 같은 서비스처럼 모두가 사용할 수 있는 것을 노립니다.
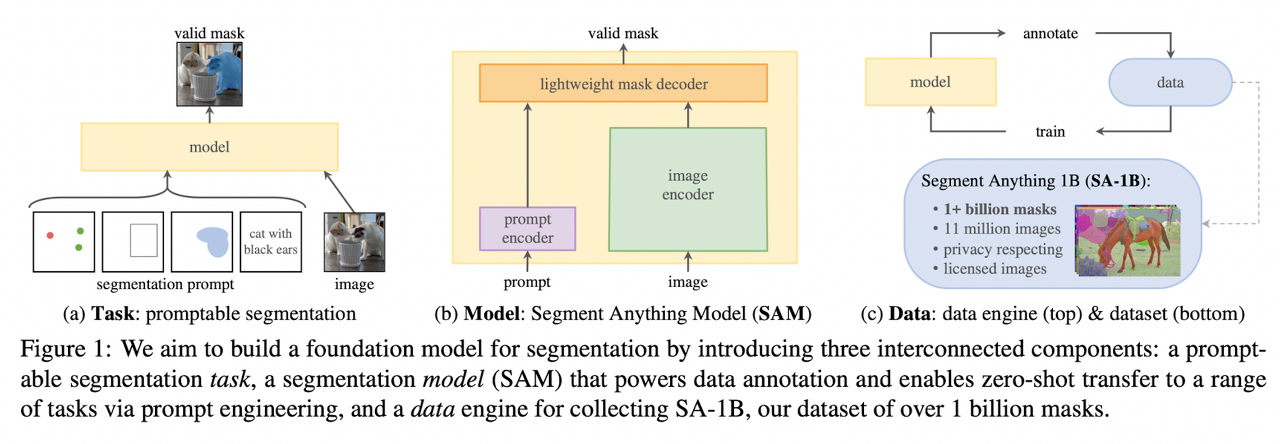
논문의 저자들은 다음과 같은 질문을 던집니다.
- What task will enable zero-shot generalization? - Zero-shot Generalization을 가능하게 하는 Task는 무엇인가?
- What is the corresponding model architecture? - 적절한 Model 구조는 무엇인가?
- What data can power this task and model? - 1의 Task와 2의 Model에 적합한 Data는?
Segment Anything Model
모델은 크게 Image encoder, Prompt encoder, Mask decoder 영역으로 분리할 수 있습니다. 편의상 Prompt encoder / Mask decoder을 하나로 묶어 Prompt 모델이라 부르겠습니다.
Image encoder는 고해상도 이미지를 처리하기 위한 ViT(Vision Transformer) 기반 모델로 추론 시 상대적으로 더 긴 시간이 소요됩니다. 테스트 결과 vit_l 모델을 사용했을 때 1080x1920 이미지 한 장 기준 0.699s(RTX 3090), 8.257s(CPU)의 시간이 걸렸습니다.
반면 Prompt 모델은 실시간 추론이 가능할 정도로 짧은 처리 시간을 갖습니다. 또한 동일한 image embedding으로 여러 promptable task(point, bounding box, mask, text)에 재활용 할 수 있다는 특성을 갖습니다.
이 모델은 3가지 요소로 이루어져 있습니다.
Powerful Image Encoder , Prompt Encoder, Mask Decoder
Image encoder에 비해 Prompt encoder와 Mask decoder는 아주 가벼워서 웹에서도 50ms 이내로 동작한다고 합니다.
Data
- Assited Manual → 4.3 M : 기존 데이터셋으로(LVISv1, MS COCO, ADE20, Open Images) SAM 모델을 학습, AI가 먼저 segmentation을 해놓으면 사람이 이를 수정 및 추가합니다.
- Semi Automatic → 10.2 M : 이전 단계에서 모은 데이터셋으로 SAM 모델 학습. AI가 먼저 Segmentation을 하고 사람이 빠진 것들을 채워넣습니다. 이런 방식으로 마스크 590만개를 추가적으로 라벨링합니다. ( 총 1020만개 )
- Fully automatic → 1.1 B : 1,2 단계에서 모은 마스크 1020만개를 가지고 SAM 모델을 학습합니다. 이걸 가지고 이미지 1100만장에 대해 11억개의 마스크 라벨을 생성한게 SA-1B 데이터셋입니다.

Model
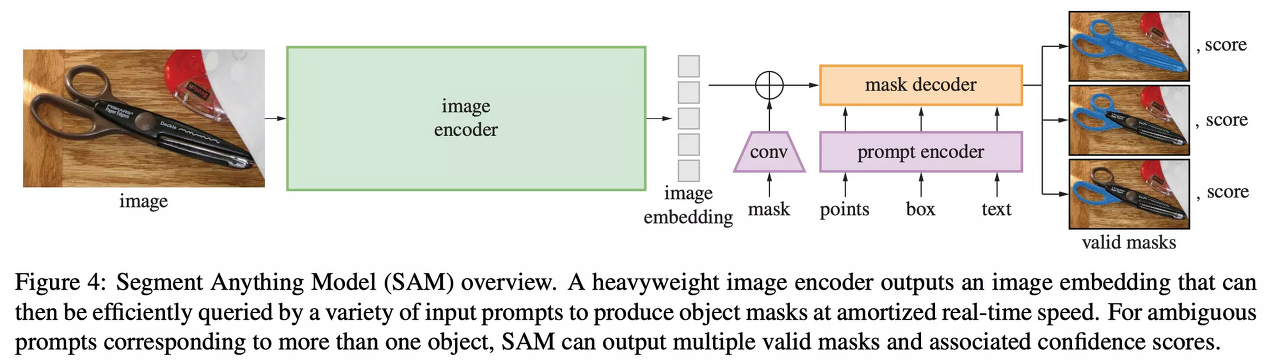
Task 정의과 Data 수집이 끝났으니 Model이 어떻게 돌아가는지 확인해봐야겠죠?
image encoder 부분은 image encoder MAE(Masked auto-encoder) 방식으로 학습시킨 Vision Transformer를 사용합니다. MAE는 이미지를 일정한 크기의 그리드로 나누고 랜덤하게 가린 뒤, 복원하도록 모델을 학습시키는 기법입니다. Decoder는 모델 학습시에만 사용한 뒤 사용하지 않고, Encoder만 사용합니다.
ViT는 이미지를 일정한 크기의 Patch로 쪼갠 뒤, 자연어에서 토큰처럼 사용하는 Transformer 모델로 많은 computer vision 테스크에서 기본 블럭으로 사용됩니다.
https://minyoungxi.tistory.com/51
논문 리뷰 - Vision Transformer 비전 트랜스포머 ( 어텐션을 CV에 ?? ) part1
우선 CNN ViT는 비전 분야의 새로운 패러다임입니다. 기존의 비전 분야에서는 CNN을 사용했습니다. CNN은 필터가 움직이면서 전체의 이미지를 부분적으로 인식하게 되죠? CNN은 한 번 연산시 국소적
minyoungxi.tistory.com
https://minyoungxi.tistory.com/52
논문 리뷰 - Vision Transformer 비전 트랜스포머 part2
https://minyoungxi.tistory.com/51 ViT의 장점 transformer 구조를 거의 그대로 사용하기 때문에 확장성이 좋음 large 스케일 학습에서 매우 우수한 성능을 보임 transfer learning 시 CNN보다 훈련에 더 적은 계산 리
minyoungxi.tistory.com
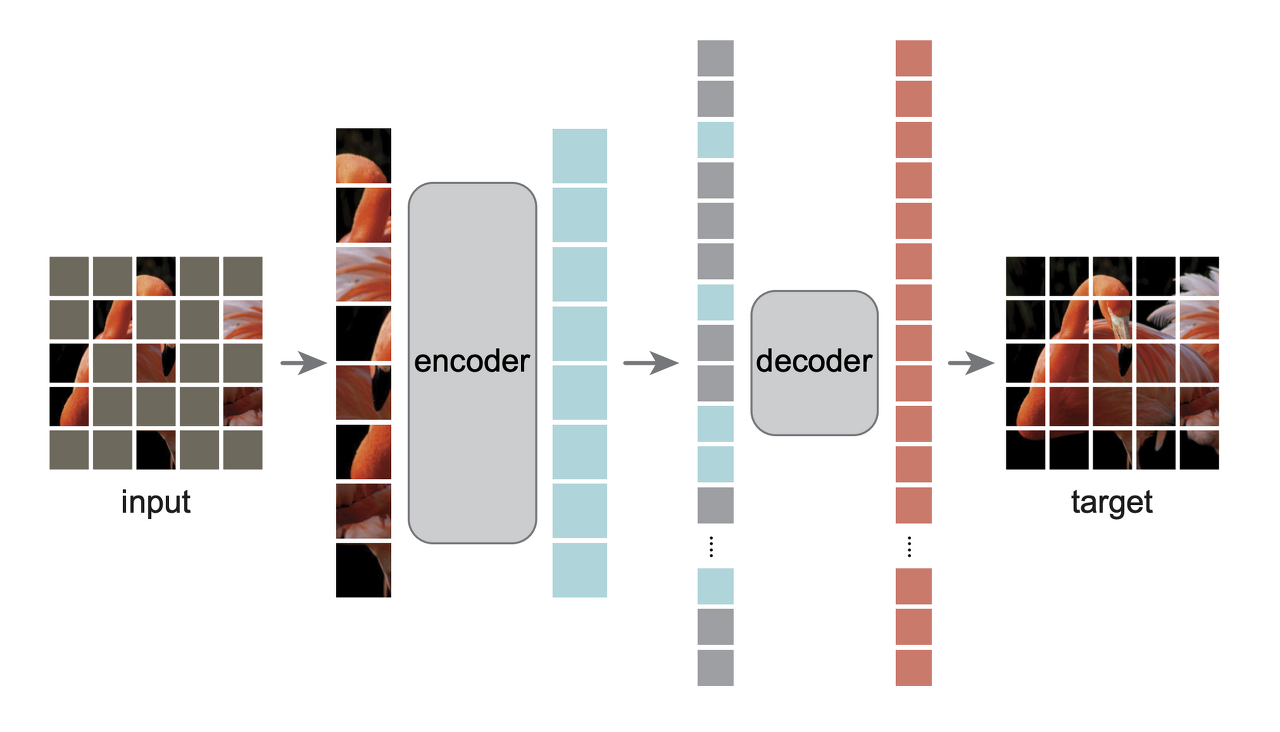
MAE 방식은 input 이미지를 랜덤하게 특정 패치를 가린 것입니다. Masked 했다고 표현하죠?
ViT에서 하는 방식과 동일하게 이미지를 나눈 patch들을 쭉 펴서 encoder에 넣어줍니다. 그리고 Decoder 단계에서 원래 이미지를 복원하는 방식으로 학습을 진행합니다.
Prompt Encoder는 각 prompt 타입에 맞는 Encoding 방식을 적용합니다.
Mask : 컨볼루션으로 차원을 맞춘 뒤, image embedding에 pixel wise sum을 합니다.
Point & Bounding Box : positional encoding으로 표현합니다.
Text : CLIP 방식의 text encoder를 가져와 embedding 합니다.
Pixel wise sum : "Pixel-wise sum"은 이미지 처리 및 컴퓨터 비전 분야에서 사용되는 용어로, 두 개 또는 그 이상의 이미지에서 동일한 위치에 있는 픽셀 값을 더하는 연산을 의미합니다. 여러 이미지를 합쳐서 더 밝거나 노이즈를 줄이는 등의 효과를 얻기 위해 사용될 수 있습니다. 물론, 더하기 연산 후에 픽셀 값이 특정 범위 (예: 0-255)를 초과하지 않도록 주의해야 합니다. 초과하는 경우 값을 제한하거나 정규화하는 과정이 필요할 수 있습니다.
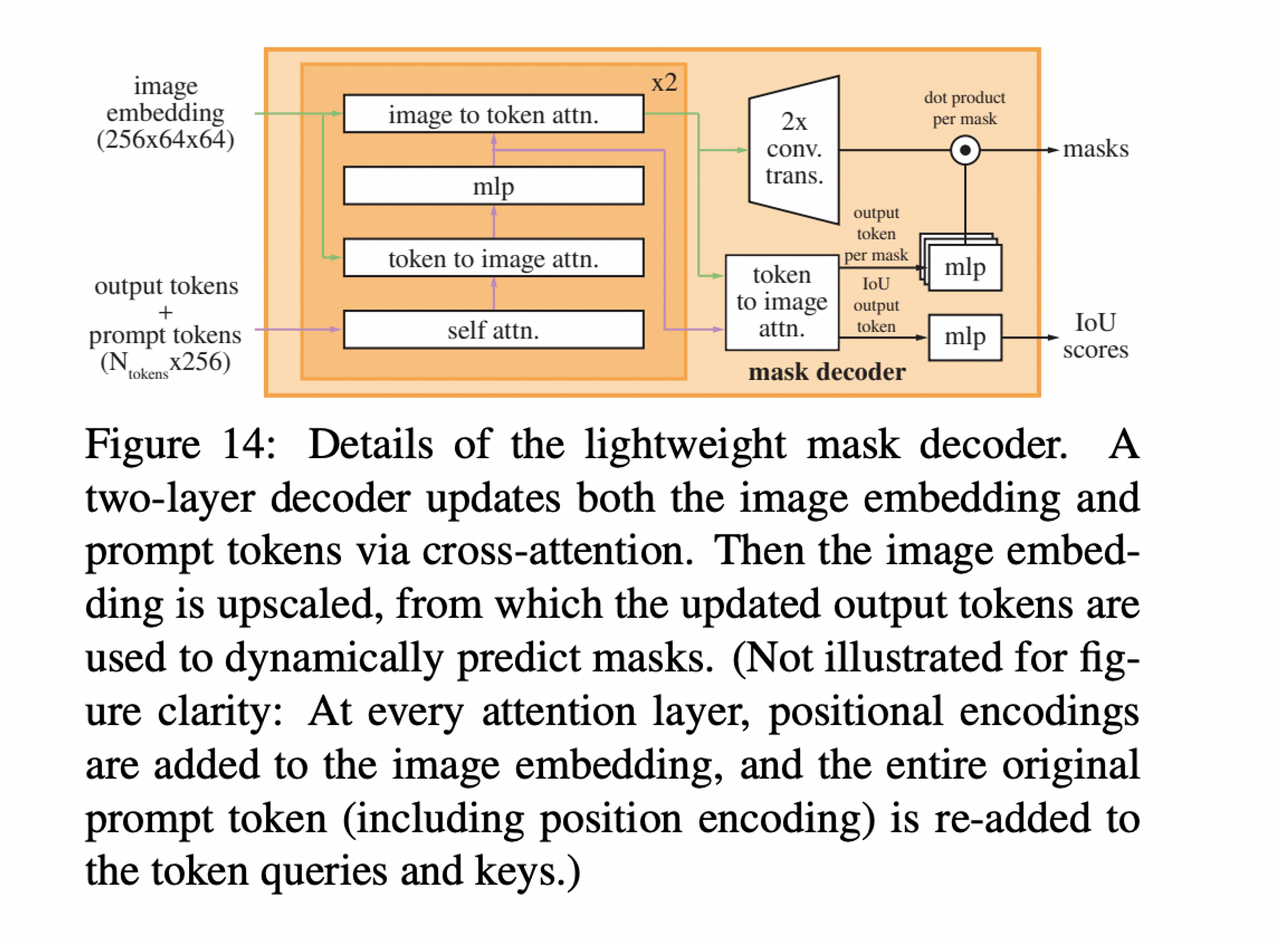
이미지 임베딩과 Prompt 임베딩 간의 cross attention 메커니즘을 적용해준 뒤, 마스크와 IoU를 리턴합니다. Cross attention 메커니즘의 세부 내용은 별도의 포스팅에서 리뷰합니다.
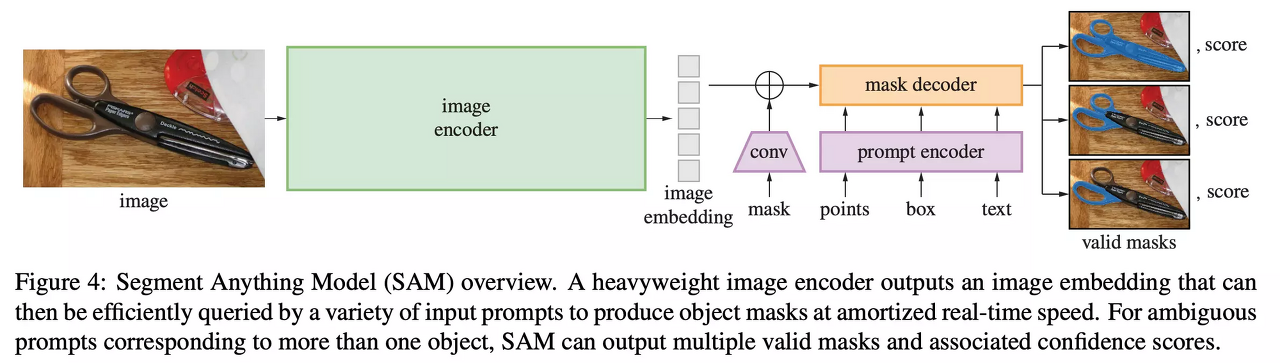
결국 SAM 모델은 하나의 prompt에 3개의 마스크를 생성, loss 계산, 3개의 마스크 중 가장 작은 loss만 backpropagation을 합니다. ( 3개의 이미지 가운데 ground truth가 가장 유사한 마스크에서만 역전파 )
이는 Ambiguity 라는 segmentation task의 기본 특성을 반영하기 위함입니다.
아래의 그림을 보면 같은 점이라도 사람을 의미하는지 , 가방을 의미하는지가 애매할 수 있습니다.
여러 마스크가 정답일 수 있어서 하나의 마스크 뿐만아니라 여러 마스크가 정답일 수도 있죠.

Experiments
원래 의도처럼 단일 task로 학습시킨 SAM 모델이 GPT처럼 학습하지 않았던 Task들을 잘 수행하는지 테스트를 한 결과입니다.
1. Single Point Segmentation : 점 하나를 찍고 해당 점에 해당하는 Object Segmentation task 입니다. SOTA 모델과 비교했을 때 모두 뛰어났습니다.

2. Zero-Shot Instance Segmentation : COCO와 LVIS 데이터셋에서 ViTDet과 SAM의 성능을 비교한 결과는 정량적으로 ViTDet에 보다 부족하지만, Human Rating에서는 더 좋은 결과를 얻었습니다.

3. Zero-Shot Text-to-Mask : Free-fromed Text로부터 Segmentation을 수행하는 Task 실험은 모델의 성능을 실험하기 위한 일종의 PoC (Proof of Concept)입니다.

이 밖에도 몇가지 디테일이 존재하는데 짧게만 설명하면
- The model was trained for 3-5 days on 256 A100 GPUs
- The image encoder takes ~0.15 seconds on an NVIDIA A100 GPU
- The prompt encoder and mask decoder take ~50ms on CPU in the browser using multithreaded SIMD execution
- The image encoder has 632M parameters
- The prompt encoder and mask decoder have 4M parameters