
우선 CNN
ViT는 비전 분야의 새로운 패러다임입니다.
기존의 비전 분야에서는 CNN을 사용했습니다. CNN은 필터가 움직이면서 전체의 이미지를 부분적으로 인식하게 되죠?
CNN은 한 번 연산시 국소적으로 이미지를 파악할 수 밖에 없습니다. ( 즉, 이미지 전체를 고려할 수 없습니다. )
따라서 한 번에 이미지를 고려할 수 있도록 'attention'기법을 사용합니다.
초기에는 cnn과 attention 을 합친 모델이 많이 연구되었습니다.
하지만 본 논문에 등장하는 ViT는 합성곱 연산을 사용하지 않고 attention만을 사용하여 모델을 구성합니다.
( 현재 ImageNet 분류 1, 2위 등극. 3~7위는 EffenNet CNN 기반 모델. )
CNN + attention
각 픽셀별로 중요한 정도를 나타내서 연산 → 가중곱 연산
전체 위치에 대한 각 픽셀의 중요도 ( ex. 10% 20% 60% 등 ) 를 표현하는 것이 attention.
( 중요한 부분은 더 큰 값을 곱하고 중요도가 낮을수록 더 낮은 값을 곱하는 방법 )
중요도를 어떻게 만드는지에 따라서 attention의 종류가 달라집니다.

Ex1. Bottlenet Attention Module(2018) 어텐션 기법
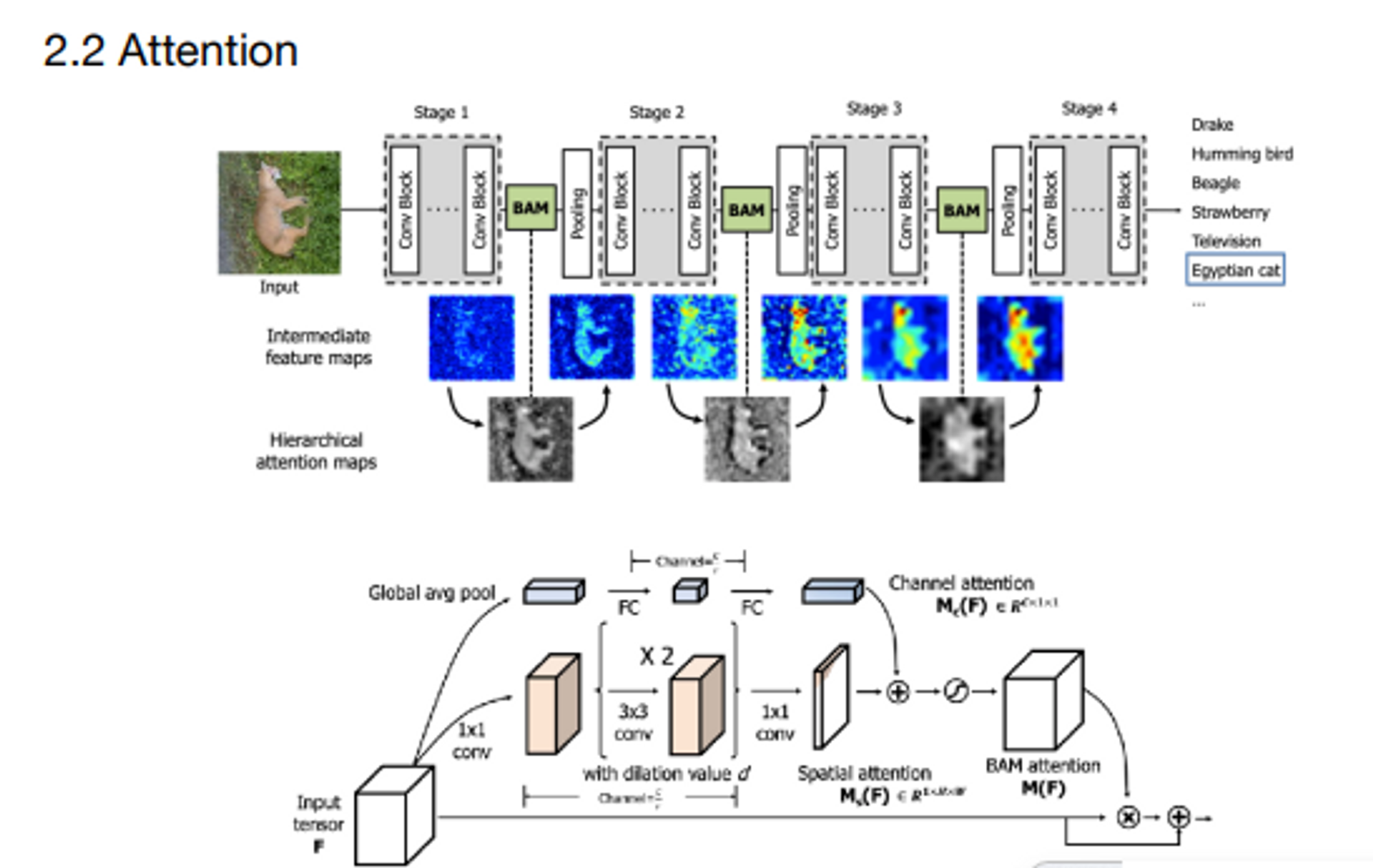
모듈의 집합을 하나의 스테이지라고 할 때, 각 스테이지가 끝난 후 어텐션을 계산하여 어느 부분이 중요한지 확인시켜줍니다.
아래의 인풋으로부터 어텐션이 계산이되고, 그림에서 각 stage마다 feature map이 개선되는 것을 확인할 수 있습니다.
중요한 부분은 명확하게 나타나고 중요하지 않은 부분은 어둡게 나타납니다.
그래서 attention을 어떻게 설계하는지가 중요합니다.
여기서는 feature의 넓이와 같은 output이 산출될 수 있도록 두 가지의 attention을 사용합니다.
- 이미지의 크기는 같지만 채널이 1개인 spatial attention을 사용.3x3 conv를 거쳐야 하니까 padding이 필요하겠죠? padding으로 크기를 유지해주면서 채널의 수를 줄여나갑니다.
- 1x1 conv 단계에서 한 장의 값이 나오도록 만들어줍니다.
- 1x1 conv을 거치면 이미지의 크기는 동일합니다.
- 채널 수와 동일한 channel attention을 사용.동일한 채널 수가 나오게끔 벡터를 만듭니다.
- 채널 방향으로 global avg pooling을 적용한 후에 Fully Connected Layer로 값을 재조정합니다.
channel attention 과 Spatial attention의 element-wise 합을 취해서 크기가 같은 값을 만듭니다.
→ 시그모이드 함수 적용하여 M(F)라는 값을 만듭니다.
→ M(F)의 값은 0~1사이가 되고 이 값이 Input과 곱해지면서 중요하지 않은 점은 0에 가까운 값이 되고 중요한 점은 1에 가까운 값이 됩니다.
→ 마지막에는 Residual learning을 이용하여 F + F * F(M)을 다음으로 넘겨주는 식을 사용했습니다.
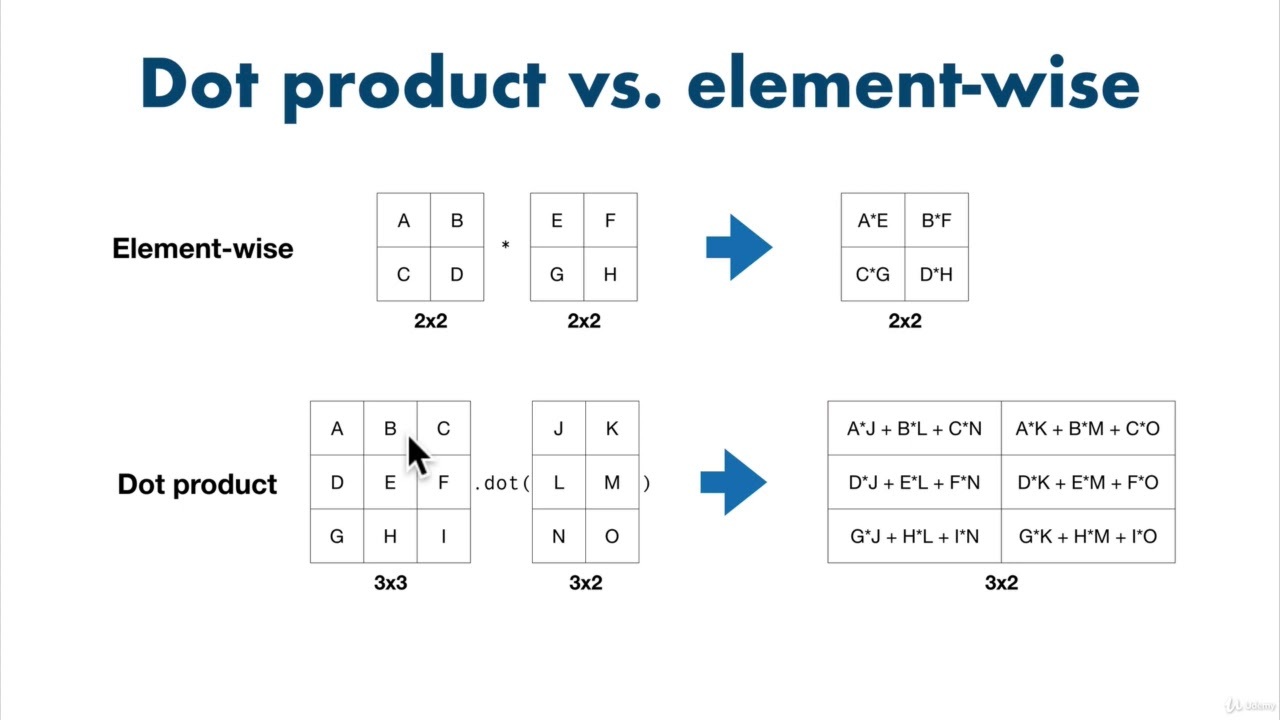
( element-wise는 성분끼리 계산한다는 의미입니다. )
Key , Query , Value
Key , query , value 는 데이터 베이스에서 나오는 개념.
f(x) → key 를 산출하는 함수
g(x) → query 를 산출하는 함수
h(x) → value 를 산출하는 함수
key 와 query의 유사도를 계산하기 위해 Q * K t ( transpose , 전치행렬 ) 을 계산한 후 softmax 함수를 적용시켜 0~1 사이의 값으로 나오도록 만들어서 attention map을 만들어요.
이 attention map에 value를 곱하면 당연히 0~1 순서대로 중요도가 클수록 높은 값이 나오도록 만들어지겠죠?
value 에서 어떤 녀석이 중요한지 덜 중요한지를 나타내는 것입니다.
최종적으로 어떤 연산을 거쳐서 ( 1x1 conv ) 산출되는 값이 어텐션을 고려하여 만들어진 값이라고 할 수 있겠죠 ?
Transformer - 트랜스포머 모델 구조

위의 그림은 트랜스포머의 구조입니다.
자연어 처리에서 지금까지 주를 이뤘던 모델은 LSTM이죠.
→ LSTM은 시퀀스 형태의 데이터를 받아 처리하기 때문에 순서를 고려하여 예측. 하지만 문장의 의미나 단어 간의 관계가 순차적이지는 않기 때문에 문장이 길어지면 순서만을 가지고 제대로된 번역을 할 수 없고, 각 단어간의 관계를 알 수 없습니다. 또한, 이전의 문장에서 번역 오류를 범한다면 다음 시퀀스에 안좋은 영향을 끼칩니다.

attention은 원래 보조적인 개념으로 사용되다가 attention만으로 이루어진 모델로도 충분히 좋은 성능을 낼 수 있다는 점이 증명되었습니다. 따라서 attention으로 구성된 transformer가 등장합니다.
인코더 - Encoder
transformer 모델은 input을 처리하는 인코더와 output을 출력하는 디코더로 크게 두 파트로 구성되어있습니다.
가장 큰 특징은 input이 통째로 들어간다는 것입니다.

위의 그림에서 input embedding + positional encoding 이후 multi-head attention으로 가는 단계에서 화살표 세 개가 있는데요, 이는 각각 key query value를 의미합니다.
multi-head attention이라는 의미 자체가 attention을 여러개 사용한다는 의미입니다.
그 이유는 학습에 따라서 어텐션들이 같은 부분을 처리하더라고 다른 관점에서 정보를 처리할 수 있기 때문입니다. 다수의 attention을 구해서 그 내용을 종합하겠다는 의미입니다.
여러 개의 어텐션들을 합쳐서 나온 값을 이전 값이랑 더하고( Residual learning) 정규화(layer norm)를 해줍니다.
그 이후에 MLP 형태인 Feed Forward를 거쳐서 다시 이전 값이랑 더하고 정규화를 거칩니다.
여기서 중요한 점은 들어오는 데이터의 크기와 나가는 데이터의 크기가 같습니다.
→ 즉, 인코터 레이어를 여러개 붙일 수 있다는 것입니다. 실제로 논문에서는 6개의 레이어를 사용합니다. 그래서 6개의 레이어를 사용하여 나온 출력값을 사용하게 됩니다.
디코더
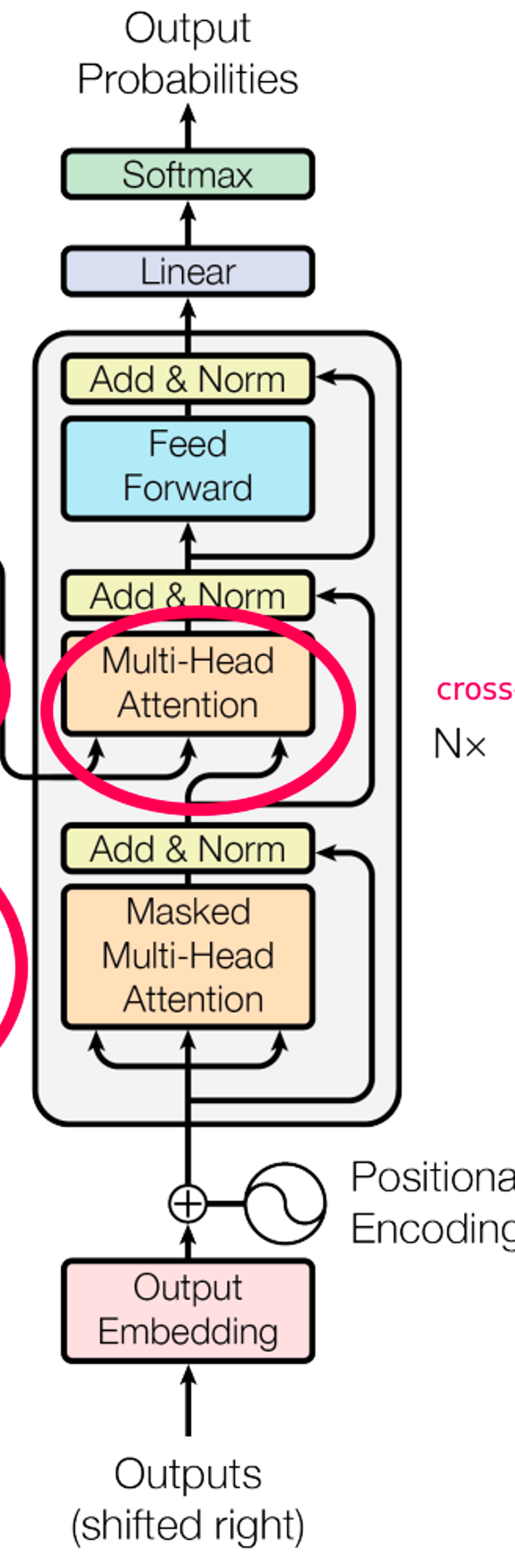
디코더도 마찬가지로 입력한 크기와 아웃풋의 크기가 같기 때문에 층을 여러개로 쌓을 수 있습니다.
( 여기에서도 레이어를 6개 사용함 )
다만 다른 점은 한 층에 어텐션을 두 개 사용했다는 것입니다.
먼저 target 문장에 대한 정보를 받아옵니다. 항상 transformer는 학습을 할 때 paired 된 데이터를 받습니다.
예를 들어, 한글-영어로 가정한다면 인풋에는 ‘ 나는 학생입니다 ‘ 라는 문장이 들어옵니다.
그렇다면 이 문장은 앞서 본 input embedding 과정에서 봤던 것처럼 문장을 벡터화를 하고 input embedding 을 거쳐 적절한 크기의 matrix를 만드는 단계를 거칩니다.
output도 마찬가지이죠. ‘나는 학생입니다’에 대응하는 ‘i’m a student’라는 문장을 똑같은 과정으로 matrix를 만들어주고 positional encoding을 통해 학습할 수 있는 형태로 만들어줍니다.
위의 그림에서 input과 다른 Masked multi-head attention이 존재합니다.
Masked의 원활한 이해를 돕기 위해서 앞서 사용한 ‘나는 학생입니다’라는 문장을 예로 설명해볼게요.
‘나는 학생입니다’라는 인풋으로 ‘I’m a student’라는 아웃풋이 나오도록 학습을 해야합니다.
‘나는 학생입니다’ 문장은 matrix 형태로 존재하고 이를 바탕으로 I 를 먼저 만들어냅니다.
이후 input matrix를 활용하여 am이 오는 것을 맞추고 그 다음에 a , student 순서대로 다음에 어떤 단어가 오는지 맞추는 과정을 거칩니다.
즉, 현재 I 라는 단어를 예측한다면 뒤의 정보 ( 'm a student ) 는 사용하면 안된다는 것입니다.
만약 뒤의 정보를 사용하게 된다면 ‘I’m a student’라는 정보를 다 가지고 학습을 진행하는 것이기 때문에 cheating이 되는 것이죠.
현재 위치 기준으로 뒷 부분은 attention이 적용되지 않도록 마스킹을 해주는 것입니다.
그래서 masked multi head attention을 거쳐서 이전에 나온 값을 더해주고 정규화를 합니다.
그 다음은 이 부분입니다.

한글에서 영어로 바꾸는 작업을 해줘야 하기 때문에 Encoder에 있는 값을 받아서 번역을 요청하는 것입니다.
KEY-VALUE를 Encoder에서 얻는 값으로 출력을 합니다. 그리고 Decoder에서 얻은 값을 query로 이용하게 됩니다.
이전에 언급했듯이 정보를 요청하는 것이 query의 역할입니다.
주어진 데이터에 접근을 하여 유사성을 계산하는 것이기 때문에 key query value가 이런 식으로 들어오게 됩니다.
그래서 ‘나는 학생입니다’에 대한 주어진 데이터셋이 key-value 값이 되는 것이고, 영어로 요청된 정보가 query 값이 되는 것이죠.
여기서 중요한 점은 매 층마다 encoder에 있는 정보를 사용하겠다는 것입니다.
이후 이전 과정과 동일하게 이전 값을 더해주고 정규화합니다.
이 부분을 6회 반복합니다.
최종적으로 linear를 통해서 우리가 번역하고자 하는 언어에서 알고있는 단어의 개수만큼 노드를 생성해줍니다.
예를 들어 10000개의 영어 단어를 번역하고자 한다면 마지막에는 10000개의 노드를 갖는 output값이 나오게 됩니다.
( ex. [0,0,1,1,0 …. ] )
그리고 softmax를 통해서 각 노드의 확률 계산을 하는 것입니다.
( ex. [0.8, 0.1, 0, …] )
따라서 가장 높은 확률을 기준으로 해서 단어 세트를 가져오게 되는 것입니다.
( I am a student 문장의 각각의 단어 예측 )
Summary
- 데이터는 항상 paired 데이터를 사용 ( 한글 - 영어, 영어 - 프랑스어 등 ) , 각 단어마다 one-hot 벡터로 표현됩니다.
- input embedding을 통해서 우리가 원하는 dimension으로 만들어 줄 수 있다. 그 다음 posional encoding 이라는 matrix를 만들어서 더해줍니다.
- 위의 값을 통해 key query value 값으로 attention을 구합니다. 여기서 attention을 여러번 구하여 종합적으로 판단. ( 이전 값 더하고 Normalization )
- Normalization은 학습 속도를 높이기 위해서 사용.
- 다시 Feed Forward를 통하여 이전 값을 더하고 정규화.
- decoder도 거의 비슷하지만 masked multi-head attention을 사용
- Encoder에서 얻은 한글로 key-value 값을 얻고 영어를 query로 사용.