
https://minyoungxi.tistory.com/51
ViT의 장점
- transformer 구조를 거의 그대로 사용하기 때문에 확장성이 좋음
- large 스케일 학습에서 매우 우수한 성능을 보임
- transfer learning 시 CNN보다 훈련에 더 적은 계산 리소스를 사용
ViT의 단점
- inductive bias의 부족으로 인해 CNN보다 데이터가 많이 요구
- inductive bias → 학습자가 처음보는 입력에 대한 출력을 예측하기 위해 사용하는 일련의 가정(assumption)
- CNN은 입력에 대한 출력을 예측하기 위해 대표적으로 translation equivariance와 locality를 가정합니다.
- locality는 합성곱 연산을 할 때, 특정 영역만 보고 그 안에서 특징을 추출할 수 있다는 것을 가정한 것. 입력에 대해서 출력을 예측하기 위해 하나의 가정을 만든게 합성곱 연산.
- translation equivariance는 입력이 변하면 출력도 변해서 나옴..
translation equivariance
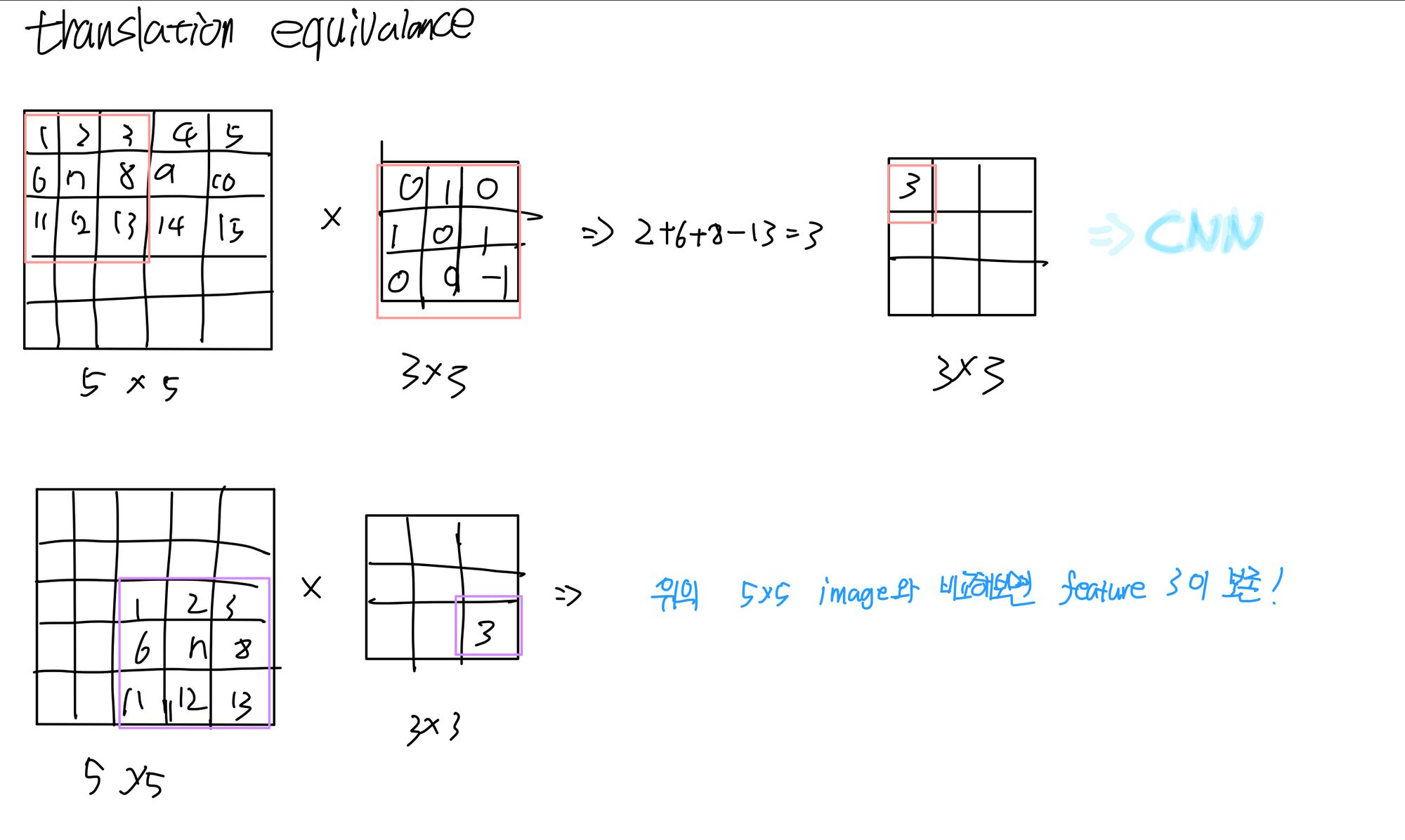

** 이처럼 CNN은 강력한 inductive bias를 가지고 있다. 하지만 transformer 같은 경우에는 attention만 사용하는데, attention 개념 자체가 전체를 보고 어디가 어떤 특성을 갖고 있는지 말해주는 구조이기 때문에 어디를 어떻게 조정해야 하는지에 대한 가정이 부족하다보니 그 패턴을 전체적인 부분을 데이터에서 찾기 때문에 CNN보다 더 많은 데이터가 필요합니다.**
예를 들어, 중간 사이즈인 이미지넷을 강한 정규화 없이 학습에 사용할 경우 유사한 크기의 ResNet보다 성능이 낮음.
하지만 large scale에서 학습을 했더니, 강한 inductive bias를 가진 cnn을 능가한다는 것을 확인.
충분한 scale에서 사전 학습을 하고 전이하는 방법을 채택했더니 전이 학습 속도와 정확도가 CNN보다 높았습니다.
Vision Transformer ViT - 구조
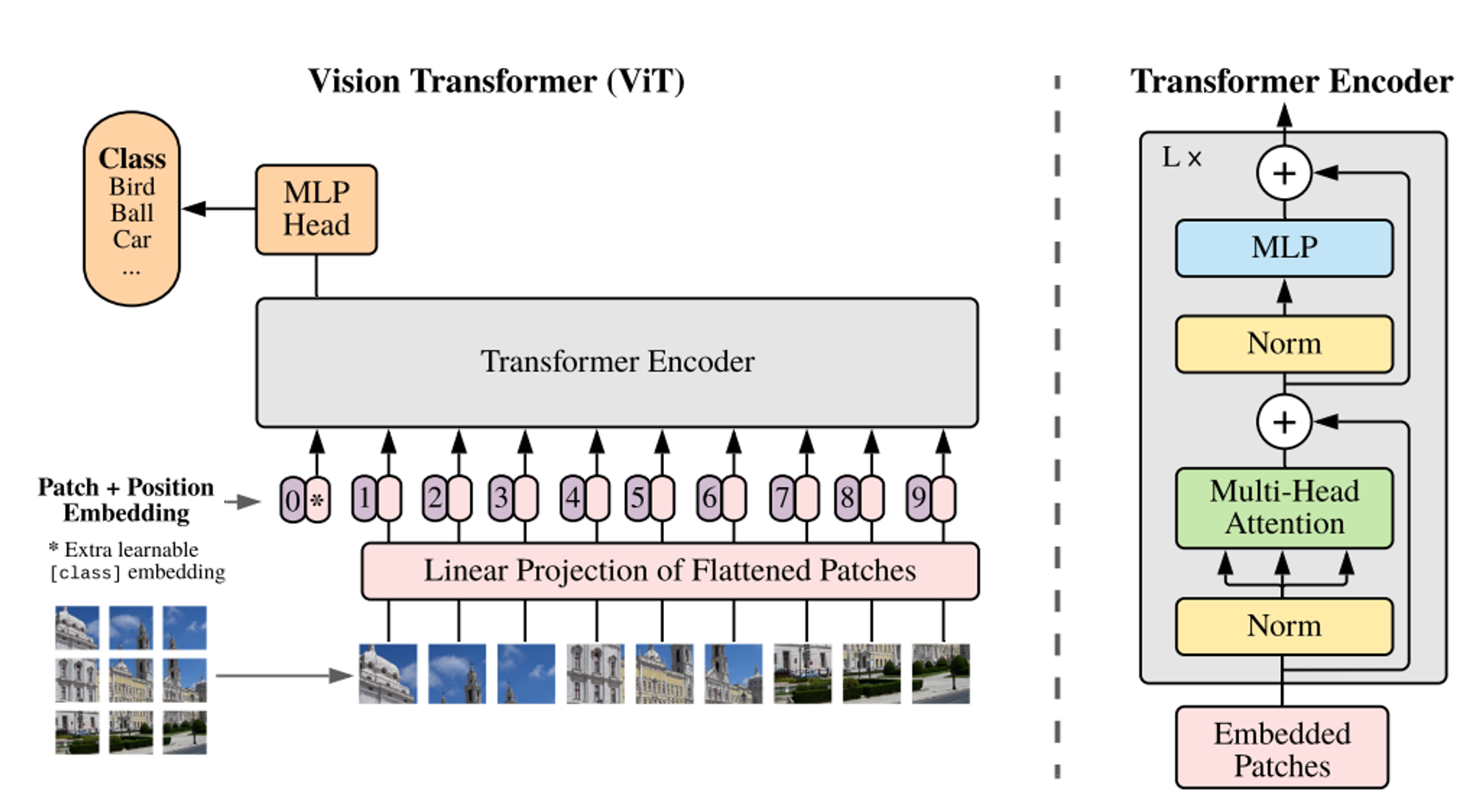
Transformer Encoder를 가져와서 학습을 진행합니다.
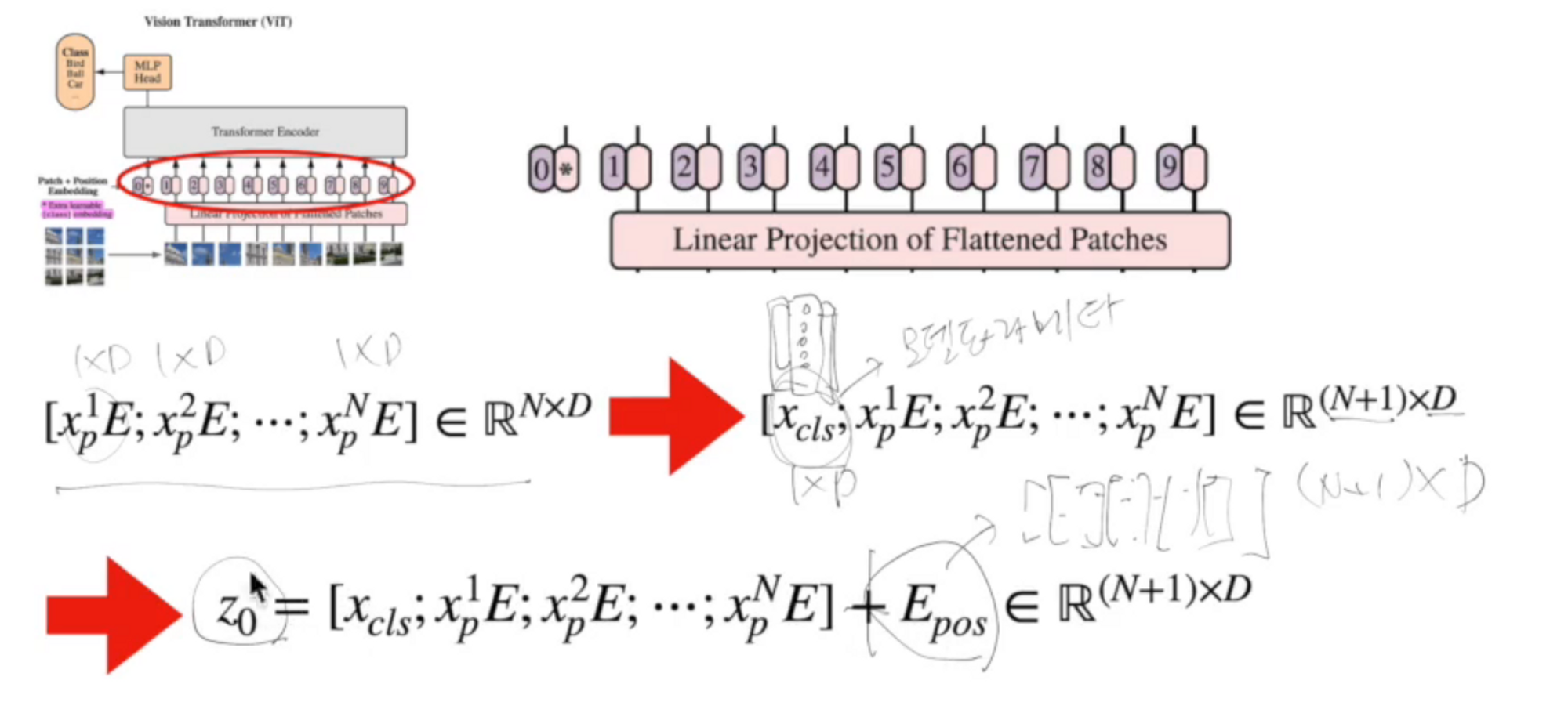
따라서 Transformer에 맞는 input 값을 넣어줘야겠죠?
이미지를 잘게 자르는데 각 조각을 patch라고 합니다.
patch는 사각형 형태인데 우리가 transformer를 배울 때, 벡터 형태로 인풋이 들어갔으니 벡터로 바꿉시다.
Linear Projection of Flattened Patches는 조각들을 평평하게 펴서 Linear 과정을 통해 Embedding 과정을 한 번 거칩니다.
Linear 과정을 거친 벡터들에게 클래스를 예측할 수 있는 클래스 토큰을 추가해주고 Positional Embedding 을 더해주면 Transformer의 input data 완성 (Positional Embedding은 잘린 이미지 조각들의 위치가 중요하기 때문에 반드시 해줘야 합니다 )
오른쪽의 그림처럼 Transformer Encoder에 들어간 데이터들은 L번 반복 학습을 하게 됩니다.
계산된 부분의 클래스 토큰만 떼서 MLP head에 넣습니다. ( 클래스의 개수 = 노드의 개수 )
학습은 cross entropy 사용.
단계별로 자세히
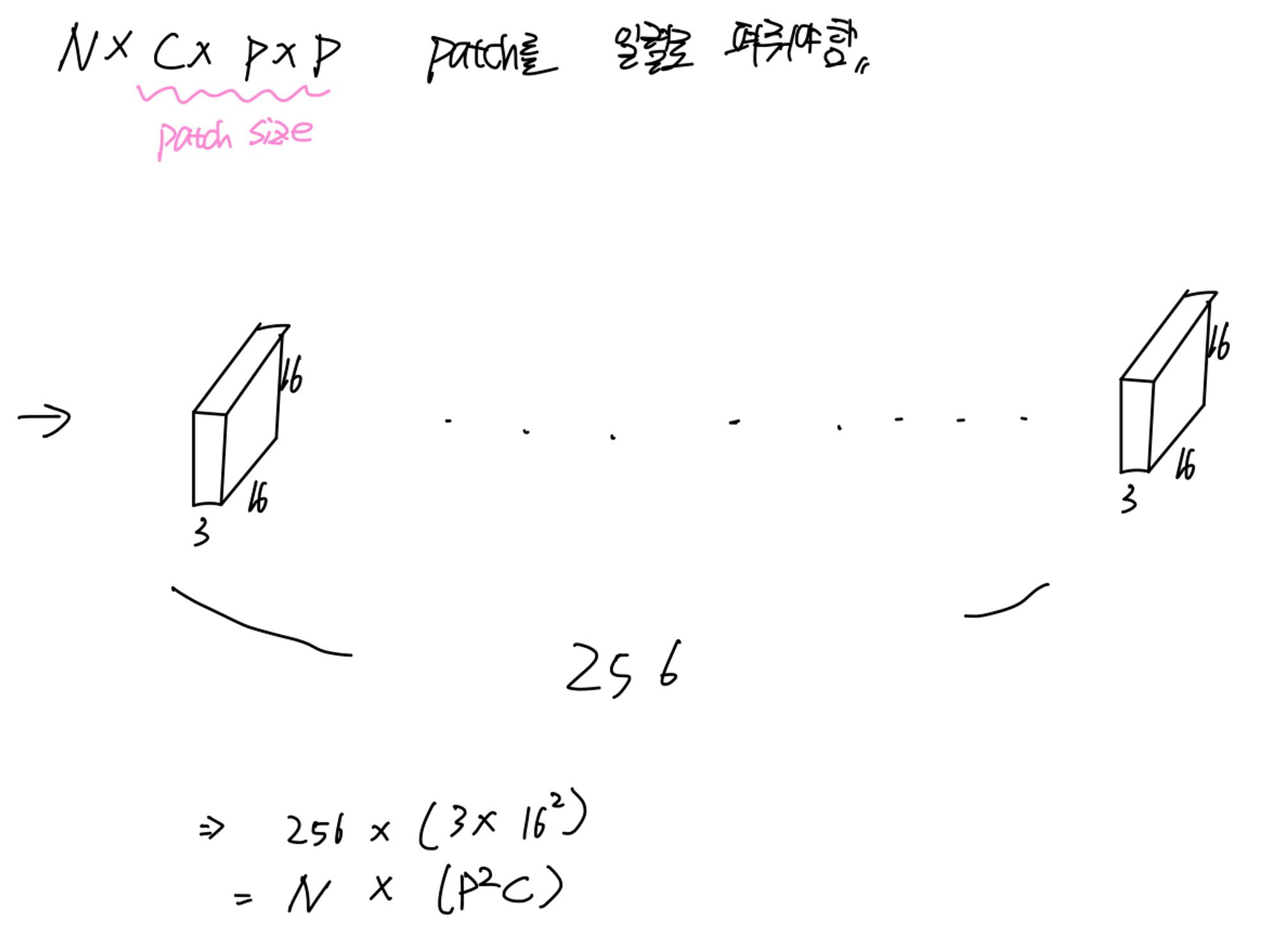
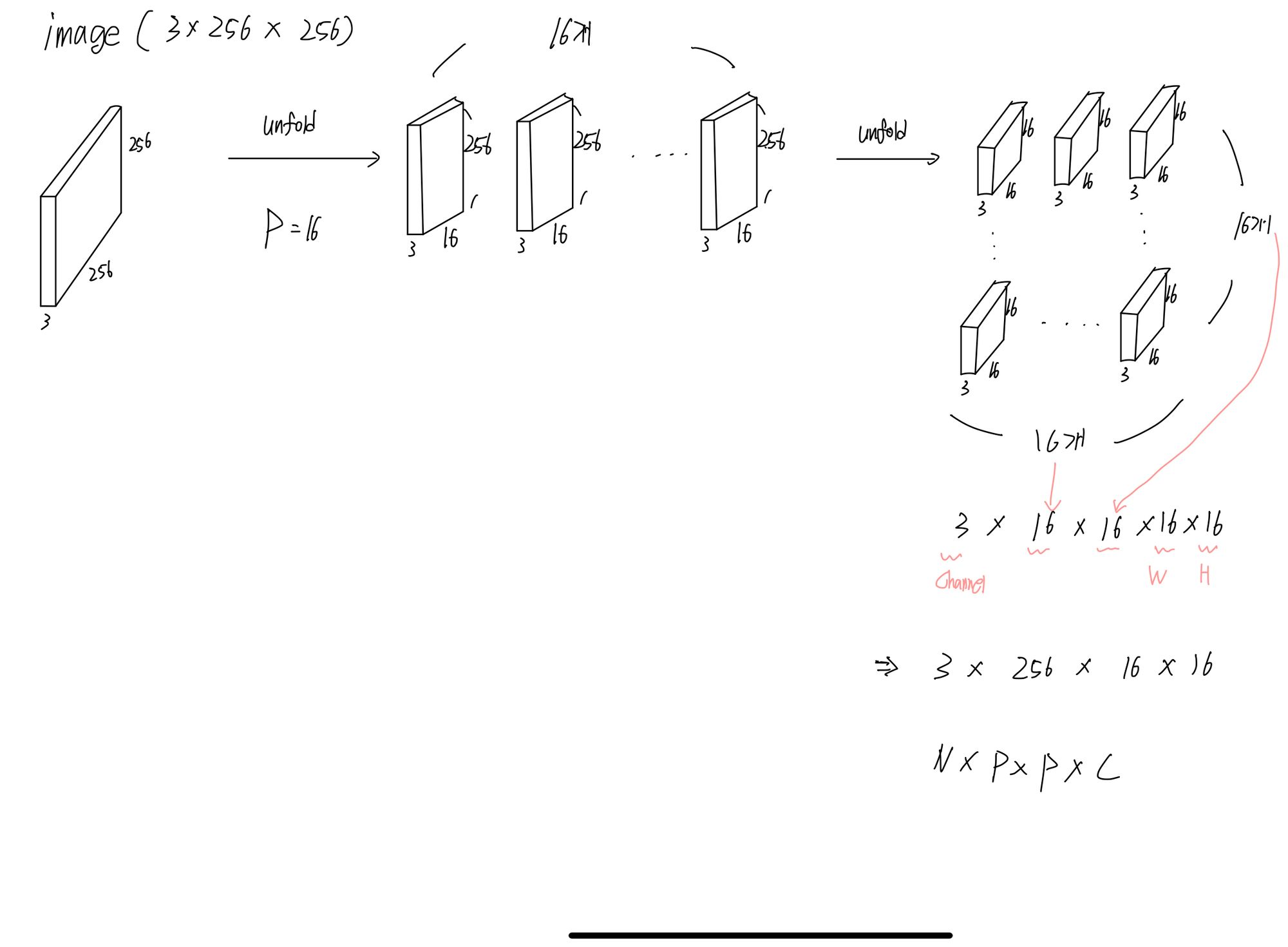
Patch 나누기
이미지는 ( Channel * height * Width ) = 3차원입니다.
아래의 식에서 P는 patch의 크기입니다. ( patch 하나당 p * p * c) * N ( patch의 개수 )
- Decoder도 거의 비슷하지만 masked multi-head attention을 사용합니다.
- Encoder에서 얻은 한글로 key-value 값을 얻고 영어를 query로 사용합니다.
- Linear를 통해서 번역하고자 하는 언어에서 이해할 수 있는 단어의 개수만큼 노드를 생성합니다.

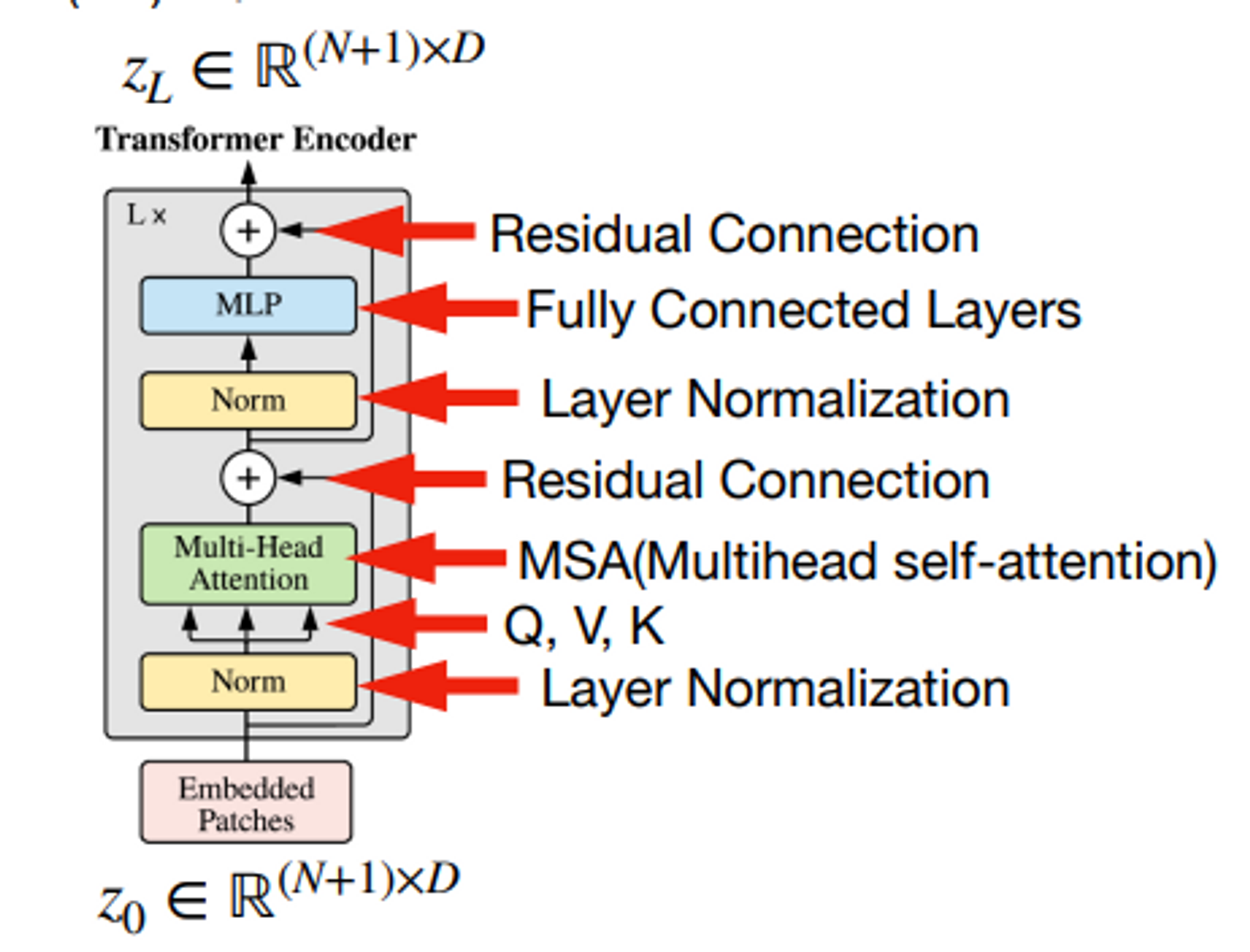
기존의 transformer와 다른 점은 정규화를 먼저 거친 후에 multi-head attention을 수행한다는 점입니다.

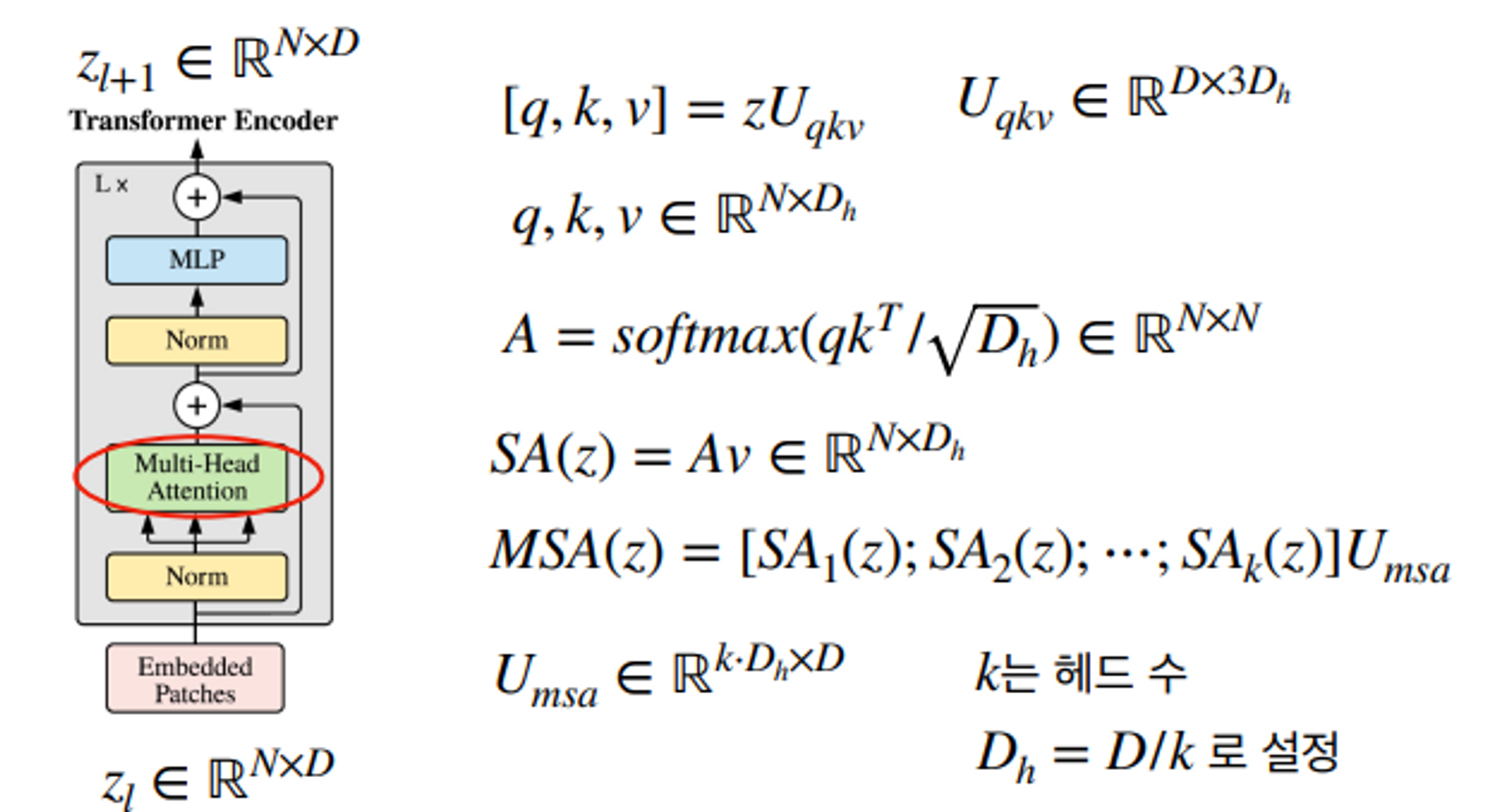
Multi-Head Attention 에서는 key query value를 구합니다.
학습 결과
ViT - 학습
- large dataset으로 사전학습 후 더 작은 데이터셋에 대해 fine-tuning 하는 방식 ( 이미지 resize 및 MLP 헤드 부분을 클래스 수에 맞게 교체 )
- pytorch에서 제공하는 resnet은 imagenet으로 pre-trained 된 모델이라서 마지막의 아웃풋 노드의 개수가 1000개가 됩니다. 만약에 CIFAR10에 대해서 그 모델을 사용하고 싶다면 마지막의 노드를 10개로 바꿔줍니다.
- 학습을 위해 large 데이터셋인 ImageNet , ImageNet-21k, JFT 사용 ( 비교 )
- 전처리는 Resize, RandomCrop, RandomHorizontalFlip 사용
- 광범위하게 Dropout 적용 ( qkv - prediction 부분 제외 → 온전히 attention )
- 아래 데이터셋에 전이학습 진행 ( ImageNet, CIFAR10/100, 9-task VTAB 등 )
학습 조건
- Optimizer : ADAM
- 스케줄링 : linear learning rate decay
- step10을 정해줍니다. 예를 들어 epoch1~10 에서는 learning rate를 10의 -5제곱을 사용, 10~20에서는 -3제곱 등등
- weight decay : 0.1
- 배치 사이즈 : 4,096
- Label smoothing 사용
- validation accuract 기준 early- stopping
Fine-Tuning 조건
- Optimizer : SGD 모멘텀
- 스케줄링 : cosine learning rate decay
- weight decay : 미적용
- grad clipping 적용
- 배치 사이즈 : 512
- Resize 적용 ( ImageNet : 512 for ViT-L/16 and 518 for viT-H/14 나머지는 384)


RGB embedding filters → 비전 트렌스포머에서 봤을 때, 가장 첫번째 레이어.
고차원에서 저차원으로 projection을 시킨 것입니다. = N * (P2C) → N * D
각 패치의 미세 구조의 저차원 표현.
노란색 부분은 positional embedding.
mean attention distance → layer가 깊어질수록 object에 집중해서 본다는 것을 확인할 수 있음. ( CNN과 유사 )


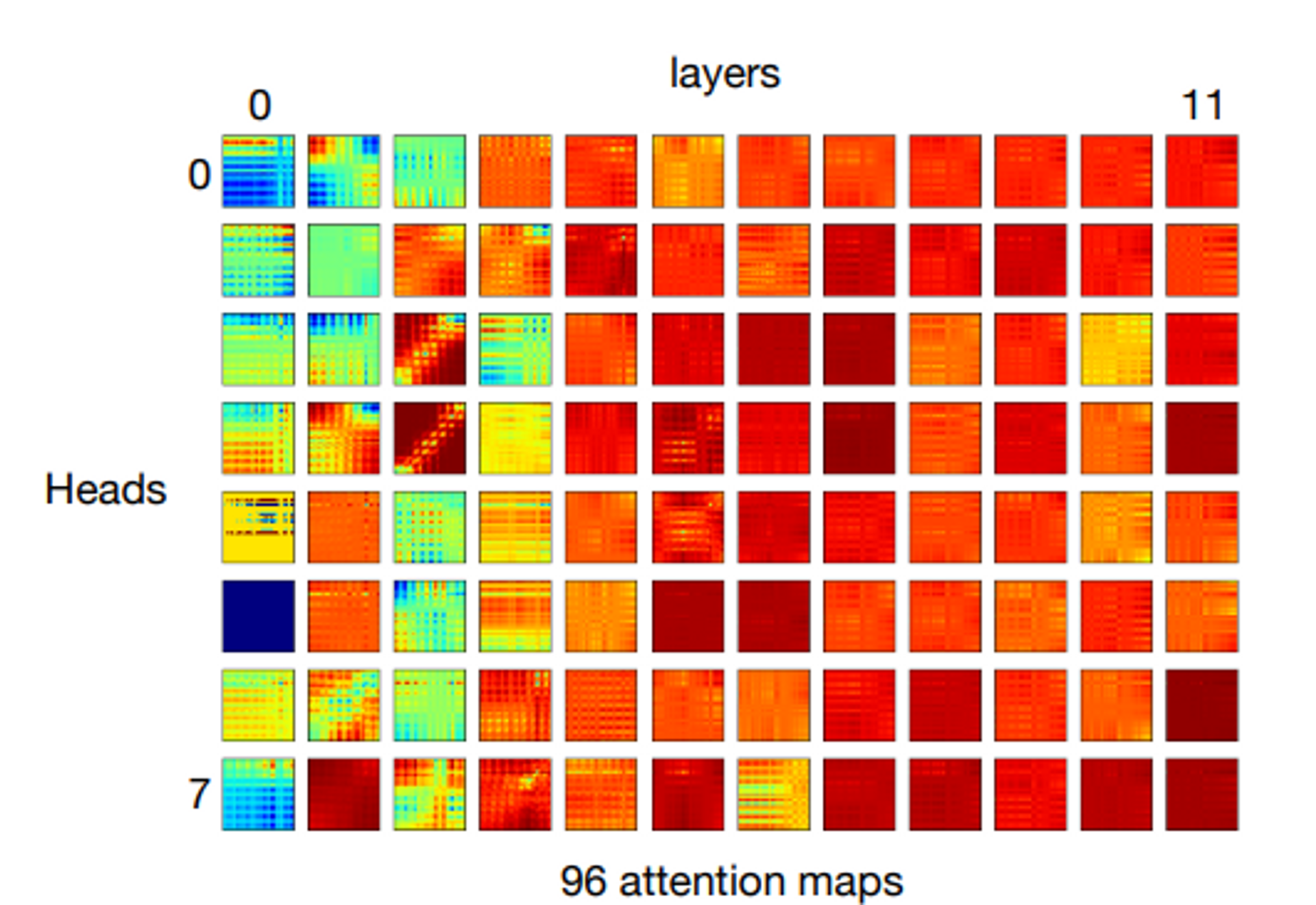

각 헤드마다 보는 부분이 다름.