
https://minyoungxi.tistory.com/39
Kaggle - 호텔 예약 데이터 분석 및 모델링 1 ( Hotel Reservation )
https://www.kaggle.com/datasets/ahsan81/hotel-reservations-classification-dataset Hotel Reservations Dataset Can you predict if customer is going to cancel the reservation ? www.kaggle.com Hotel Reservations 온라인 예약 플랫폼을 통해서 예약
minyoungxi.tistory.com
지난 포스팅에 이어서 Hotel Resevation 데이터 세트로 남은 시각화를 해보고
머신러닝 모델 여러가지를 실습해 봅시다.
지난 포스팅에서는 데이터를 간단하게 EDA 해보고
컬럼별로 시각화를 진행했는데요 , 이번에도 나머지 컬럼들을 시각화하고 조금 더 복잡한 그래프를 그려보겠습니다.
데이터 시각화 - Visualization
https://minyoungxi.tistory.com/34
[Data Visualization] 시각화 연습 - Netflix Data Visualization
Dataset - Kaggle 의 netflix_titles.csv 데이터 세트 https://www.kaggle.com/code/joshuaswords/netflix-data-visualization Netflix Data Visualization Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources www.
minyoungxi.tistory.com
https://minyoungxi.tistory.com/36
[Data Visualization] 시각화 연습 - Netflix Data Visualization 2
오늘은 위의 그래프를 만들어 볼 것입니다. 흠 우선 이번에도 matplotlib 의 subplots를 사용해보면 좋겠네요. 상위 3개의 국가 그래프에는 빨간색을 칠해야하고 각 그래프의 위쪽에는 해당 국가의 컨
minyoungxi.tistory.com
위는 데이터 시각화를 위한 참고 자료입니다 :)
월별 예약 빈도를 확인하기 위해서 'arrival_month' 컬럼을 groupby로 묶어줬습니다.
아래는 .agg()에 적용가능한 통계 함수를 정리해둔 표입니다.
.agg() 에 적용할 수 있는 통계함수 문자열 표
| count | 데이터의 개수 |
| sum | 합계 |
| mean | 평균 |
| median | 중앙값 |
| var, std | 분산, 표준편차 |
| min, max | 최소, 최대값 |
| unique, nunique | 고유값, 고유값 개수 |
| prod | 곲 |
| first, last | 첫째, 마지막값 |
우리는 월별 예약 횟수를 세어 보는 것이 중요하므로 agg(['count']) 를 통하여 횟수를 세어줍니다.
그리고 .sort_values() 를 통하여 내림차순 정리를 해줍니다.
결과를 파이차트로 나타내면 아래와 같은 그래프를 그릴 수 있습니다.
그럼 지난 포스팅과 현재 월별 예약 횟수를 통해서 얻을 수 있는 인사이트를 정리해보고 다음 단계로 넘어가겠습니다.
df.groupby('arrival_month')['Booking_ID'].agg(['count']).sort_values(by='count', ascending=False).plot(kind='pie',subplots=True,
autopct="%1.2f%%",
figsize=(7,7))
Insight
1. 대부분의 예약은 2인과 성인들이 많음.
2. 아이들은 0명인 경우가 대부분이고 , 방을 예약하는 기간이 짧음.
3. 월별 예약 횟수를 보면 여름 예약량이 많음.
4. meal_plan_1 을 대부분 선택하며, 주차장을 요구하지 않은 손님들이 더 많음
상관 관계 분석 ( correlation )
correlation = df.corr().round(2)
plt.figure(figsize=(8,8))
sns.heatmap(correlation, annot=True, cmap = 'YlOrBr')상관 관계를 한 눈에 보기 쉽게 시각화 할 때는 seaborn 패키지에 있는 히트맵을 사용합니다.
annot=True 로 해주셔야 상관 계수가 나타나니 꼭 설정해주세요 .

이번에는 시각화를 할 때 가장 많이 사용되는 subplot 을 사용하겠습니다.
아래의 코드는 매우 길지만 모두 비슷한 형태로 코드를 짤 수 있습니다.
subplot은 여러 개의 plot들을 한 캠퍼스 안에 그릴 수 있어서 한 눈에 여러 그래프를 비교할 수 있습니다.
우리의 데이터셋처럼 컬럼이 많을 경우 subplot을 사용합니다.
plt.sublplot(4,2,1) = 4행 2열 중 첫 번째 칸에 그래프를 그리겠다. 이런 의미입니다.
plt.gca() 의 경우 Axes 객체를 반환합니다. 각 Axes 객체마다 set_title을 통해 그래프에게 제목을 달아줬습니다.
plt.figure(figsize = (20,25))
plt.subplot(4,2,1)
plt.gca().set_title('Variable no_of_adults')
sns.countplot(x = 'no_of_adults', palette = 'Set2', data = df)
plt.subplot(4,2,2)
plt.gca().set_title('Variable no_of_children')
sns.countplot(x = 'no_of_children', palette = 'Set2', data = df)
plt.subplot(4,2,3)
plt.gca().set_title('Variable no_of_weekend_nights')
sns.countplot(x = 'no_of_weekend_nights', palette = 'Set2', data = df)
plt.subplot(4,2,4)
plt.gca().set_title('Variable no_of_week_nights')
sns.countplot(x = 'no_of_week_nights', palette = 'Set2', data = df)
plt.subplot(4,2,5)
plt.gca().set_title('Variable type_of_meal_plan')
sns.countplot(x = 'type_of_meal_plan', palette = 'Set2', data = df)
plt.subplot(4,2,6)
plt.gca().set_title('Variable required_car_parking_space')
sns.countplot(x = 'required_car_parking_space', palette = 'Set2', data = df)
plt.subplot(4,2,7)
plt.gca().set_title('Variable room_type_reserved')
sns.countplot(x = 'room_type_reserved', palette = 'Set2', data = df)
plt.subplot(4,2,8)
plt.gca().set_title('Variable arrival_year')
sns.countplot(x = 'arrival_year', palette = 'Set2', data = df)
plt.figure(figsize = (20,25))
plt.subplot(3,2,1)
plt.gca().set_title('Variable arrival_month')
sns.countplot(x='arrival_month', palette='Set2', data=df)
plt.subplot(3,2,2)
plt.gca().set_title('Variable market_segment_type')
sns.countplot(x='market_segment_type', palette='Set2', data= df)
plt.subplot(3,2,3)
plt.gca().set_title('Variable repeated_guest')
sns.countplot(x = 'repeated_guest', palette = 'Set2', data = df)
plt.subplot(3,2,4)
plt.gca().set_title('Variable no_of_previous_cancellations')
sns.countplot(x = 'no_of_previous_cancellations', palette = 'Set2', data = df)
plt.subplot(3,2,5)
plt.gca().set_title('Variable no_of_special_requests')
sns.countplot(x = 'no_of_special_requests', palette = 'Set2', data = df)
plt.subplot(3,2,6)
plt.gca().set_title('Variable booking_status')
sns.countplot(x = 'booking_status', palette = 'Set2', data = df)
연속형 변수
1. 연속형 변수 값들을 보면 일반적으로 예약하는 시간이 길면 예약은 줄어드는 것을 알 수 있습니다.
2. 우리의 데이터의 상위는 보통 100유로의 평균 가격을 보여줍니다.
3. 손님들은 보통 예약을 취소하지 않습니다.
plt.figure(figsize=(25,20))
sns.set(color_codes=True)
plt.subplot(2,2,1)
sns.histplot(df['lead_time'], kde=False)
plt.subplot(2,2,2)
sns.histplot(df['arrival_date'], kde=False)
plt.subplot(2,2,3)
sns.histplot(df['avg_price_per_room'], kde=False)
plt.subplot(2,2,4)
sns.histplot(df['no_of_previous_bookings_not_canceled'], kde=False)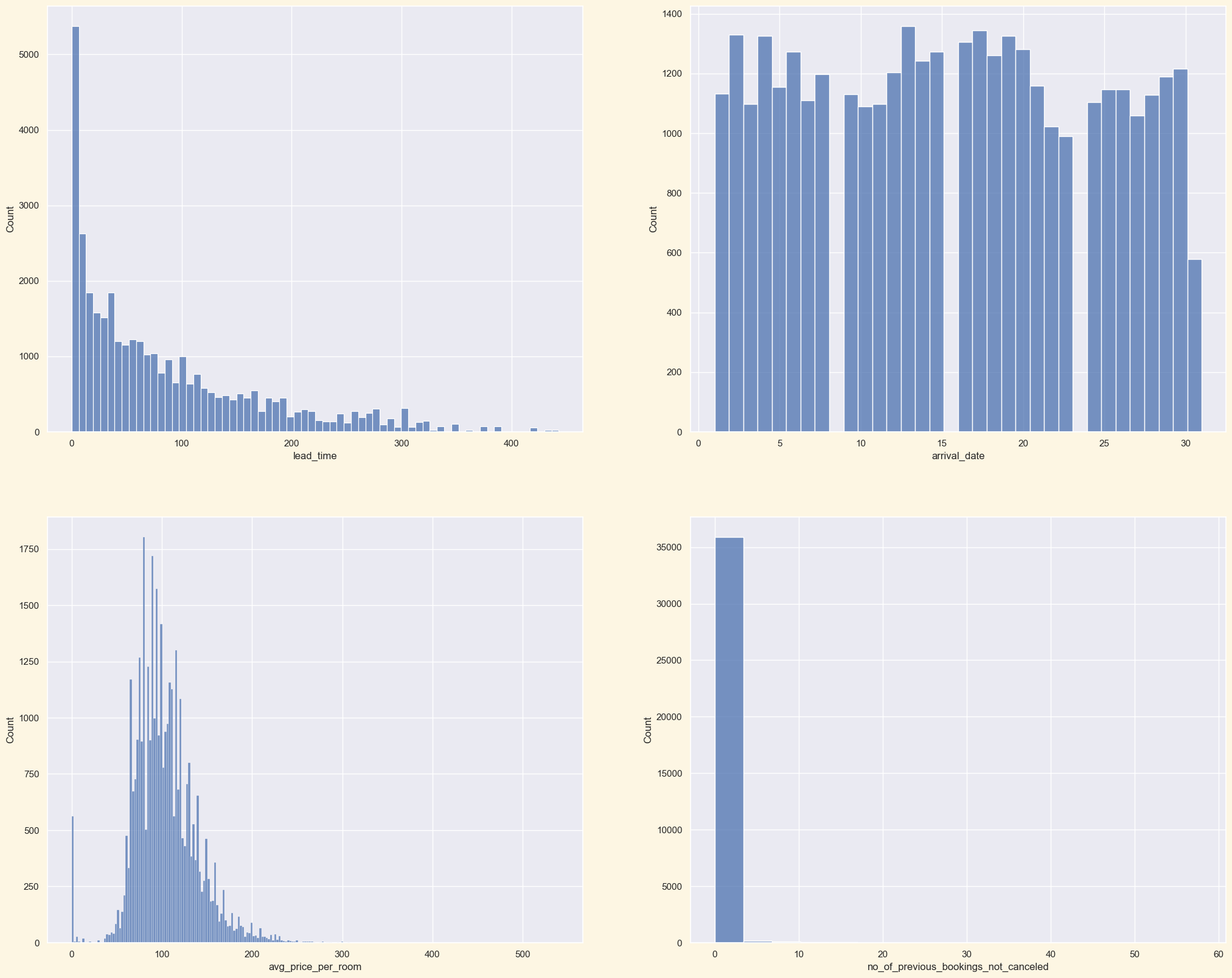
이변량 분석
* 우리의 타겟 변수를 보면, 인사이트를 얻을 수 있다.
* 일반적으로 주자창을 요구하는 손님, 이전에 묵었던 적이 있는 손님, 특별 요청을 하는 손님은 취소 가능성이 적다.
* 여기에서 볼 수 있는 가장 큰 왜곡은 Lead_Time 변수입니다. 사람이 방을 예약하는 데 시간이 오래 걸릴수록 예약을 취소할 가능성이 높아집니다. 약간의 경사에도 불구하고 일반적으로 취소가 적습니다. 더 비싼 객실도 더 많은 취소가 발생할 수 있음을 알 수 있습니다.
plt.figure(figsize = (20, 25))
plt.suptitle("Analysis Of Variable booking_status",fontweight="bold", fontsize=20)
plt.subplot(5,2,1)
sns.countplot(x='booking_status', hue='no_of_adults', data=df, palette='Set2')
plt.subplot(5,2,2)
sns.countplot(x = 'booking_status', hue = 'no_of_children', palette = 'Set2', data = df)
plt.subplot(5,2,3)
sns.countplot(x = 'booking_status', hue = 'no_of_weekend_nights', palette = 'Set2', data = df)
plt.subplot(5,2,4)
sns.countplot(x = 'booking_status', hue = 'market_segment_type', palette = 'Set2', data = df)
plt.subplot(5,2,5)
sns.countplot(x = 'booking_status', hue = 'type_of_meal_plan', palette = 'Set2', data = df)
plt.subplot(5,2,6)
sns.countplot(x = 'booking_status', hue = 'required_car_parking_space', palette = 'Set2', data = df)
plt.subplot(5,2,7)
sns.countplot(x = 'booking_status', hue = 'room_type_reserved', palette = 'Set2', data = df)
plt.subplot(5,2,8)
sns.countplot(x = 'booking_status', hue = 'arrival_year', palette = 'Set2', data = df)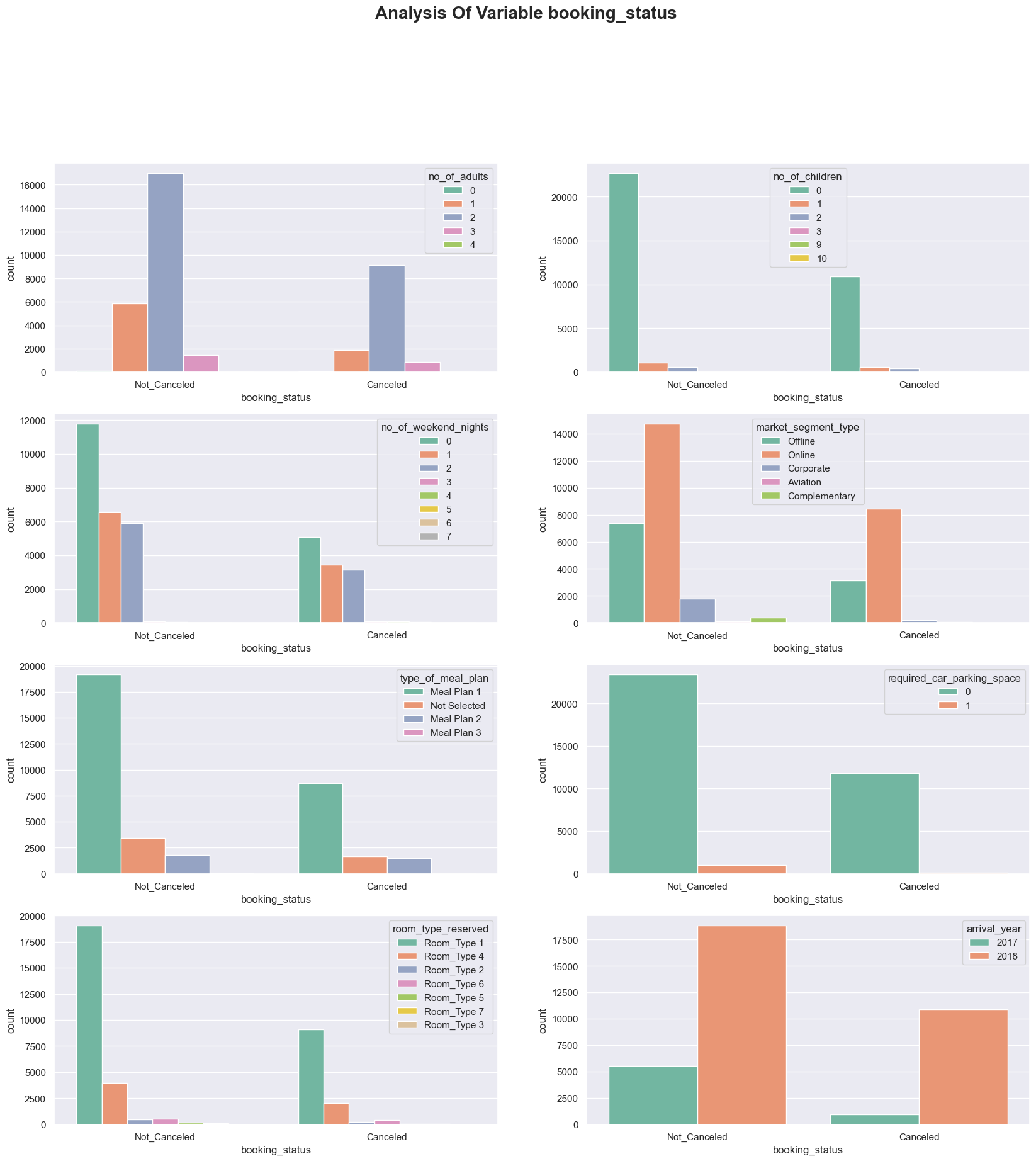
plt.figure(figsize = (20, 25))
plt.suptitle("Analysis Of Variable booking_status",fontweight="bold", fontsize=20)
plt.subplot(5,2,1)
sns.countplot(x='booking_status', hue='repeated_guest', palette='Set2', data=df)
plt.subplot(5,2,2)
sns.countplot(x = 'booking_status', hue = 'no_of_special_requests', palette = 'Set2', data = df)
plt.subplot(5,2,3)
sns.kdeplot(x='lead_time', hue='booking_status', palette = 'Set2', shade=True, data=df)
plt.subplot(5,2,4)
sns.kdeplot(x='arrival_year', hue='booking_status', palette = 'Set2', shade=True, data=df)
plt.subplot(5,2,5)
sns.kdeplot(x='arrival_month', hue='booking_status', palette = 'Set2', shade=True, data=df)
plt.subplot(5,2,6)
sns.kdeplot(x='arrival_date', hue='booking_status', palette = 'Set2', shade=True, data=df)
plt.subplot(5,2,7)
sns.kdeplot(x='avg_price_per_room', hue='booking_status', palette = 'Set2', shade=True, data=df)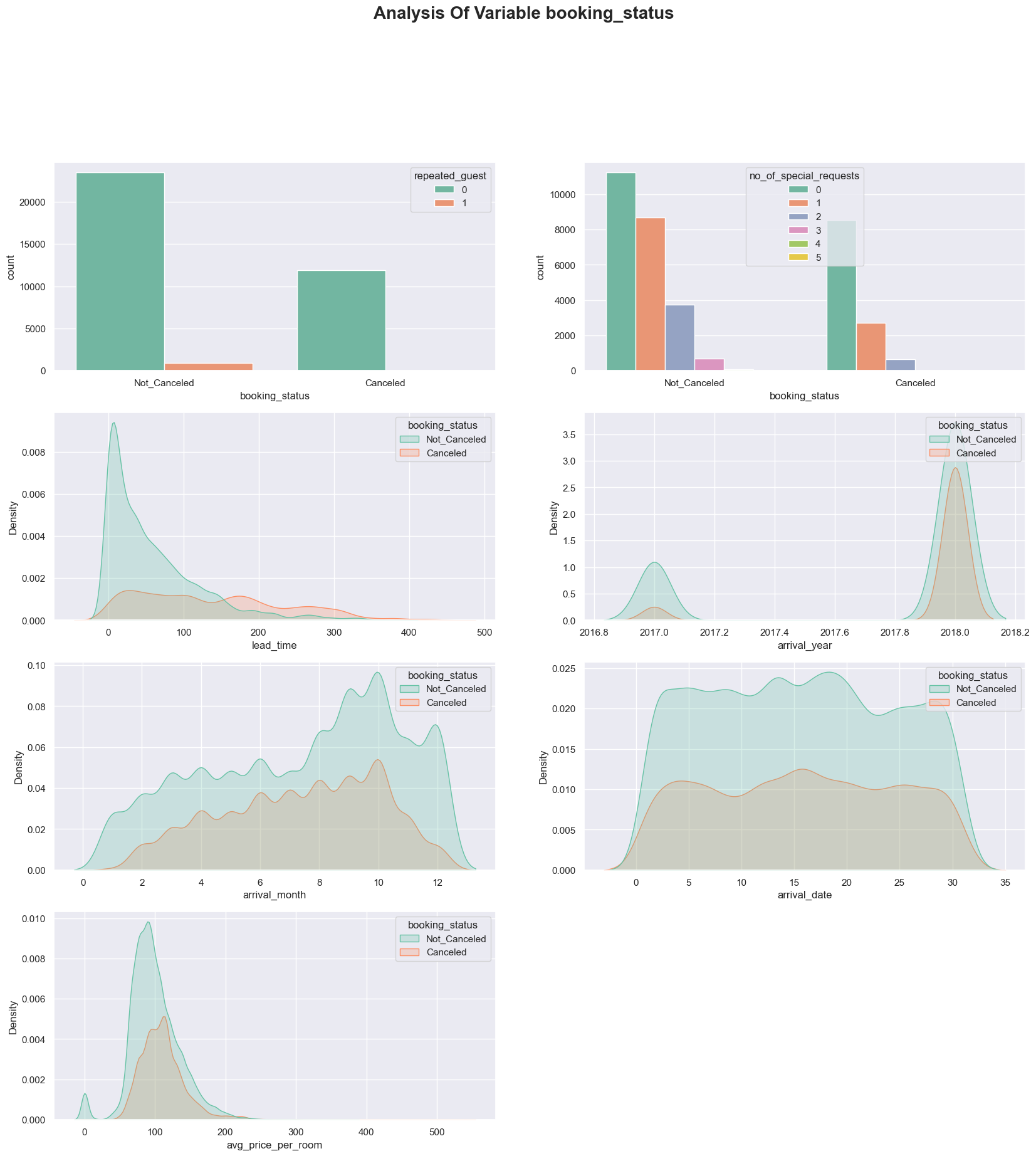
이제 앞서 살펴본 것처럼 Lead_Time 변수가 취소와 미취소를 가장 많이 구분하는 변수였으므로 자세히 살펴보겠습니다.
시간, 우리는 이미 호텔에 머물렀던 손님에게도 같은 것을 봅니다. 다른 변수를 보면 우리의 주의를 환기시키는 몇 가지 변수가 있습니다.
세그먼트를 보면 "특별한" 이유로 손님은 일반적으로 리드 타임이 높지 않습니다. 다른 방보다 빨리 선택되는 방도 있고 특별 요청을 보면 시간이 걸리더라도 요청이 많을수록 리드 타임이 줄어 듭니다.
가격이 더 높고 , 리드 타임이 높을수록 취소가 될 확률이 높음
sns.scatterplot(data=df, x='lead_time', y='avg_price_per_room', palette='Set2', hue='booking_status')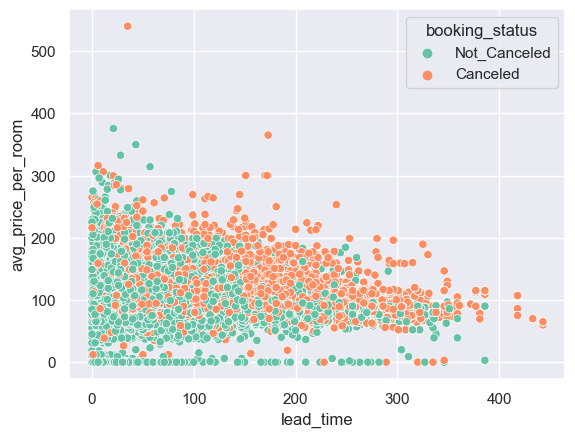
데이터 시각화를 하다보니 코드가 너무 길어져서
모델링은 다음 포스팅에서 보여드리도록 하겠습니다. !!
감사합니다