

Dataset - Kaggle 의 netflix_titles.csv 데이터 세트
https://www.kaggle.com/code/joshuaswords/netflix-data-visualization
Netflix Data Visualization
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
EDA
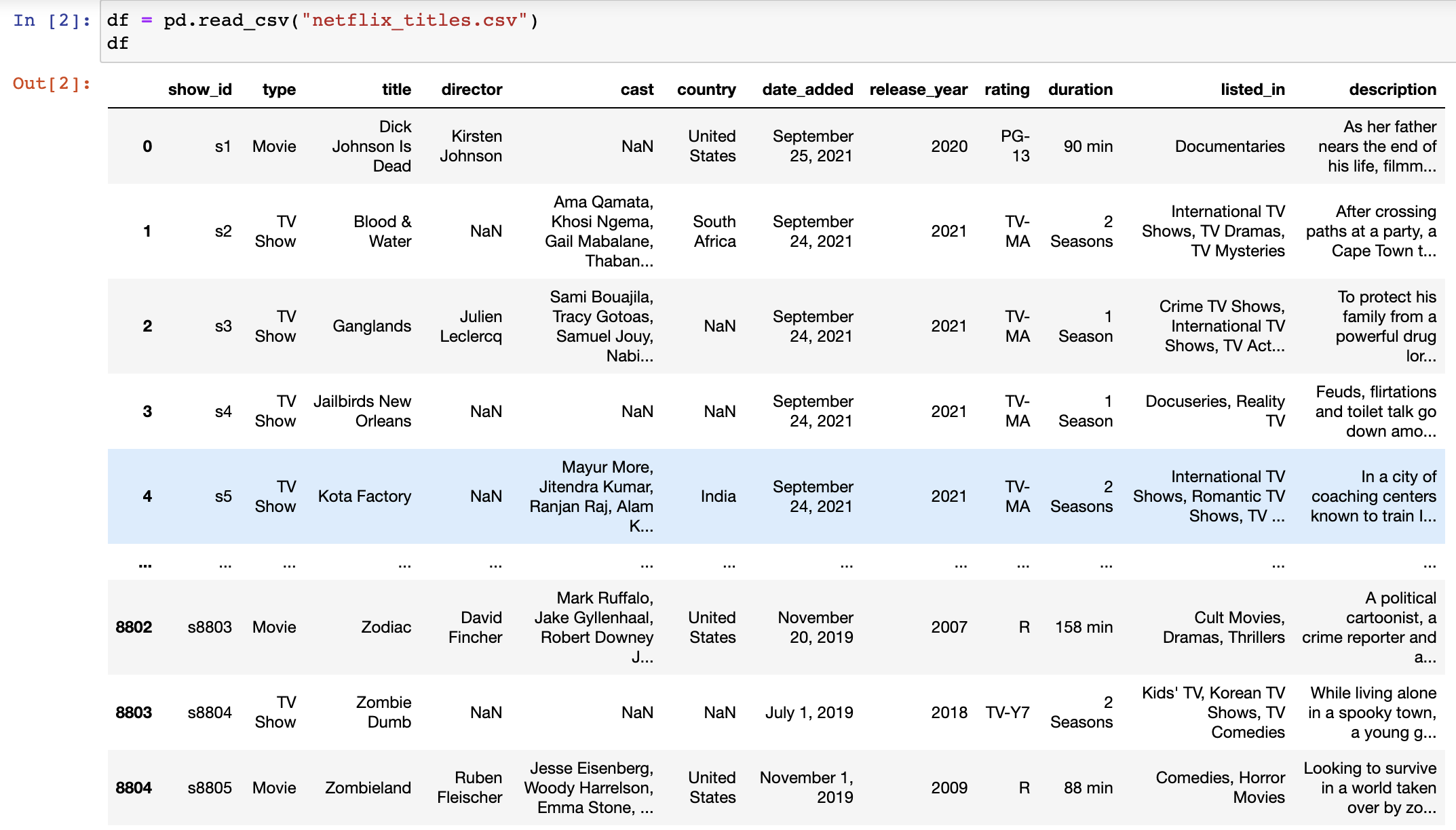
사실 여기까지는 뭐,..
애초에 데이터 시각화를 연습하기 위해서 이 데이터 셋을 선택했기에.
데이터 시각화를 요즘 하도 안해서 코드를 작성하는 피지컬이 많이 죽었다고 해야하나 ㅜㅜ
사용해야 하는 파라미터 값이나 문법도 많이 까먹어서 다시 매일 하나씩 시각화 해보려고 한다.
시각화는 텍스트로 되어있는 데이터 값들을 한 눈에 보기 좋게 나타내는 과정이다.
단순히 그래프를 그리기 보다는 개인적으로 인터렉티브하고 예쁜 그래프를 좋아하기에 ( 그리고 시각화의 목적은 보는 사람의 이해가 가장 중요 하다고 생각해서 ) 기초부터 다시 하지는 않고 어려운 그래프들을 그리면서 코드에 익숙해지려고 한다.
탑-다운 방식으로 시각화 공부를 시작 !
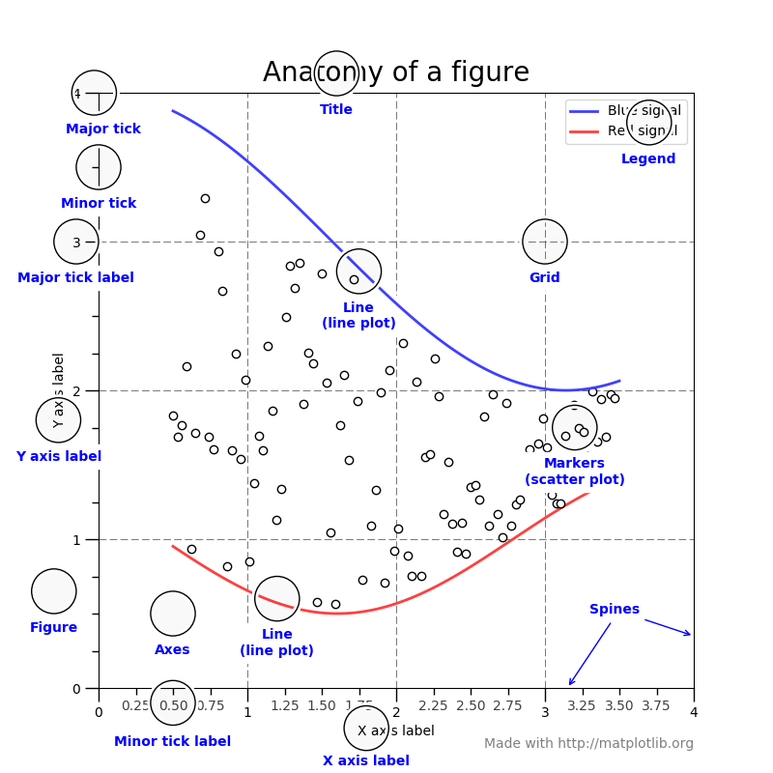

우리의 목표는 위에 있는 그래프를 만드는 것이다.
보기만 해도 어렵지만 하나씩 만들어지는 과정을 따라가보자.
fig, ax = ~~
이렇게 시작하는 경우를 많이 보게 되는데, 꼭 이해하고 넘어가자. 한 줄 한 줄
fig ,figure 는 그래프가 담기게 되는 프레임이라고 생각하면 된다.
ax , axes 는 그래프가 그려지는 캔버스라고 생각하자.
subplots 에 s가 붙고 안붙고 차이가 크니 주의하자.
plt.subplots에는 두개의 값을 받을 수 있는데 figure 와 axes 값을 받을 수 있다.
plt.subplots의 파라미터는 ( nrows , ncols , ... ) -> 행과 열의 수를 정할 수 있다.
# subplot의 예
plt.subplot(2,1,1)
plt.subplot(2,1,2)
plt.show()# subplots의 예
fig, axes = plt.subplots(nrows=2, ncols=1)
plt.show()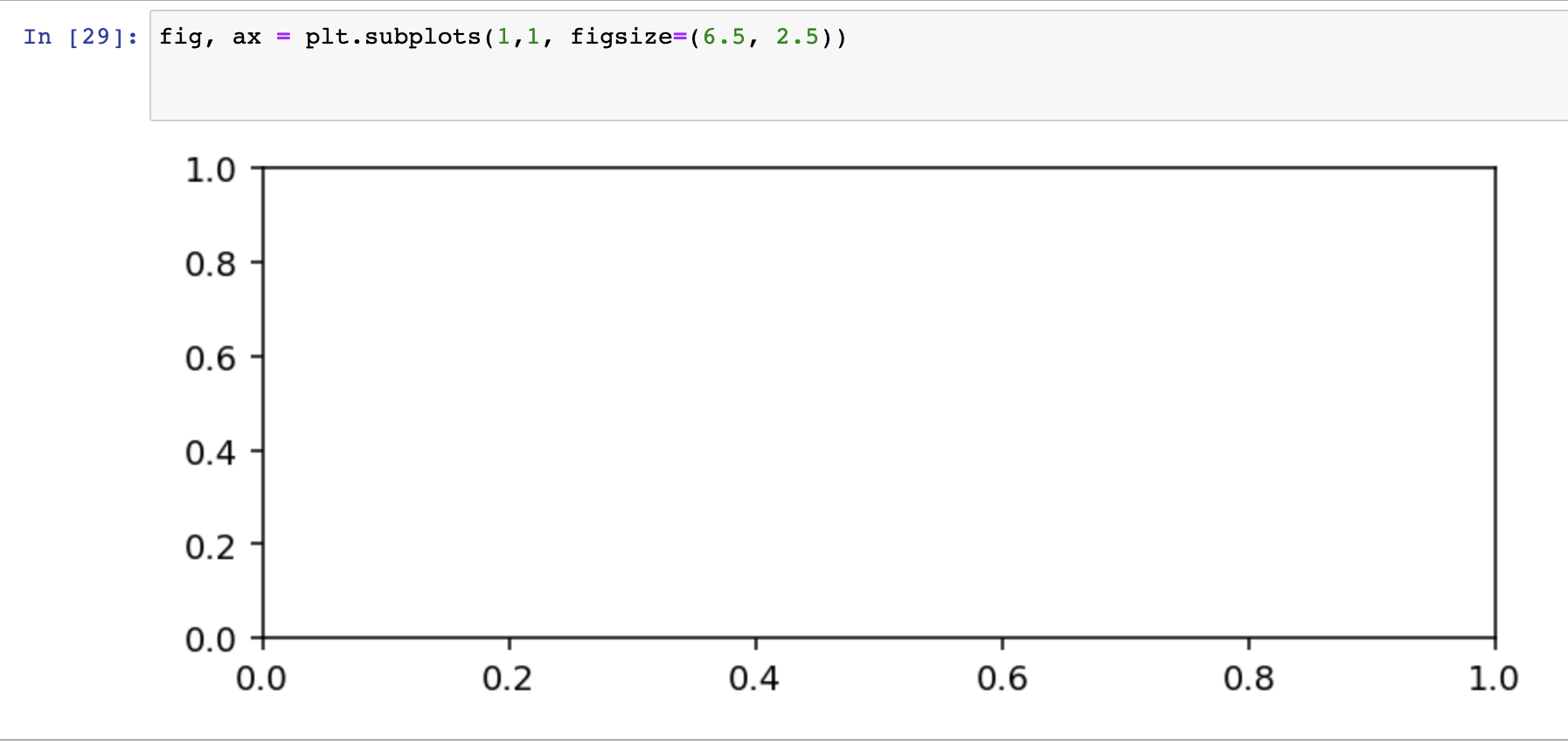
우선 데이터에서 Movies와 TVshow에 대해 비율을 구하는 전처리 작업을 해아한다.

추가된 코드들을 살펴보자
Bar plot 이란 직사각형 막대를 사용하여 데이터의 값을 표현하는 차트/그래프이다.
주로 범주(category)에 따른 수치 값을 비교할 때 적합한 방법이다. ( 개별, 그룹 비교 모두 적합 )
막대의 방향에 따라서 두 가지로 분류할 수 있다.
* bar - 수직방향. x축에 범주 y축에 값을 표기 ( default )
* barh - 수평방항. y축에 범주, x축에 값을 표기. ( 범주가 많을 때 적합 )
barh에서는 left 파라미터를 사용합니다.
# barh(y=bar의 y좌표, width, left= bar의 왼쪽부분 좌표, alpha는 투명도)
- xlim() - X축이 표시되는 범위를 지정하거나 반환합니다.
- ylim() - Y축이 표시되는 범위를 지정하거나 반환합니다.
- axis() - X, Y축이 표시되는 범위를 지정하거나 반환합니다.
- xticks , yticks = x,y축 눈금 설정
ax.barh(mf_ratio.index, mf_ratio['Movie'], color="#b20710", alpha=0.9, label="Male")
ax.barh(mf_ratio.index, mf_ratio['Movie'], left=mf_ratio['Movie'], color="#221f1f", alpha=0.9, label="Female")
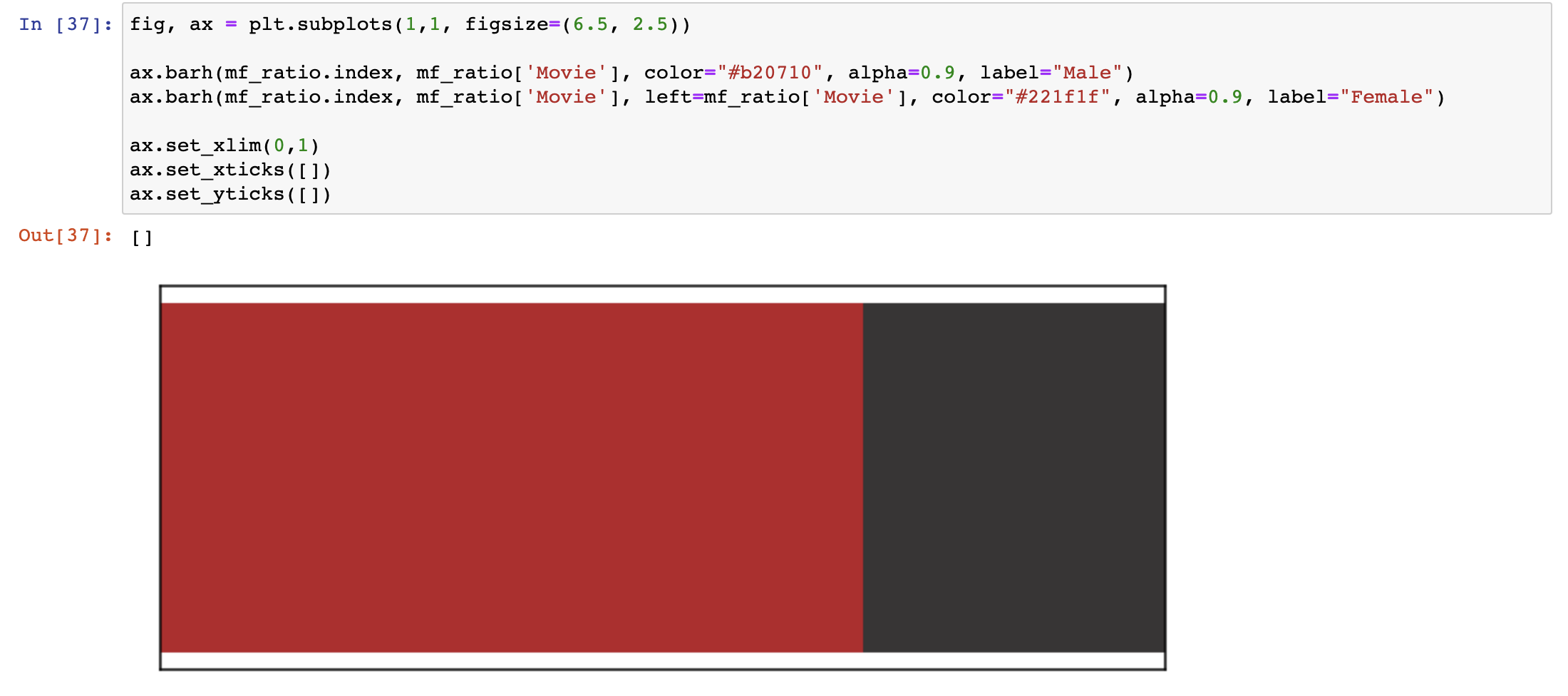
대충 형태를 잡아주고 movie percentage를 그려주는 작업을 진행한다.

annotate 는 주석을 다는 옵션인데요, 매우 유용하게 활용되며 자주 활용되므로 기억하는게 좋다.
annotate 사용 자체는 어려움이 없으나 노련함이 느껴지는 부분은 for문과 결합하여 사용하는 부분.
f"{int(mf_ratio['Movie'][i]*100)}%"
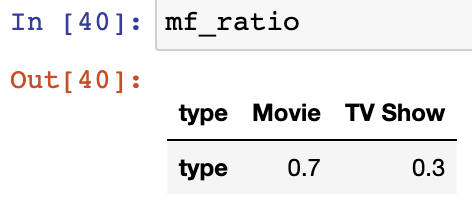
for 문을 하나씩 뜯어보면 mf_ratio 의 'Movie'라는 컬럼은 어차피 0번째 컬럼인 0.7밖에 없다.
그래서 0.7 * 100 을 통해서 비율에 해당하는 값을 만들어 준 것이다.

그 다음 파라미터인 xy를 살펴보자.
xy는 우리가 작성하고자 하는 주석의 좌표(위치)를 정해준다
위에서 xlim을 통해서 x 축의 범위를 0~1로 설정해줬기 때문에 0~1사이의 값으로 위치 좌표를 나타낸 것으로 보인다.

ha , va 는 각각
horizontal alignment , vertical alignment 로 수평 정렬 , 수직 정렬이다.
"center" , "left" , "right" 등으로 위치를 정해줄 수 있다.
그 외의 폰트 설정과 색상 설정은 직관적이므로 넘어간다.
나머지 TV show 부분까지 채워보면

나머지 그래프의 제목과 설명을 채워보자

ax.spines 를 눈여겨 보자.
축을 커스터마이징 하는데 사용되는 객체(object)를 spines 라고 하는데,
left, right, bottom, top 등 위치를 나타내는 key가 있다.
위에 보이는 것처럼 for 문을 이용하여 원하는 위치만 커스텀 할 수도 있다.
이전 그래프를 보면 막대 그래프 주변에 남이있는 잉여 fig 부분이 남아있는걸 볼 수 있는데,
바로 위 그래프를 보면 주변이 깔끔하게 정리되어 있음을 확인할 수 있다.
예를 하나 들면서 마무리 하도록 하겠다.
