
https://www.kaggle.com/datasets/ahsan81/hotel-reservations-classification-dataset
Hotel Reservations Dataset
Can you predict if customer is going to cancel the reservation ?
www.kaggle.com
Hotel Reservations
온라인 예약 플랫폼을 통해서 예약한 호텔에 대해 고객들의 선택은 굉장히 유동적입니다.
예약 취소나 노쇼가 흔하게 일어나죠.
호텔 입장에서는 이런 상황을 미리 예측하고 줄여야 손해를 막을 수 있습니다.
EDA와 시각화를 해보고 다양한 모델들을 만들어봅시다.
시각화에 굉장히 많은 시간을 투자했습니다. 컬럼이 많아서 시각화 하여 서로의 관계를 파악하는 단계가 길어졌습니다.
Data EDA
필요한 라이브러리들을 우선 import 해보고 시작합시다 !
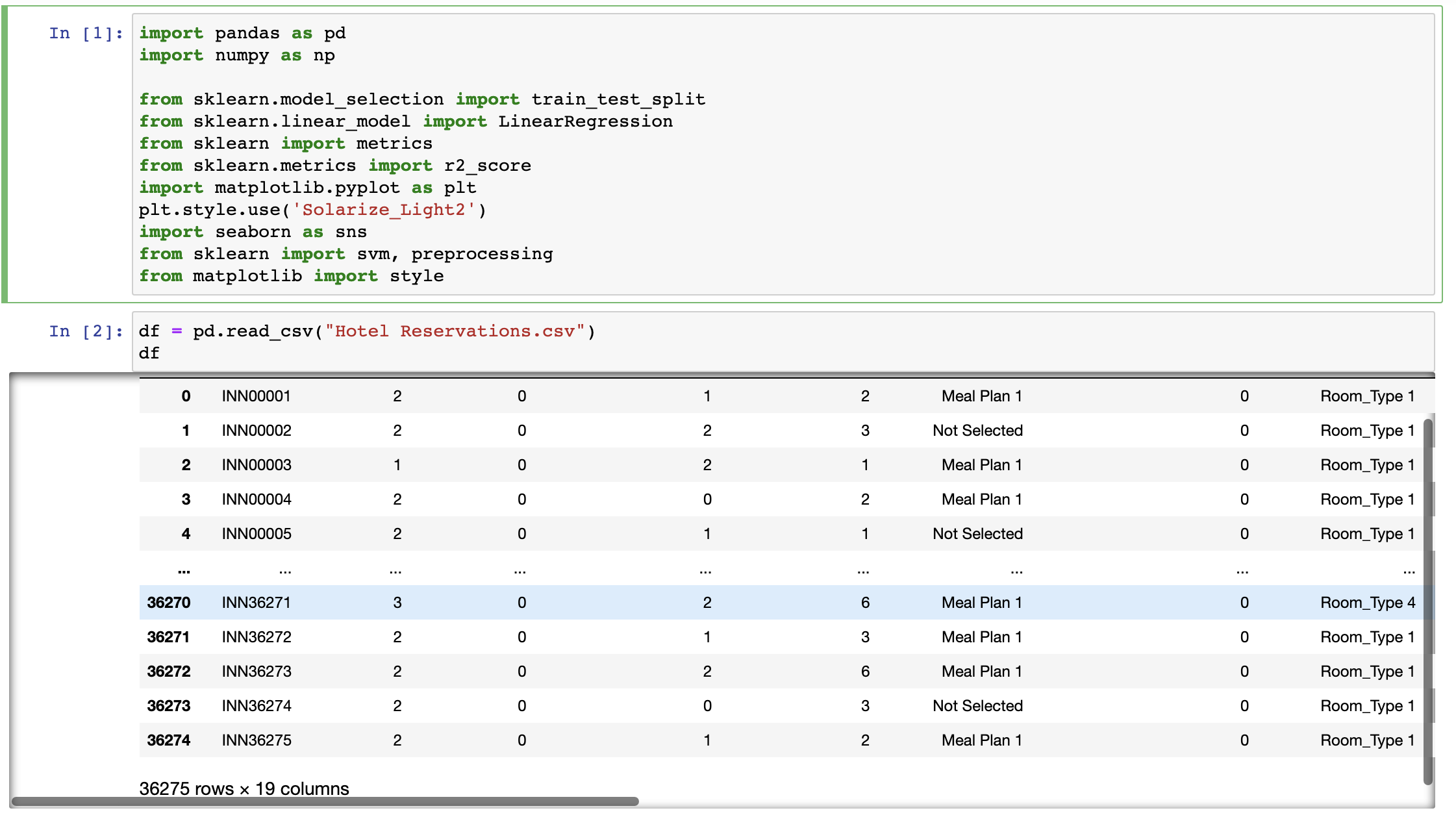
우리가 사용할 호텔 데이터세트의 컬럼 정보입니다.

info로 데이터의 대략적인 정보를 확인해보고요

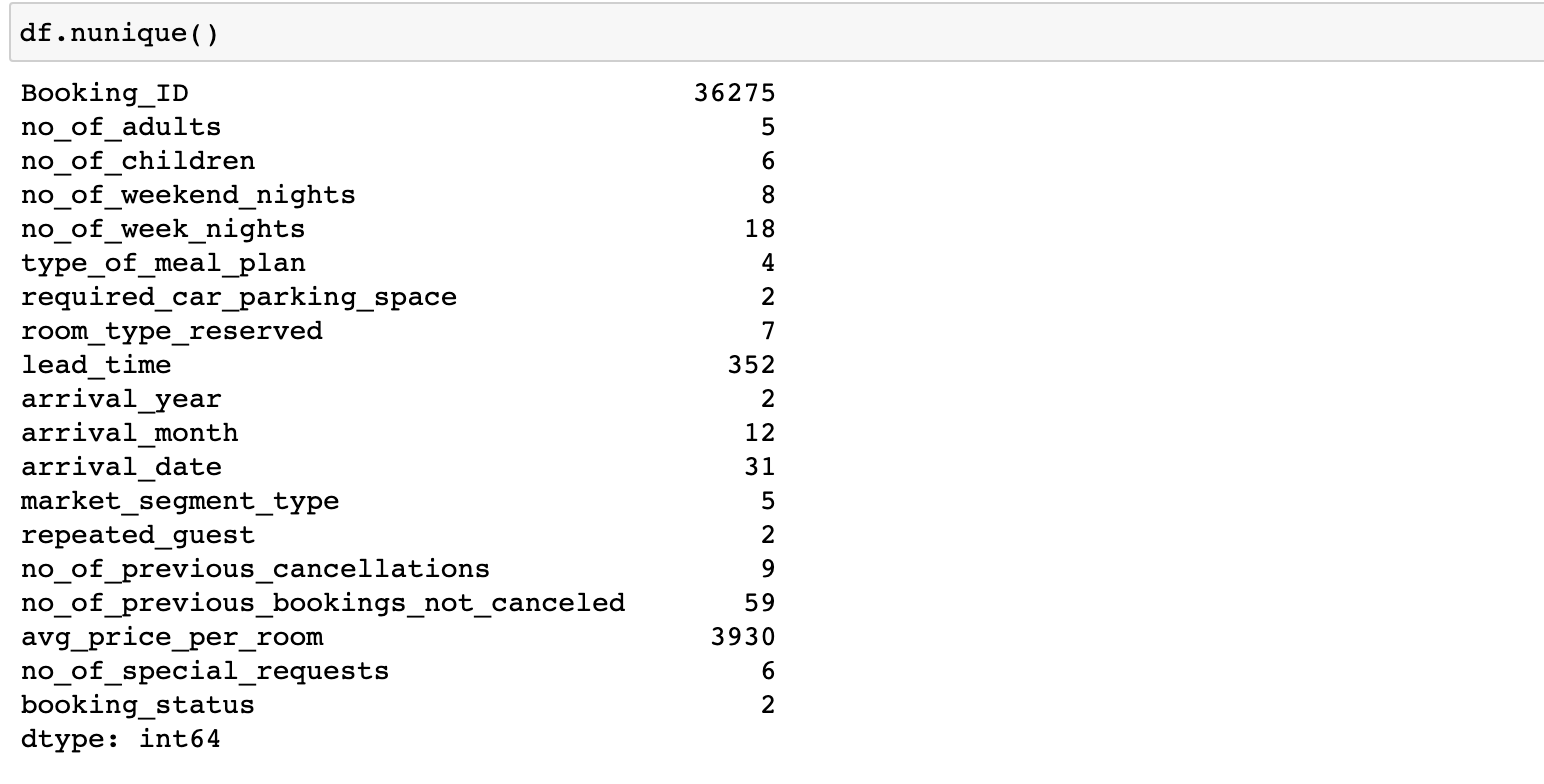
유니크 값들이 몇개나 있는지도 확인합니다.
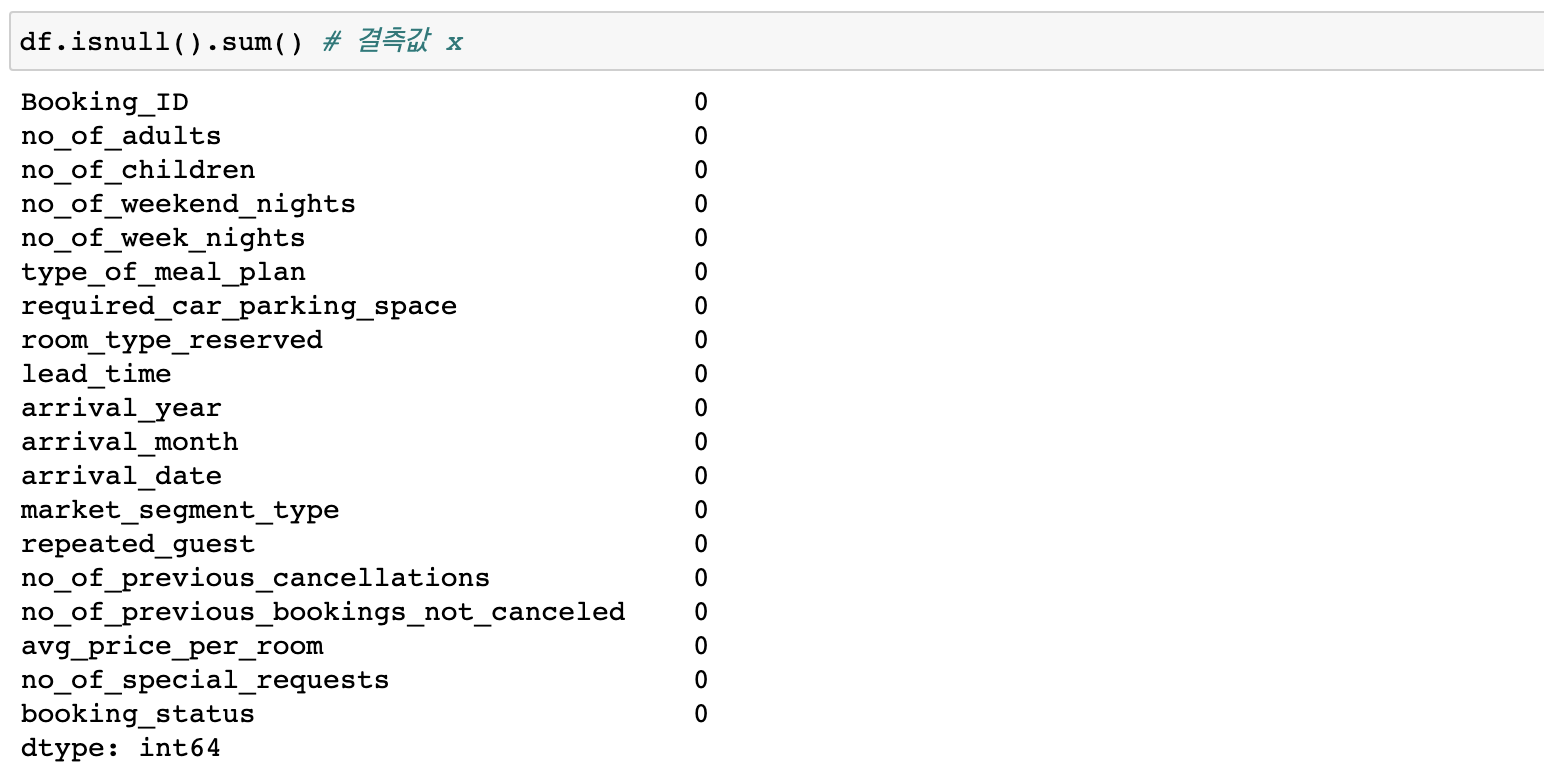
결측값은 없는걸로 파악되네요
시각화
pandas의 groupby 를 사용하여 호텔을 예약한 성인들의 수를 pie 차트로 나타냈습니다.
2인 예약이 가장 많고 그 다음은 1인 3인으로 이어집니다.
df.groupby('no_of_adults')['Booking_ID'].agg(['count']).sort_values(by='count', ascending=False).plot(kind='pie',
autopct='%1.2f%%',
subplots=True,
figsize=(8,8))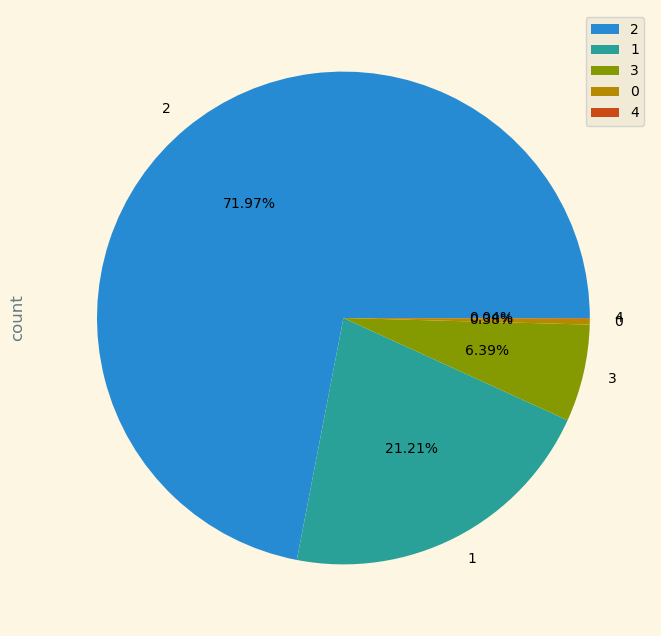
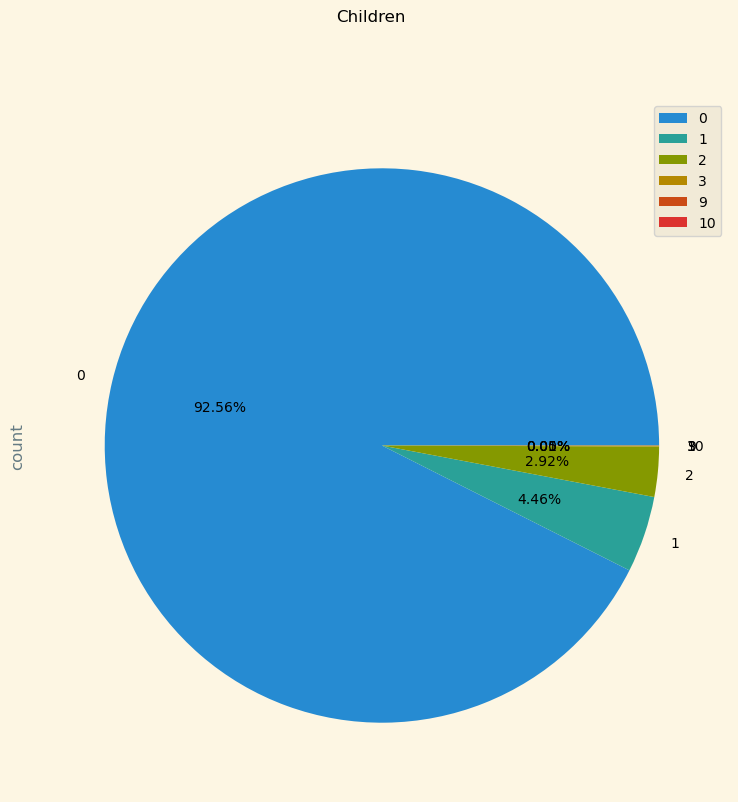
그 다음은 투숙객중 아이가 얼마나 있는지 파이차트로 그려봤습니다.
0명이 92%로 가장 높네요.
df.groupby('no_of_children')['Booking_ID'].agg(['count']).sort_values(by='count',
ascending=False).plot(kind='pie',
autopct='%1.2f%%',
subplots=True,
title='Children',
figsize=(9,9))
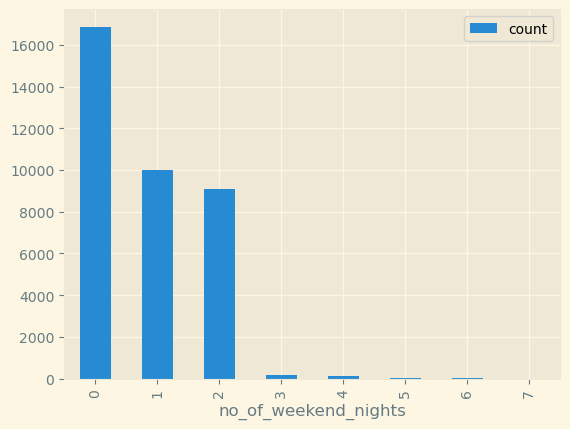
주말 밤에 예약한 횟수를 보여주는 것 같습니다.
seaborn 라이브러리를 활용하여 hist plot으로도 그려봤습니다.
df.groupby('no_of_weekend_nights')['Booking_ID'].agg(['count']).sort_values(by='count', ascending=False).plot(kind='bar',
)
sns.histplot(x='no_of_week_nights',
data=df,
hue='no_of_weekend_nights',
kde=True,
palette='Set3')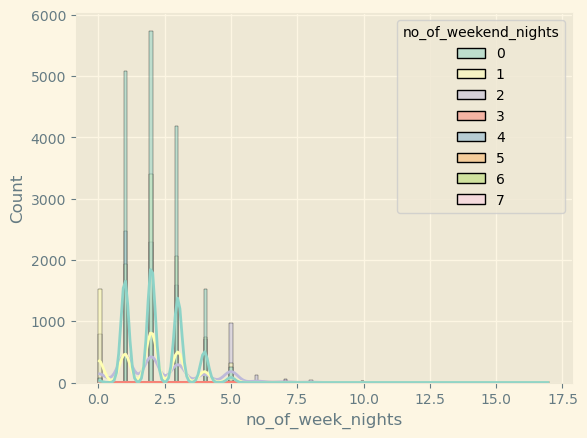
그 다음은 식사 타입을 의미하는 meal plan 컬럼입니다.
plan 1이 가장 높은 비율을 차지하네요.
df.groupby('type_of_meal_plan')['Booking_ID'].agg(['count']).sort_values(by='count', ascending=False).plot(kind='pie',
subplots=True,
figsize=(8,8),
title='Meal')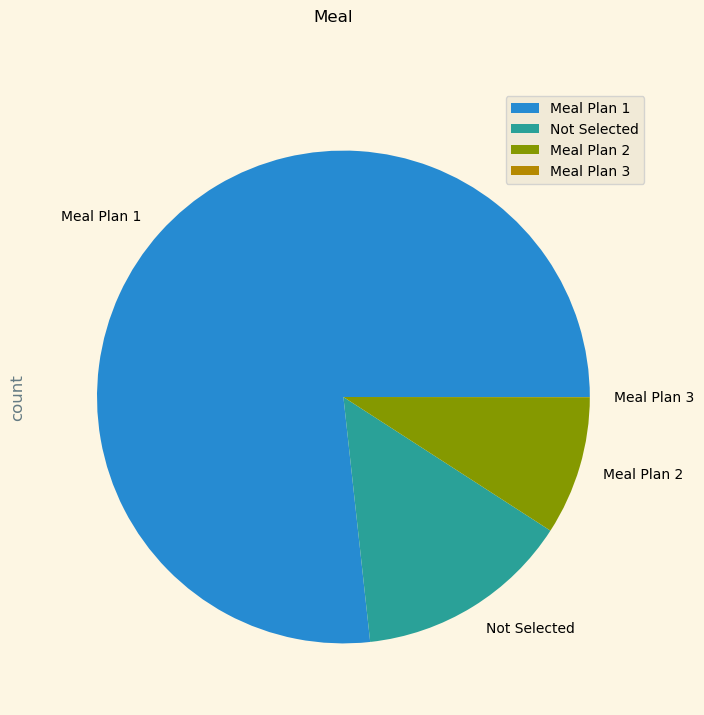
그 다음으로는 주차장을 요구한 손님들의 비율입니다.
0은 필요하지 않는 손님들이고, 1은 주차장을 요구한 손님들의 비율입니다.
df.groupby('required_car_parking_space')['Booking_ID'].agg(['count']).sort_values(by='count',ascending=False).plot(kind='pie',autopct='%1.2f%%',subplots=True,title='Required car parking space',figsize=(9,9))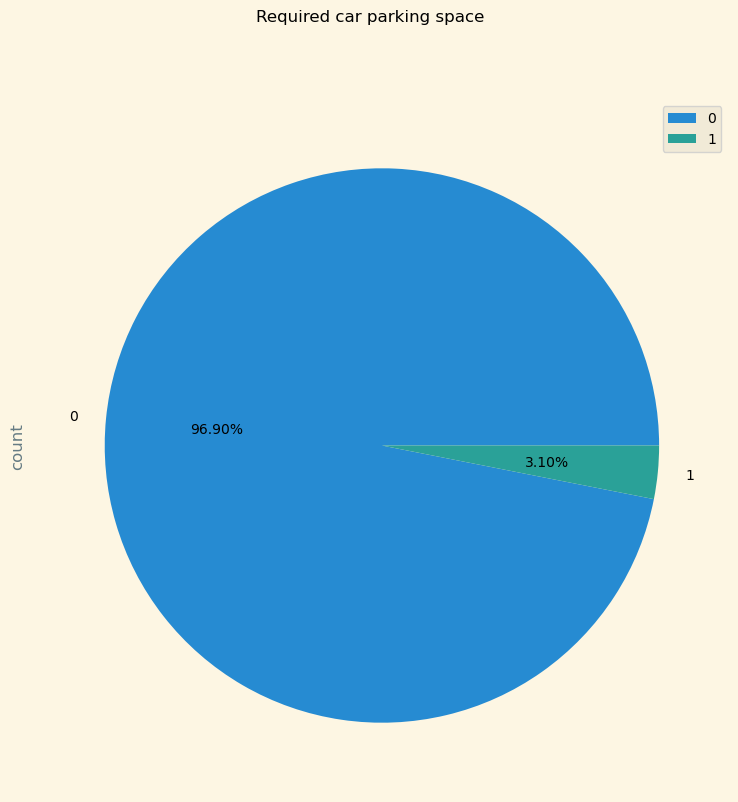
다음 포스팅에서는 더 다양한 시각화 라이브러리를 통해
시각화 연습을 더 해보고 머신러닝 모델을 구축해 보겠습니다. !! 감사합니다 ::)