
https://minyoungxi.tistory.com/52
논문 리뷰 - Vision Transformer 비전 트랜스포머 part2
https://minyoungxi.tistory.com/51 ViT의 장점 transformer 구조를 거의 그대로 사용하기 때문에 확장성이 좋음 large 스케일 학습에서 매우 우수한 성능을 보임 transfer learning 시 CNN보다 훈련에 더 적은 계산 리
minyoungxi.tistory.com
2021년 마이크로소프트 아시아에서 발표한 Swin Transformer에 대해 알아봅시다.
ViT(Vision Transformer)는 이미지를 patch로 잘라 self attention을 하는데요, 이 논문에서 모든 patch가 self attention을 하는 것에 대해 computation cost를 지적합니다. 각 patch를 window로 나눠 해당 window 내부에서만 elf attention을 수행하고 그 윈도우를 다시 한번 shift하고 다시 self attention을 하는 구조를 제시합니다. 그래서 이름이 Swin(Shifted windows) Transformer 입니다.
또한 일반적인 Transformer와 달리 마치 Feature Pyramid Nerwork같은 Hierachical 구조를 제시하면서 classification은 물론 Object Detection, Segmentation과 같은 Task에서 backbone으로 사용되어 좋은 성능을 가져옵니다.
Introduction
기존의 비전 분야에 Transformer를 활용한 접근법은 어떤 문제가 있는지 언급하였습니다.
저자가 언급한 기존의 ViT의 문제점을 살펴봅시다.
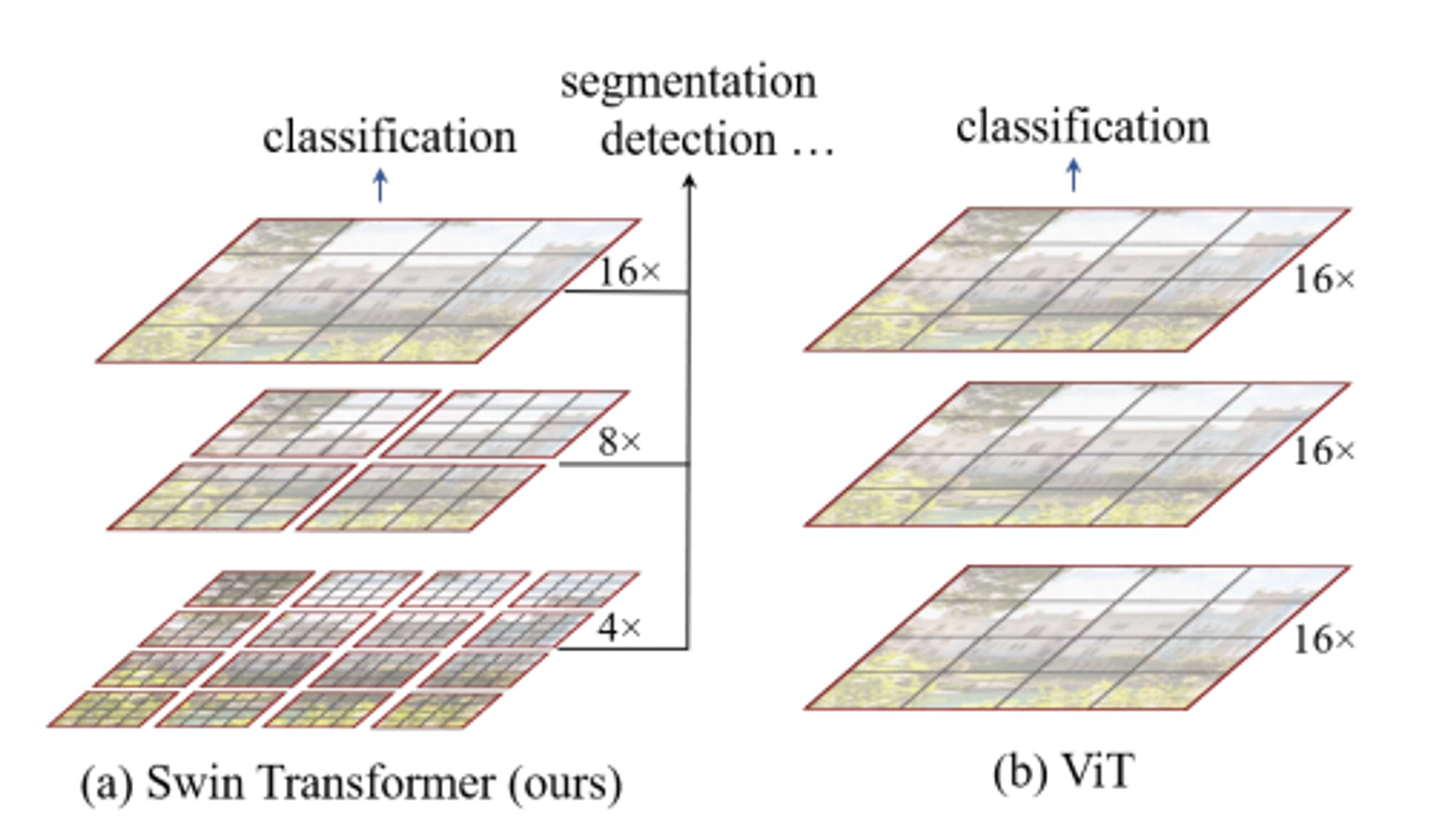
previous vision Transformers [20] produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of selfattention globally.
입력 이미지의 사이즈가 256 x 256 이라고 할 때, ViT는 각 patch 사이즈를 16 x 16 으로 만들어서 256 / 16 ** 2 = 196개의 patch를 가진 상태를 유지하고 각 patch와 나머지 전체 patch에 대한 self-attention을 수행합니다. ( quadratic computational complexity to image size) - (b) 이미지
The proposed Swin Transformer builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks.
반면 Swin Transformer는 마치 feature pyramid network처럼 작은 patch 4x4에서 시작해서 점점 patch들을 merge 해나가는 방식을 취합니다. 그에 반해 ViT는 이미지를 작은 patch로 쪼개는 방향으로 가죠. 그림을 보시면 빨간선으로 patch들을 나눈 것을 볼 수 있는데 이것을 각각 window라고 부르고 Swin Transformer는 window내의 patch들끼리만 self-attention을 수행합니다. ( linear computational complexity to image size )
논문에서는 각 window size를 7x7로 한다. 정리하면 첫 번째 레이어에서 4x4 size의 각 patch가 56x56
개가 있고 이것을 7x7 size의 window로 나누어 8x8개의 window가 생깁니다.
즉 첫 번째 stage에서 각 patch는 16개의 픽셀이있고, 각 윈도우에는 49개의 patch가 있다는 의미입니다.
( embedding을 하기 때문에 채널을 곱해줘야 하는데 그림의 이해를 돕기위해 생략 )
There exist many vision tasks such as semantic segmentation that require dense prediction at the pixel level, and this would be intractable for Transformer on high-resolution images, as the computational complexity of its self-attention is quadratic to image size.
computational complexity on high-resolution images 로 문제점을 축약할 수 있습니다.
이미지의 해상도 ( 픽셀 )가 늘어나면 늘어날수록 모든 patch 조합에 대해 self-attention을 수행하는 것은 불가능하다는 의미입니다. Swin transformer는 hierarchical feature map을 구성함으로써 이미지 크기에 대해 linear complexity를 가질 수 있도록 고안된 아키텍처를 가집니다. 이러한 장점은 Swin Transformer가 다양한 비전 분야의 작업에 있어 general-purpose backbone으로 적합하게 만들며, 단일 해상도의 feature map을 만들고 quadratic complexity를 갖는 이전의 트랜스포머 기반 아키텍처와 차이점을 가집니다.

Shift of the window ( shifted Window based Self-Attention )
A key design element of Swin Transformer is its shift of the window partition between consecutive self-attention layers

shifted window partitioning는 이전 레이어의 window와 현재의 window 사이를 이어주며 모델의 성능을 효과적으로 향상시킵니다. Swin transformer는 위에서 제시한 computational complexity의 한계를 극복하기 위해 window들 내부에서만 patch끼리의 self-attention을 계산하는 것으로 제안합니다.
그리고 self-attention 계산이 M개의 patch들로만 제한되기 때문에 연산의 효율성도 획득할 수 있게 됩니다.
Window 분할 방식
- W-MSA: feature map을 M개의 window로 나누는 것 (regular - 위 그림에서 왼쪽)
- SW-MSA: W-MSA 모듈에서 발생한 패치로부터 ([M/2, M/2])칸 떨어진 patch에서 window 분할 (shifted - 위 그림에서 오른쪽)
Architecture
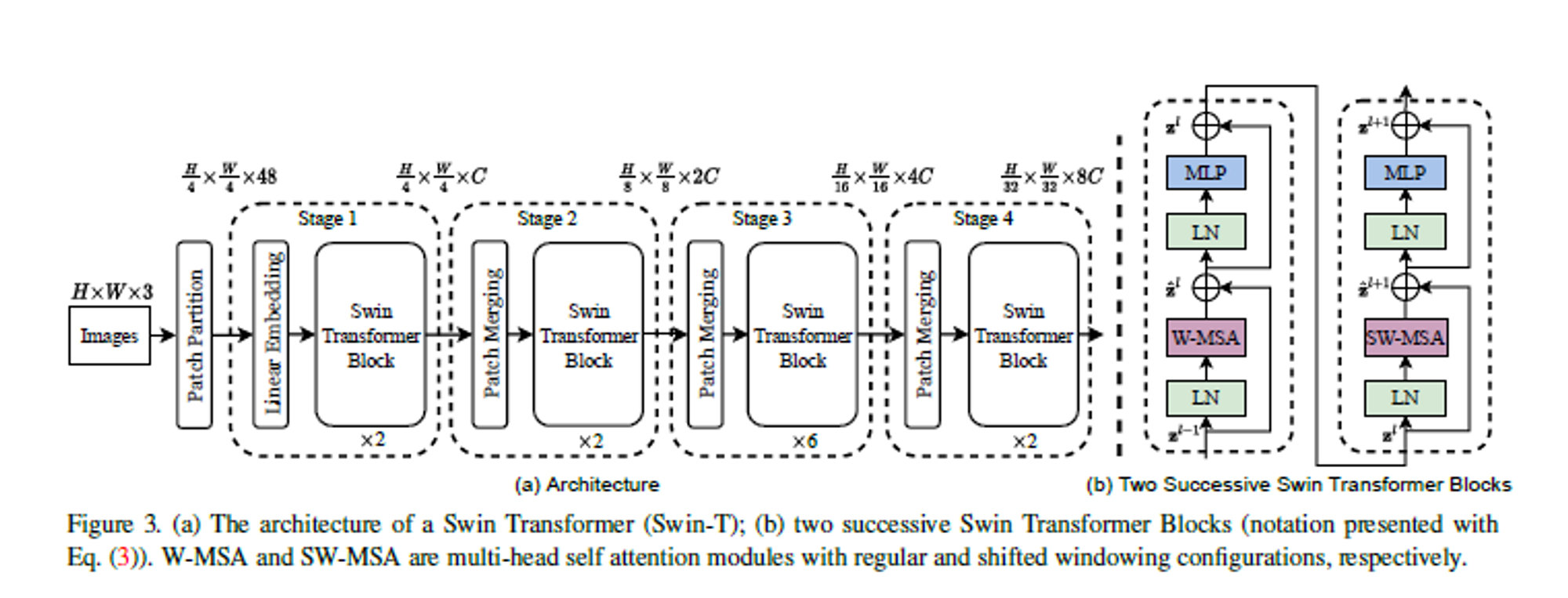
위 그림은 Swin Transformer 전체적인 구조입니다.
크게 Patch Partition, Linear Embedding, Swin Transformer, Path Merging으로 구분이 되며 4개의 Stage로 이루어져 있습니다.
핵심 아이디어인 Swin Transformer Block은 오른쪽 그림(b)에 보이는 것과 같이 두개의 encoder로 구성되어 있으며 일반적인 MSA(Multi head Self-Attention)이 아니라 W-MSA, SW-MAS로 이루어져 있습니다.
각 stage 아래에 적혀있는 x2/x2/x6/x2 은 Swin Transformer Block의 횟수인데 1개의 Block당 2개의 encoder가 붙어 있으므로 세트로 묶어서 실제로는 1/1/3/1 개의 Block이 반복된다고 보면 됩니다.
H / W : 이미지의 높이와 너비
C : image token
각 stage 위에 적혀있는 H/4 x W/4 x C 는 patch x patch x channel이며 48은 초기 patch size x channel (4x4x3)으로 구해졌으며 C는 base model인 Swin-T에서 96을 사용합니다.
Relative position bias
ViT와 다른 점은 position embedding이 없다는 것입니다. ViT에서는 각 이미지 토큰의 위치 정보를 보존하기 위해 position embedding을 더해주었습니다. 반면 Swin transformer에서는 이러한 과정이 없고 self-attention을 수행하는 과정에서 relative position bias를 추가해줍니다.
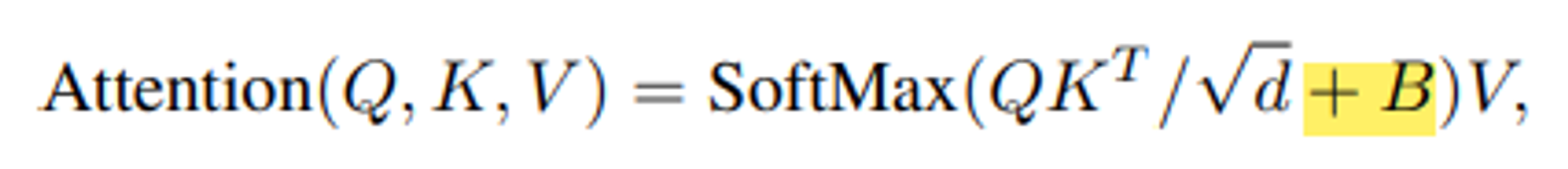
위의 식은 일반적인 attention score를 구하시는 식에 bias인 B를 더해주었다. ( d는 query / key dimension ).
M개의 patch가 하나의 window를 구성므로 각 축을 따라 상대적인 위치는 [-M +1 , M-1 ] 범위 안에 있습니다.
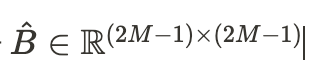
따라서 작은 크기의 bias 행렬을 [1]에 속하는 B로 파라미터화 할 수 있습니다.
기존에 position embedding은 절대좌표를 그냥 더해주었는데 본 논문에서는 상대좌표를 더해주는 것이 더 좋은 방법이라고 제시합니다.
Patch partition

ViT와 같은 patch 분리 모듈을 통해 raw input인 RGB 이미지를 겹치지 않는 patch들로 나눠줍니다.
마찬가지로 patch는 일종의 토큰으로 취급되며, 논문에서는 patch size를 (4X4)로 설정했으므로 하나의 Feature는 (4x4x3) = 48의 shape을 가집니다.
Swin Transformer Block
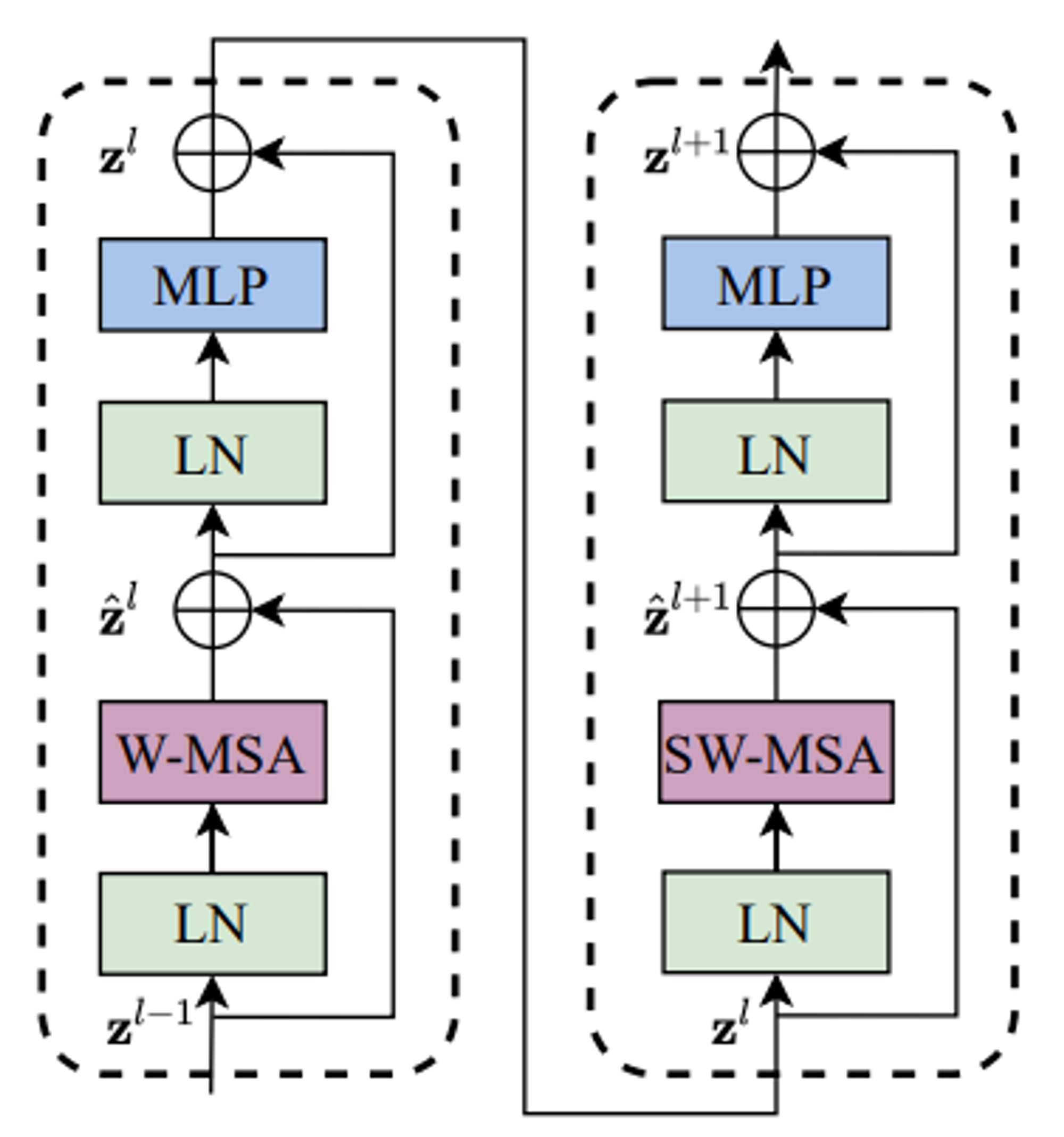
swin transformer의 트랜스포머 block은 multi-head self-attention(MSA) 모듈을 window 기반의 W-MSA와 SW-MSA 모듈로 교체하였으며, 각각의 MSA 모듈을 포함한 2개의 연속적인 트랜스포머로 하나의 Swin block이 형성됩니다.
다른 레이어는 기존의 ViT와 동일합니다. window 기반의 MSA 모듈 이후에는 GELU 활성화 함수를 사이에 둔 2층 linear layer로 구성된 MLP block이 배치되었습니다. 각 MSA 모듈과 MLP 앞에 LN(Layer Norm) 층이 적용되고, 각 모듈 뒤에 residual connection이 적용됩니다.
먼저 일반적인 MSA와 W-MSA는 무슨 차이점이 있고 이것이 왜 가능할까요??
W-MSA는 현재 윈도우에 있는 patch들끼리만 self-attention 연산을 수행합니다. 이미지는 주변 픽셀들끼리 서로 연관성이 높기 때문에 윈도우 내에서만 self-attention을 써서 효율적으로 연산량을 줄이려는 아이디어입니다. (마치 CNN의 kernel을 쓰는 이유와 비슷)
그래서 본 논문에서 local window 내에서만 self-attention을 계산할 것을 제안합니다.
논문에서는 W-MSA를 통해 일반적인 MSA의 quadratic한 연산을 linear 하게 만들어 줄 수 있다고 하네요.
각 window에 M x M patch들이 포함되어 있다고 가정하면, global MSA 모듈의 computational complexity와 h x w 크기의 patch를 기반으로 하는 window는 다음과 같습니다.
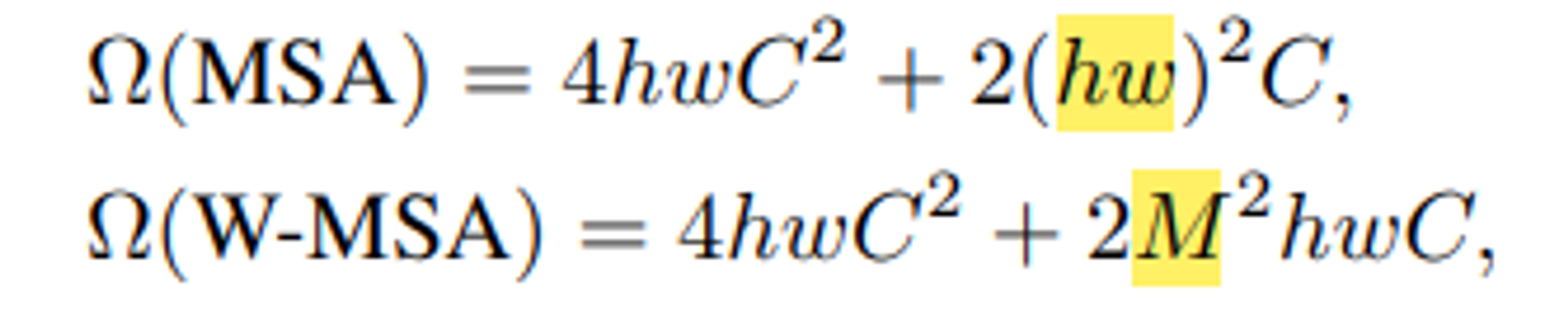
위의 식에서 M(window size)는 hw(image size) 보다 훨씬 작기 때문에 W-MSA의 연산량이 훨씬 적고 결국 image size가 커져도 ViT에 비해 연산량을 매우 줄일 수 있습니다. 여기서 전자는 patch에 대해 quadratic하고, 후자는 M이 고정될 때 linear 합니다. ( 논문에서는 M =7 으로 설정 )
하지만 window가 고정되어 있기 때문에 고정된 부분에서만 self-attention을 수행하는 단점이 있어서 저자들은 이 윈도우를 shift 해서 self-attention을 한 번 더 수행했습니다. ( SW-MSA )
논문에서 제시한 두가지 접근법
- naive solution : 작아진 window 들에 padding을 두어 크기를 다시 M x M으로 맞춰주고 ( W-MSA 모듈에서 ( 2x2 )였던 window의 개수가 SW-MSA에 와서는 (3x3)으로 늘어났을 뿐만 아니라 크기가 MxM보다 작은 window들이 생긴 것을 확인할 수 있다) attention을 계산할 때 padding된 값들을 마스킹해줍니다. 하지만 window의 수는 여전히 늘어나게 되기 때문에 이러한 naive 접근으로 증가한 computation은 상당히 높습니다 ( (2x2) → (3x3) )

- •efficient batch computation for shifted configuration: 왼쪽 상단을 향해 cyclic하게 회전하기. shift 이후 배치 window는 feature map에서 인접하지 않은 여러 하위 window로 구성될 수 있으므로, self-attention 계산을 각 하위 window 내에서 제한하기 위해 마스킹 메커니즘이 사용됩니다. cyclic-shift를 사용하면 배치 window 개수가 regular window partitioning 때와 동일하게 유지되므로 효율적입니다.(low latency) 마스크 연산을 수행 후에 다시 원래 값으로 되돌립니다. ( reverse cyclic shift )
- window를 shift시키는데 이것을 cyclic shift라고 부릅니다. window size // 2 만큼 우측 하단으로 shift하고 A,B,C구역을 mask를 씌워서 self-attention을 하지 못하도록 합니다.
- 참고로 cyclic shift대신 padding을 사용해 마스킹을 대신할 수 있지만 저자들은 이 방법은 computation cost를 증가시키기 때문에 택하지 않았다고 합니다.
stage

stage1 : Linear embedding을 거쳐 C 차원으로 사영됩니다. 이렇게 형성된 patch 토큰들은 Swin Transformer block을 통과합니다.

stage2 : 계층적인 구조를 갖는 feature map을 생성하기 위해 patch merging 단계를 거칩니다. 여기에서는 ( 2x2 ) = 4 개의 patch들끼리 결합하여 하나의 큰 patch를 새로 만듭니다. patch는 합쳐지는 과정에서 차원이 4C로 늘어나기 때문에 linear layer를 통과하여 2C로 조정합니다.(feature transformation). 그리고 다시 Swin transformer block을 통과하며 self-attention 계산을 마칩니다.

stage 3,4 : Stage 2를 거치며 나온 output은 H/8 x W/8 x 2C 가 된다. 즉, patch size는 점점 커지고 수도 많아지며 각 토큰의 차원은 두 배씩 늘어갑니다. 이 절차는 Stage 3와 4에 걸쳐 두 번 반복된다. 이 단계들은 VGG나 ResNet과 같은 일반적인 CNN의 resolution과 동일한 feature map resolution으로 hierarchical representation을 만들어냅니다.
결과적으로, 제안된 아키텍처는 다양한 비전 task를 위한 기존 방법의 backbone network를 효과적으로 대체할 수 있습니다.
stage3,4 :

Experiments

- ImageNet dataset에 대해 ViT base model보다 파라미터 수는 훨씬 적지만 성능은 3.4%가 높습니다. (노란색)
- CNN기반 모델중 가장 SOTA model인 EffcientNet-B7 과 대등할 정도의 성능을 보였습니다. (하늘색)

다른 Task(Object Detection, Segmentation 등)의 backbone으로 사용했을때의 성능은 거의 다 SOTA를 찍은 것을 볼 수 있습니다.

SW-MSA없이 W-MSA만 사용했을때보다 둘다 사용했을때의 성능이 더 좋았고 abs positition embedding(기존에 사용하던 절대좌표) 과 relative postition embedding을 둘 다 쓰는 것 보다 relative postition embedding 하나만 사용하는 것이 제일 좋았다고 합니다.