
항상 헷갈리는 머신러닝
나만 그런건지 모르겠지만... 주기적으로 캐글 문제들을 풀지 않아서 그런걸까.
머신러닝의 프로세스를 대충 알고 있지만 어느 단계에서 어떤 방법을 사용해야 하는지 자꾸 까먹거나 헷갈릴 때가 많다.
중간 고사도 끝났고 kaggle 문제들을 본격적으로 풀기 전에 다시 한 번 머신러닝의 전체적인 프로세스를 쭉 학습하며
정리했다. 구글링을 해보면 정말 많은 레퍼런스가 있는데, 사실 사용하는 사람들마다 용어가 조금씩 다르기도 하고 순서도 제각각 다른 경우도 많다. 하지만 사용하는 사이킷런 코드나 큰 틀은 일관된 방향성을 갖는다.
이번 포스팅에서는 데이터 전처리에 대해 다룬다.
데이터 전처리는 주로 데이터 클리닝(Data cleaning) , 데이터 변형(Data Transformation), 피처 엔지니어링(Feature Engineering) 등 여러 단계로 나뉜다. 사실 이런 분류는 구분을 잘 하기 위해서 네이밍을 한 것 뿐이라고 느낀다.
똑같은 기법을 사람마다 다르게 분류하는 경우도 많기때문에.
그래서 기법을 분류한 이름에 집착하지 말고 전체적으로 어떤 단계를 반드시 거쳐야하며, 왜 해야 하는지 충분히 이해를 하면 도움이 될 것 같다. ( 나도 많이 헷갈린다 )

구글에서 Machine Learning 의 프로세스에 대한 레퍼런스를 엄청나게 찾아봤고 대충 필기를 한 결과.
앞서 언급했듯이 1~7번은 이름들에 집착하지 않고 데이터 전처리 단계에서 우리가 어떤 과정을 거쳐야 하는지 파악하면 된다.
우선 1번은 데이터 클리닝, 클렌징이라고 하며 데이터의 행(row)이나 열(column)을 제거하는 작업이다.
주로 pandas 를 활용한다. 데이터 프레임의 인덱싱을 자주 활용하니 이 부분에 대한 연습을 많이 해야한다.
각 메서드들에 대한 자세한 설명은 구글링으로 알 수 있다.
.loc , .iloc 을 이용하여 필요한 행과 열을 추출할 수 있다.
또한 필요없는 행이나 열을 없애기 위해서는 .drop 메서드를 이용한다.
데이터 프레임의 인덱싱에서 조건문을 활용하여 데이터를 추출할 수 있다. ex. df[df["컬럼" == 0]]
.value_counts() 는 Series 내부 각 값들의 빈도수를 나타낸다.
.info() 로 데이터의 결측값과 타입등 파악할 수 있다.

굉장히 줄여서 했지만, 여기에 쏟는 시간이 상당히 많다.
자세한 전처리 과정은 Kaggle 실습 포스팅을 하면서 올려야겠다.

데이터 전처리 과정을 정리하면서 가장 흥미롭게 생각했던 부분이다.
Outlier를 처리할 때 IQR(사분위수)를 사용한다는 것을 알고 있었지만, 실제로 사용을 해보면 정말 복잡하다.
통계적인 지식이 분명히 있어야한다. 이 부분은 따로 통계적인 내용과 함께 자세히 포스팅을 해야할 것 같다.
간단하게 이상치를 처리할 때는 IQR이라는 것을 사용해야 한다는 사실을 알고 넘어가자.
불필요한 feature 를 제거할 때는 사이킷런의 mutual_info_classif 를 사용한다.
사실 feature 를 튜닝하는 방법에는 정말 여러가지 기법들이 존재하죠. 가장 널리 사용하는 방식이 correlation cofficient (상관계수)를 구하는 방법.
mutual information 이라는 방법은 두 랜덤변수들이 얼마나 mutual dependence 한 지를 측정하는 방법을 의미한다.
만약 x,y가 독립이라면 p(x,y) = p(x)p(y) 로 주어진다.
Mutual information (MI)
[1]
between two random variables is a non-negative value, which measures the dependency between the variables. It is equal to zero if and only if two random variables are independent, and higher values mean higher dependency.
변수들 사이에 의존성을 측정하게 됩니다. 만약 이 값들이 0이면 두 개의 변수는 독립적이라고 할 수 있고 즉, 도움이 안된다는 의미입니다. 만약, 숫자가 크다면 어떤 의존성을 띈다는 것입니다. 여기서 2개의 변수는 x, y 의 값을 의미합니다.
이 라이브러리를 사용하려면 데이터의 결측이 존재하면 안됩니다.
++ 참고로 target 값이 이산형 변수인 경우 classif 를 사용하면 되지만 , 연속형 변수라면 mutual_info_regression 을 사용하면 됩니다.
그리고 흥미로웠던 점이 결측값을 처리하는 방법이다.
결측값을 처리하는 방법은 1,2 번처럼 평균값 , 중간값, 최빈값 등으로 대체하거나 누락을 시키는 방법만 사용했다.
하지만 결측값을 처리하는 방법은 굉장히 다양하다. 상황에 따라서, 데이터에 따라서 결측값을 대체하는 방법이 매우 상이했다.
결측값 처리 방법에 대해서는 따로 자세히 포스팅을 해봐야 할 것 같다.

마지막으로 머신러닝을 배울 때 가장 자주 들어본 정규화(Normalization)에 관련된 내용이다.
정규화는 min-max Normalization (최소 최대 정규화) 라는 방법과 Z-score ( Z 점수 정규화 ) 두 가지가 있다.
일반적으로 자주 사용하는 최소-최대 정규화 는 모든 피처에 대한 각각의 최소값 0, 최대값 1로 , 그리고 다른 값들은 0과 1사이의 값으로 변환한다.
z-score 는 표준화라고도 하며 이상치(outlier)를 해결하는 정규화 전략이다. 이상치를 잘 처리하지만 정확히 동일한 척도로 정규화 된 데이터를 생성하지는 않는다.
Feature selection 에 관련된 내용은 전 그림에서 다뤘는데 , 중요한 부분인 embedded method 를 기억해야한다.
embedded method는 내장 함수를 통해 피처를 선택하는 방식이다. 학습 모델 내부에서 자체적으로 특성을 선택할 수 있다.
L1 Norm - LASSO 모델
L2 Norm - RIDGE 모델
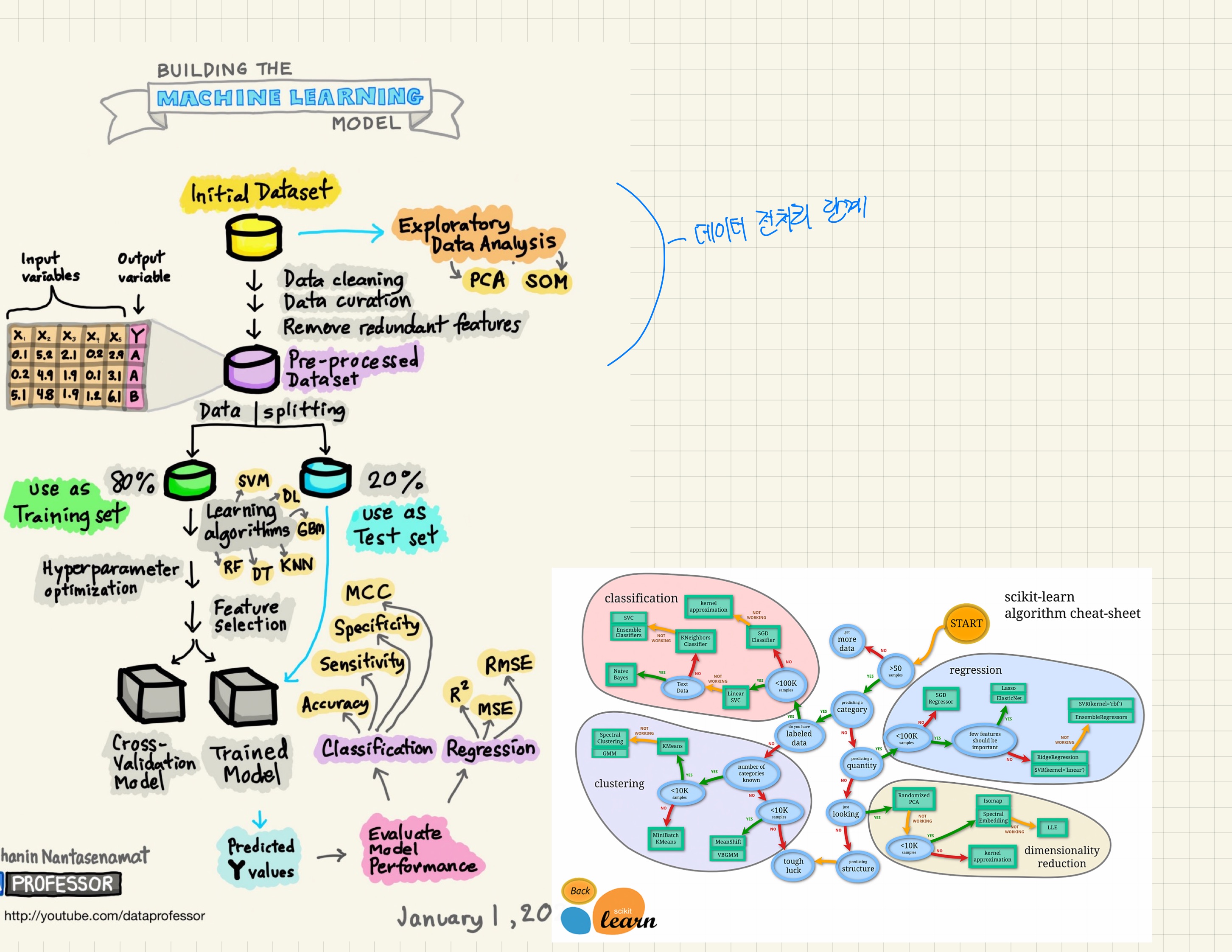
요약 - Summary
머신러닝과 딥러닝에 관한 디테일한 연구가 왜 그렇게 쏟아지는지 알 수 있었던 시간이었다.
데이터 전처리에서만 쓰이는 수많은 코드와 수식들만 봐도 정말 다양한 변수가 많다.
머신러닝에는 이런 말이 있다.
'모든 상황에 최적화된 방법은 없다.'
정말. 우리는 수많은 데이터들을 보고 알고있는 모델과 기법들을 최대한 잘 활용하여 분석을 진행해야 한다.
블록을 잘 조립하는 것처럼.
이번 포스팅 이후에는 머신러닝의 개별 모델들에 대한 포스팅(원래 하고 있던 회귀 모델 포함) 뿐만 아니라
데이터 전처리에서 사용하는 Missing Value (결측값 처리) 기법 , Feature selection 등 세부적인 분야들에 대해서 공부하고 포스팅해야지.
다음 포스팅에서는 모델의 검증과 평가(Validation & Evaluation)에 대해서 정리해보도록 하겠습니다.