
리스트와 딕셔너리
Python에서 반복적인 작업을 자동화 하고자 만들어진 가장 일반적인 방법은 리스트(list)타입을 쓰는 것입니다.
리스트는 아주 간편하며 다양한 문제를 해결하는 데 사용할 수 있습니다. 리스트를 자연스럽게 보완할 수 있는 타입이 딕셔너리(dict)타입 입니다. 딕셔너리 타입은 검색에 사용할 키(key)와 키에 연관된 값(value)를 저장합니다.
딕셔너리는(분할상환 복잡도로) 상수 시간에 원소를 삽입하고 찾을 수 있습니다. 따라서 동적인 정보를 관리하는 데는 딕셔너리가 가장 이상적이죠 ! 파이썬은 리스트와 딕셔너리를 다룰 때 가독성을 좋게 하고 기능을 확장해주는 특별한 구문과 내장 모듈을 제공합니다.
이로 인해 다른 언어가 제공하는 단순 배열, 벡터, 해시 테이블 타입보다 훨씬 더 편리하게 딕셔너리와 해시 테이블을 쓸 수 있습니다.
시퀀스를 슬라이싱 하는 방법 !
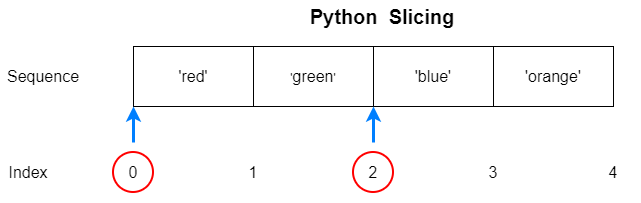
파이썬은 시퀀스를 여러 조각으로 나누는 슬라이싱(slicing)구문이 있습니다. 슬라이싱을 사용하면 최소한의 노력으로 시퀀스에 들어 있는 아이템의 부분집합에 쉽게 접근할 수 있습니다. 어떤 파이썬 클래스에서도 슬라이싱을 추가할 수 있죠.
`__getitem__` 과 `__setitem__` 특별 메서드를 구현하면 됩니다. 슬라이싱 구문의 기본 형태는 모두 알다시피 리스트[시작:끝] 이렇게 작성합니다. 여기서 시작 인덱스에 있는 원소는 슬라이스에 포함되지만, 끝 인덱스에 있는 원소는 포함되지 않습니다 !
a = ['a','b','c','d','e','f','g','h']
print("가운데 2개:", a[3:5])
print("마지막을 제외한 나머지:", a[1:7])>>>
가운데 2개: ['d', 'e']
마지막을 제외한 나머지: ['b', 'c', 'd', 'e', 'f', 'g']
리스트의 맨 앞부터 슬라이싱할 때는 시각적 잡음을 없애기 위해 0을 생략해야 합니다.
assert a[:5] == a[0:5]
리스트의 맨 앞부터 슬라이싱할 때는 시각적 잡음을 없애기 위해 0을 생략합니다.
a[:] # ['a','b','c','d','e','f','g','h']
a[:5] # ['a','b','c','d','e']
a[:-1] # ['a','b','c','d','e','f','g']
a[4:] # ['e','f','g','h']
a[-3:] # ['f','g','h']
a[2:5] # ['c','d','e']
a[2:-1] # ['c','d','e','f','g']
a[-3:-1] # ['f','g']
위의 슬라이싱에는 놀랄 만한 부분이 없습니다. 저도 위의 슬라이싱을 가장 자주 사용합니다 :)
슬라이싱할 때 리스트의 인덱스 범위를 넘어가는 시작과 끝 인덱스는 조용히 무시됩니다.
이런 동작 방식으로 인해 코드에서 입력 시퀀스를 다룰 때 원하는 최대 길이를 쉽게 지정할 수 있습니다 !
first_twenty_items = a[:5]
last_twenty_items = a[-5:]
리스트를 슬라이싱한 결과는 완전히 새로운 리스트이며, 원래 리스트에 대한 참조는 그대로 유지됩니다.
슬라이싱한 결과로 얻은 리스트를 변경해도 원래 리스트는 바뀌지 않습니다.
b = a[3:]
print("이전:", b)
b[1] = 99
print("이후:", b)
print("원본:", a)
>>>
이전: ['d', 'e', 'f', 'g', 'h']
이후: ['d', 99, 'f', 'g', 'h']
원본: ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
대입에 슬라이스를 사용하면 원본 리스트에서 지정한 범위에 들어 있는 원소를 변경합니다.
언패킹 대입(예를 들면, a,b = c[:2])과 달리 슬라이스 대입에서는 슬라이스와 대입되는 리스트의 길이가 같을 필요가 없습니다.
대입된 슬라이스 이전이나 이후에 있던 원소들은 그대로 유지됩니다.
다음 코드에서는 리스트에 지정한 슬라이스 길이보다 대입되는 배열의 길이가 더 짧기 때문에 리스트가 줄어듭니다.
print('이전', a)
a[2:7] = [99, 22, 14]
print('이후', a)
>>>
이전 ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
이후 ['a', 'b', 99, 22, 14, 'h']
다음 코드에서는 리스트에 지정한 슬라이스 길이보다 대입되는 배열의 길이가 더 길기 때문에 리스트가 늘어납니다.
print('이전', a)
a[2:3] = [47, 11]
print('이후', a)
>>>
이전 ['a', 'b', 99, 22, 14, 'h']
이후 ['a', 'b', 47, 11, 22, 14, 'h']
슬라이싱에서 시작과 끝 인덱스를 모두 생략하면 원래 리스트를 복사한 새 리스트를 얻게됩니다.
b = a[:]
assert b == a and b is not a
시작과 끝 인덱스가 없는 슬라이스에 대입하면(새 리스트를만들어내는 대신) 슬라이스가 참조하는 리스트의 내용을 대입하는(연산자 오른쪽에 있는) 리스트의 복사본으로 덮어 쓰게 됩니다.
b = a
print('이전', a)
print('이전', b)
a[:] = [101, 102, 103]
assert a is b # 여전히 같은 리스트 객체
print('이후', a) # 새로운 내용이 들어있음
print('이후', b) # 동일한 리스트 객체를 참조하고 있음>>>
이전 ['a', 'b', 47, 11, 22, 14, 'h']
이전 ['a', 'b', 47, 11, 22, 14, 'h']
이후 [101, 102, 103]
이후 [101, 102, 103]
Summary
- 슬라이싱은 간결하게 하자. (시작 인덱스에 0을 넣거나 끝 인덱스에 시퀀스 길이를 넣지 말자)
- 슬라이싱은 범위를 넘어가는 시작 인덱스나 끝 인덱스도 허용한다.
- 리스트 슬라이스에 대입하면 원래 시퀀스에서 슬라이스가 가리키는 부분을 대입 연산자 오른쪽에 있는 시퀀스로 대치한다. 이때 슬라이스와 대치되는 시퀀스의 길이가 달라도 된다.
Python 추가 문제 팁
아래의 코드는 Python에서 map() 함수와 lambda 함수를 사용하여 리스트의 각 요소를 제곱하는 예제입니다.
squared_numbers 에서 map() 함수를 사용하여 numbers 리스트의 각 요소에 함수를 적용합니다.
map() 함수와 lambda 함수를 사용하면 리스트의 각 요소에 함수를 적용할 때 간결하고 읽기 쉬운 코드를 작성할 수 있습니다.
이 예제에서는 제곱 연산을 수행했지만, lambda 함수를 수정하여 다른 연산을 적용할 수도 있습니다.
numbers = [1,2,3,4,5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers)