
Kaggle 에서 최대한 많은 데이터 세트로 EDA 를 연습하고 있습니다.
pandas , numpy , matplotlib, seaborn 등 데이터 분석에 기본이 되는 라이브러리들을 체화시키기 위해 노력하고 있지만
확실히 자유자재로 활용하려면 매일 해야할 것 같네요.
매주 주말에는 제가 분석하면서 어렵거나 헷갈릴만한 부분을 정리해볼까 합니다.
Dataset : Kaggle에서 가져온 carclaims.csv

당연히 데이터 분석을 할 때의 시작은 데이터세트를 가져오는 것이죠 .
df 변수에 "carclaims.csv"를 담아줍니다.
pandas 라이브러리의 read_csv 메서드를 통해 다운받은 csv 파일을 가져올게요.
가져온 데이터 파일 ( 이하 df ) 는 df.head() 처럼 상위 몇 개의 데이터만 확인할 수도 있고 그냥 변수 이름을 프린팅( df ) 하여 전체 데이터를 확인할 수 있습니다.
중요한 부분은 아니니 넘어갈게요.

그 다음으로 제가 중요하게 생각하는 과정 중 하나인 info() 메서드 활용입니다.
info() 메서드는 데이터에 대한 전반적인 정보를 알려주는데요 , 저는 주로 결측값과 데이터 타입을 확인할 때 사용합니다.
info() 의 출력값을 보시면 non-null count 라는 부분이 바로 결측값을 확인하는 부분인데요
df.shape 를 통해서 df 의 전체 데이터 개수와 non-null count 값을 비교해보시면 어떤 칼럼에서 결측값이 있는지 확인할 수 있습니다.
총 데이터의 개수는 15420개인데 , 위의 출력 결과를 보시면 모든 컬럼의 값들이 15420 이므로 결측값은 없다고 판단할 수 있겠네요!
결측값을 처리하는 다양한 방법 - Netflix dataset
만약 결측값이 확인되었다면 항상 그 결측값들을 처리해줘야 합니다.
'처리' 한다는 것은 결측값을 제외하고 계산하거나 결측값을 다른 유의미한 값으로 채워넣는 것입니다.
결측값을 왜 처리해줘야 할까요?
저희는 결국 숫자로 모든 것들을 결정하기 때문에 그 숫자들의 공백이 크거나 이상이 있다면 마지막 결론에 문제가 생길거에요.
그렇기 때문에 늘 결측값을 어떻게 처리하는지 고민해봐야 합니다. :)

이번 코드는 netflix 데이터 셋에서 결측값을 처리하기 전 단계인데요.
여기서는 for 반복문을 사용해서 null_rate 라는 변수에 결측값이 해당 칼럼에서 비중이 얼마나 되는지 구합니다.
코드를 보시면 df.columns 로 칼럼 값들을 하나씩 가져오고 난 후
그 칼럼을 df의 인덱스로 받아 결측값의 합을 구합니다.
* isna() -> DataFrame 내의 결측값을 확인해서 bool 형식으로 ( True or False ) 반환하는 메서드입니다.
결측값들의 총 개수에서 df의 총 개수 곱하기 100을 나누면
df에서 결측값이 차지하는 비율이 구해지겠죠??

결측값 비율이 높은 칼럼들을 처리해줍시다.
country 칼럼은 fillna() 메서드로 채워줄게요.
* fillna() -> 파라미터 값으로 결측값을 채워줌. 위의 예시에서는 df의 'country' 칼럼의 중위수의 0번 째 데이터로
그리고 cast 와 director 의 결측치는 No Data 라는 문자열로 채우게됩니다.
df.dropna 를 통해서 결측치들을 계산에서 제외하도록 하구요
df.drop_duplicates 에서 drop_duplicates 는 중복값을 처리하는 메서드에요.
unique 한 1개의 key만 남기고 나머지 중복은 제거를 하는 메서드 입니다.
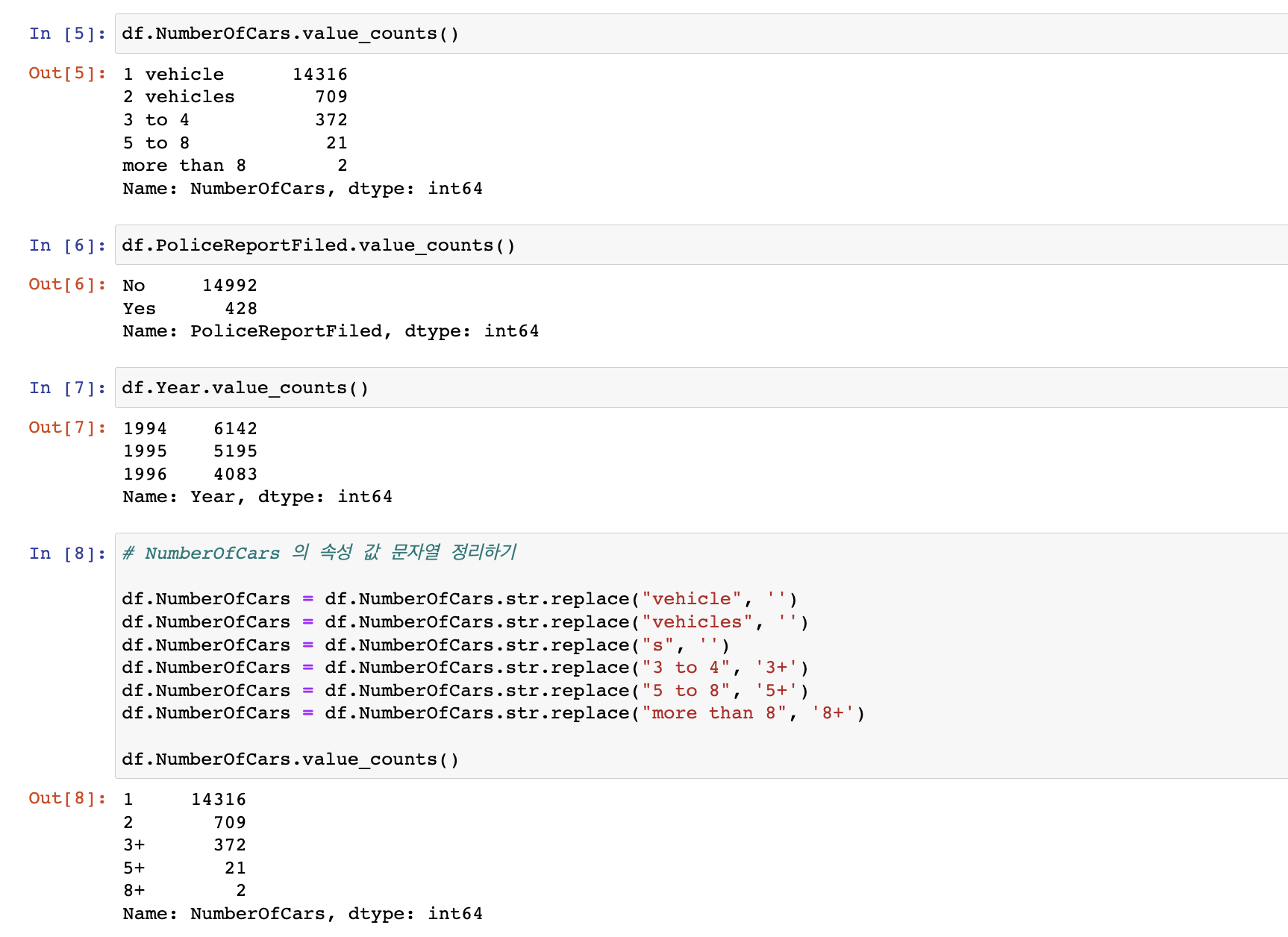
이후로 궁금한 컬럼들을 여러가지 메서드들로 확인합니다.
* value_counts() 와 value_counts 의 차이
→ value_counts() 는 열의 각 값에 대한 모든 발생 횟수 반환
→ value_counts 는 각 인덱스에 어떤 값이 있는지 반환

Heatmap
seaborn 의 heatmap 은 컬럼간 상관관계를 시각화하는데 유용하게 쓰입니다.
heatmap 의 annot 옵션에 True를 설정하게 되면 그래프 내부에 상관계수를 나타내줍니다.
cmap 은 colormap 이라고 불리며 히트맵의 색상을 지정할 수 있습니다.