
머신러닝 (Machine Learining) 은 선형대수와 통계 등에 기반하여 알고리즘을 만들게 됩니다.
특히 선형대수는 공학에서 정말 널리 사용되고 있으며 머신러닝을 학습하고자 하시는 분들은 기초적인 선형대수를 꼭 알고 계시는 것이 좋습니다.
저도 비전공자 + 수포자로서 선형대수를 이해하는 것이 너무너무 어렵습니다. ㅎㅎ
'프리드버그 선형대수학' 이라는 책을 사서 공부하려고 했지만 벡터의 기본도 모르는 제가 이해할 수 없었죠.
아예 처음부터 수학을 다 배우려면 시간도 너무 많이 소비되고 어차피 까먹을 것을 알기에
탑다운 방식으로 학습을 하고 있습니다.
일단 머신러닝과 딥러닝에서 자주 쓰이는 수학적 개념만 확실히 학습할 계획입니다.
수학을 다뤄야 하는 라이브러리도 많기 때문에 프로그래밍을 하면서 함께 공부하면 좋을거 같습니다.
수학적인 개념이 프로그래밍에서 어떤 식으로 알고리즘을 형성하는지 천천히 이해하는 것이 많은 도움이 되어서
누군가가 볼 수도 있는 블로그를 시작합니다.
그럼 시작하겠습니다 !!
Numpy - Numerical Python
넘파이(numpy)는 파이썬에서 선형대수 기반의 프로그램을 쉽게 만들 수 있도록 지원하는 대표적인 패키지입니다.
루프를 사용하지 않고 대량 데이터의 배열 연산을 가능하게 하므로 매우 빠른 배열 연산 속도를 보장합니다.
넘파이는 C/C++ 와 같은 저수준 언어 기반의 호환 API를 제공합니다.
파이썬 언어 자체가 가지는 수행 성능의 제약을 보완하기 위해 C/C++ 기반의 코드로 작성하고 이를 넘파이에서 호출하는 방식으로 쉽게 통합할 수 있습니다.
넘파이를 너무 상세하게 학습할 필요는 없습니다.
넘파이 자체가 매우 방대한 기능을 지원하고 있기에 이를 마스터하는 것은 딱히 큰 의미가 없을 뿐더러 상당한 시간과 코딩 경험이 뒷받침 되어야 하죠.
하지만 넘파이를 이해하는 것은 파이썬 기반의 머신러닝에서 상당히 중요합니다.
캐글(Kaggle)과 같은 커뮤니티에서 개발자들이 직접 짠 머신러닝 코드들을 보시면 넘파이는 판다스(Pandas)와 더불어서 가장 자주 쓰이는 것을 보실 수 있습니다. 많은 머신러닝 알고리즘이 넘파이 기반으로 작성돼 있음은 물론이고, 이들 알고리즘의 입력 데이터와 출력 데이터를 넘파이 배열 타입으로 사용하기 대문입니다.
또한 넘파이가 배열을 다루는 기본 방식을 이해하는 것은 판다스를 이해하는 데도 많은 도움을 줄 것입니다.
# 1. 넘파이 ndarry 개요.
What is Numpy?
- Numercial Python을 의미하는 넘파이는 파이썬에서 선형대수 기반의 프로그램을 쉽게 만들 수 있도록 지원하는 대표적인 패키지.
- 편의성과 다양한 API 지원 측면에서 아쉬움이 있기에, 데이터 핸들링은 판다스(Pandas) 라이브러리 활용.
- 매우 방대한 기능 - 파이썬에 대한 깊은 이해가 필요. 넘파이를 이해하는 것은 파이썬 기반의 머신러닝에서 매우 중요

먼저 numpy 모듈을 사용하기 위해서 import 하겠습니다.
저는 주피터 노트북 (Jupyter Notebook) 환경에서 실습을 진행했습니다.
주피터 노트북이 설치 안되신 분이라면 구글 colab에서 실습을 하셔도 무관합니다.
넘파이의 기반 데이터 타입은 ndrarry 입니다.
ndarry를 이용해 넘파이에서 다차원 배열을 쉽게 생성하고 연산할 수 있습니다.
넘파이의 array() 함수는 파이썬의 리스트(list)와 같은 다양한 인자를 입력 받아서 ndarry로 변환하는 기능을 수행합니다.

np.array() 의 사용법은 매우 간단합니다.
ndarray로 변환을 원하는 객체를 인자로 입력하면 ndarray를 반환합니다.
array1,2,3 이라는 변수를 생성하고
np.array()를 생성하여 데이터의 타입과 출력값을 확인합니다.
array1 의 shape 은 (3,) 입니다.
이건 무슨 뜻일까요??
이는 1차원 array로 3개의 데이터를 가지고 있음을 뜻합니다.
그러면 array2의 [[1,2,3],[2,3,4]] 는 어떤 shape을 하고 있을까요??
(2,3) 입니다 !!
이는 2차원 array로 , 2개의 로우와 3개의 컬럼으로 구성되어 2 * 3 = 6개의 데이터를 가지고 있음을 뜻합니다.
그렇다면 array3는 어떤 shape일지 생각해보세요 !
#2. ndarray의 데이터 타입 ( type)
ndarray내의 데이터 값은 숫자, 문자열, 불 값등 모두 가능합니다.

중요한 포인트는 ndarray내의 데이터 타입은 그 연산의 특성상 같은 데이터 타입만 가능합니다.
즉 , 한 개의 ndarray 객체에 int와 float이 함께 존재할 수 없습니다.
#1 에서 사용한 dtype으로 ndarray내의 데이터 타입을 확인할 수 있습니다.
#2 에서는 문자열과 숫자를 함께 넣은 List2의 출력값을 보시면 됩니다.
ndarray 객체에는 같은 데이터 타입만 존재할 수 있으므로 문자열과 데이터가 섞이게 되면
데이터 타입이 더 큰 데이터 타입으로 변환되어 int형이 유니코드 문자열 값으로 변환되었습니다.
1, 2 >>> '1', '2'
int형과 float형이 섞여 있는 list3의 경우도 int1,2가 모두 1. , 2. 으로 변환됐습니다.
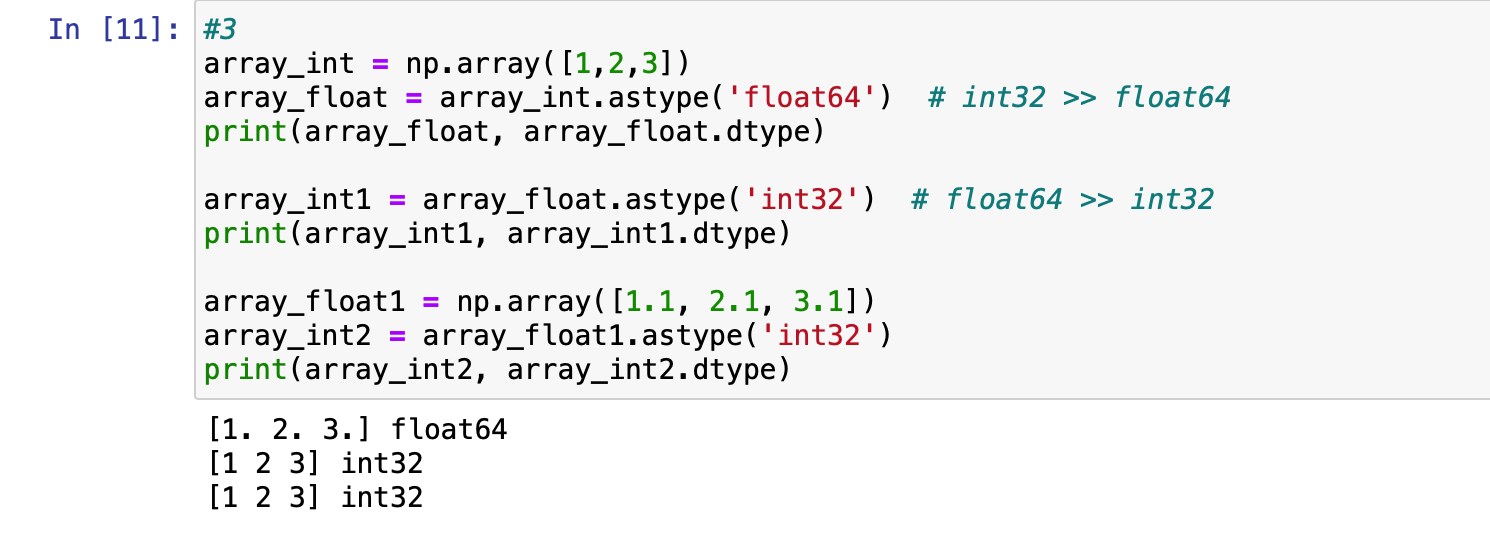
astype() 매서드를 이용하여 ndarray 내 데이터값의 타입 변경도 가능합니다.
astype()에 인자로 원하는 타입을 문자열로 지정하면 됩니다.
그러면 어떤 경우에 데이터 값을 변경할까요 ??
머신러닝 알고리즘은 대부분 메모리로 데이터를 로딩하여 알고리즘을 적용하기 때문에 대용량의 데이터를 로딩할 때는 수행속도가 느려지거나 메모리 부족으로 오류가 발생할 수 있습니다.
이런 경우 메모리 절약을 위해 더 작은 크기의 데이터 타입으로 변경을 해주는 것이 좋습니다 :)
# ndarray를 편하게 생성하기 - arange, zeros, ones
특정 크기와 차원을 가진 ndarray를 연속값이나 0또는 1로 초기화해 쉽게 생성해야 할 필요가 있는 경우 ( 주로 테스트용이나 대규모 데이터를 전체 초기화 할 경우 ) 에 사용됩니다.

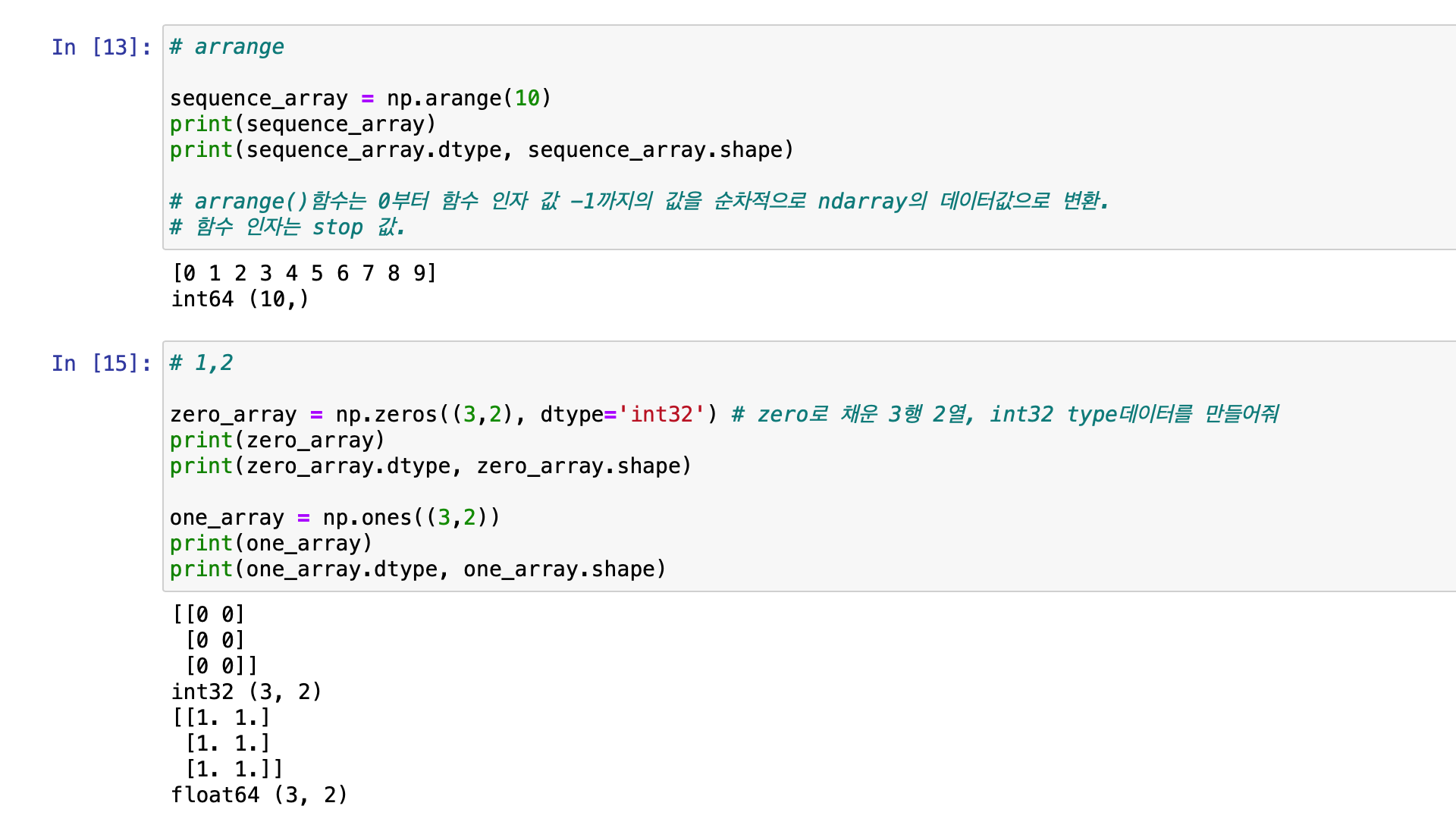
arrange() 함수는 굉장히 쉽게 이해하실 수 있습니다.
arrange(10) 은 0부터 인자(=10) - 1 까지의 값을 순차적으로 ndarray의 데이터값으로 변환해 줍니다.
np.zeros()는 함수 인자로 튜플 형태의 shape값을 입력하면 모든 값을 0으로 채운 해당 shape를 가진 ndarray를 반환합니다.
np.ones()도 마찬가지로 모든 값을 1로 채운 해당 shape를 가진 ndarray를 반환합니다.
# ndarry의 차원과 크기를 변경하는 reshape()

reshape() 매서드는 ndarray를 특정 차원 및 크기로 변환합니다.
array2를 보시면 reshape 인자에 2,5가 부여됐습니다.
이는 2 로우 x 5 칼럼으로 변환해달라는 요청을 수행합니다.
당연한 얘기지만, reshape() 는 지정된 사이즈로 변경이 불가능하면 오류가 발생합니다.
가령 (10,) 데이터를 (4,3) 형태로 변경할 수는 없습니다.

#2 에서 reshape() 에 -1을 인자로 넣어주는 경우가 있는데요, -1을 인자로 사용하면
원래 ndarray와 호환되는 새로운 shape로 변환해 줍니다.
array1은 1차원 ndarry로 0~9까지의 데이터를 가지고 있습니다.
array2는 array1.reshape(-1,5)가 적용되어
로우 인자가 -1, 칼럼 인자가 5입니다. 이것은 array1과 호환될 수 있는 2차원 ndarray로 변환하되, 고정된 5개의 칼럼에 맞는 로우를 자동으로 새롭게 생성해 변환하라는 의미이죠.
즉 , 10개의 1차원 데이터와 호환될 수 있는 고정된 5개 칼럼에 맞는 로우 개수는 2이므로 2x5의 2차원 ndarray로 변환하는 것입니다.
reshape()에 -1인자를 적용하는 것은 reshape(-1,1)과 같은 형태로 자주 사용됩니다.
reshape(-1,1)은 원본 ndarray가 어떤 형태라도 2차원이고, 여러 개의 로우를 가지되 반드시 1개의 칼럼을 가진 ndarray로 변환됨을 보장합니다.
최대한 쉽게 설명하려고 노력했는데 도움이 되셨으면 좋겠습니다 :)
다음 포스팅에서는 넘파이의 인덱싱(indexing)과 선형대수의 연산에 대해서 학습한 내용을 정리하겠습니다.
감사합니다 :)
출처,참고 - 파이썬 머신러닝 완벽 가이드 , 권철민