
2022년 Lecture Notes in Computer Science 학회에 게재된 논문입니다.
NVIDIA 팀에서 개발하고 UNETR에 Swin Transformer를 적용한 모델을 제안하였습니다.
이 모델은 Brain Tumor Segmentation task에서 SOTA를 기록했습니다.

Brain Tumor Segmentation은 다양한 Scanner로 뇌를 촬영한 3d input을 받아 Brain Tumor을 Segmentation하는 Task입니다. Input 그림에서도 보다시피 뇌에 대한 MRI 사진이 Flair, t1, t1ce 등 서로 다른 스캐너와 프로토콜을 통해 출력되었습니다. 이런 이미지를 Multi-Modal Image라고 표현하기 때문에 이 분야는 Multi Modal DL 이라고 표현할 수 있습니다.

Output 결과를 보면 각 채널별로 Brain Tumor의 범주에 대해 Segmentation Map을 예측한 것을 확인할 수 있습니다. 또한 input과 output에 대한 그림이 2D로 표현이 됐는데, 실제로는 3D Input과 Output을 처리합니다. 따라서 input에는 flair, t1, t1ce, t2가 각각 D개만큼 존재하고, output도 ET,WT,TC에 대한 segmentation map이 D개만큼 존재합니다.
Brain Tumor를 다루는 주된 데이터셋은 BraTS라고 하고, 이 데이터셋은 Brain Tumor의 세 가지 범 주를 다루고 있습니다. 오른쪽 큰 사진이 실제 데이터셋에서 제공하는 범주이며 Edema, Enhancing, Tumor, Necrosis를 다루고 있습니다.
ED는 뇌종양이 넓게 분포되어 있는 형태고, ET는 고리형태이거나 속이 빈 형태입니다다. NCR같은 경우 ET 근처에 속이 채워진 채로 존재한다.
그런데 실제로 Segmentation을 할 때는 왼쪽 여섯 개의 그림과 같이 ET, TC, WT로 범주를 나눈다고 합니다.
ET는 그대로이고, TC는 NCR과 ET를 합친 영역이며, WT는 모든 범주를 포함하고 있다고 생각하면 됩니다.
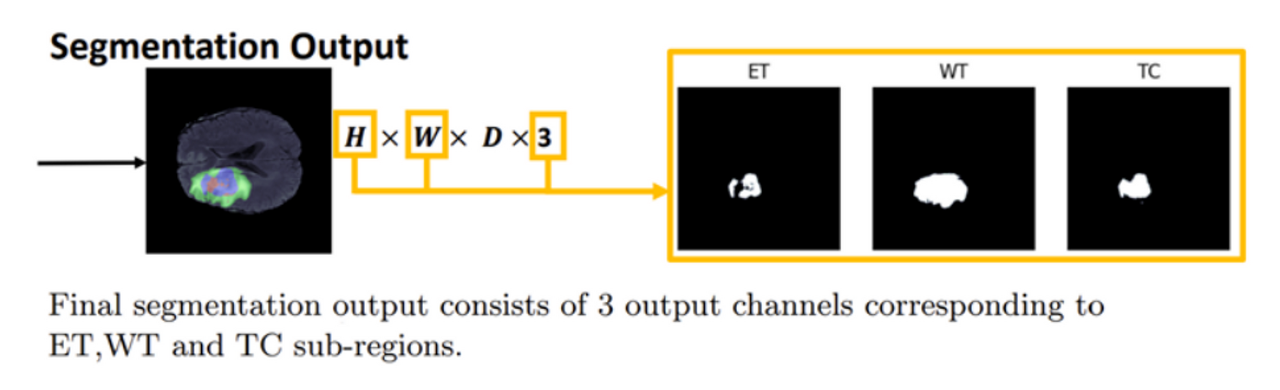
실제 학습시 ET, TC, WT를 사용한다고 합니다. 딥러닝 모델에서는 ET WT TC 의 세 범주에 대응되는 세 개의 채널을 가지는 Segmentation Output을 생성합니다. Brain Tumor Segmentation은 각 채널 별로 Pixel별 Tumor를 예측하는 Task입니다.
Architecture
UNETR
- 3D UNET의 수축 경로를 Transformer 구조로 대체한 모델입니다.
Swin UNETR의 모델 아키텍쳐를 알아보기 전에 UNETR과 Swin Transformer에 대해 간단히 짚고 넘어가겠습니다. 먼저 UNETR은 3D UNET의 수축 경로를 Transformer 구조로 대체한 모델입니다. 수축 경로는 원래 Feature Map의 Resolution이 1/2 씩 줄어야하지만 Transformer의 특성 상 Input과 Output Shape이 같으므로 수축된 Shape도 일정합니다. 그런데 확장 경로에서는 기존 모델과 똑같이 Upsampling을 해나가기 때문에, Skip Connection 단계에서 Shape를 맞추기 위해 서로 다른 Deconvolution을 사용합니다.
가장 윗 단계에서는 Deconv를 세 번 실행하고 가장 아래 단계에서는 Deconv를 한 번만 실행합니다.
이 모델은 Transformer의 Attention 연산을 통해 Global 정보를 더 잘 획득하므로, 넓게 분포된 Tumor 영역도 잘 예측할 수 있다는 장점을 지닙니다.
Swin Transformer
Swin Transformer의 가장 큰 특징은 Transformer Encoder를 계층적으로 쌓았다는 것입니다.
따라서 FPN(Feature Pyramid Network)처럼 계층에 따라 다른 특징을 지니고 있는데, Low Stage에서는 Patch 사이즈를 작게하고, 이러한 작은 Patch들로 이루어진 윈도우 내부에서 Attention을 진행하기 때문에 지역적 정보를 획득할 수 있습니다.
반대로 High Stage에서는 Patch 사이즈를 크게 하는 전략을 해서 Global Attention(큰 영역에 서의 Attention)을 통한 전역적 정보를 획득할 수 있게 하였습니다. 반면, 기존의 ViT는 항상 Global Attention만 하기 때문에 Local 정보를 획득하기에는 Swin이 훨씬 좋습니다.
또한 윈도우 내부에서만 Attention을 하면, 윈도우가 겹치는 구간에서는 특징을 찾을 수 없기 때문에, Shifted Window라는 알고리즘을 통해 윈도우 간 어텐션도 진행하였습니다. 따라서 기존 ViT 대비 Local과 Global 정보를 효율적으로 획득할 수 있게 한 모델이라고 생각하 면 됩니다.

Swin UNETR은 UNETR의 수축 경로에서 Swin을 적용한 모델입니다. Swin은 Patch Merging이라는 기 술이 있기 때문에 각 Stage별로 Output Resolution이 줄어듭니다. 따라서 별도의 Deconv작업없이 Skip Connection이 가능합니다.
그런데 이 논문에서는 ResBlock을 한 번 더 거친 구조를 사용합니다. 그래서 이 모델은 Swin을 사용했기 때문에, UNETR보다 Local 정보를 더 잘 활용하므로 더욱 정교한 Segmentation이 가능하다는 장점이 입니다. (물론 Global 정보도 유지한채로 Local정보를 활용할 수 있다는 의미)
Contracting Path ( 수축경로 )

- 점진적으로 넓은 범위를 보며 Feature들을 추출하는 경로 ( Local Feature → Global Feature )
- Swin Transformer를 사용하며 Output Shape이 2배씩 작아짐.
수축경로라고 불리는 구간은 점진적으로 이미지의 넓은 범위를 보며 Feature를 추출합니다.
stage1에 가까울수록 Local Feature를 추출하며 Stage4에 가까울수록 Global Feature를 추출합니다. Swin Transformer를 사용하였으며 기존 CNN과 마찬가지로 Output Shape는 2배씩 작아집니다.
Bottle Nect & Connection
- 수축 경로에서 확장 경로로 전환 및 연결되는 구간
- Instance Normalization → Two 3x3x3 Conv Layers 로 구성된 Res-Block을 거침

Bottle Neck과 Connection은 각각 수축 경로에서 확장 경로로 전환되는 구간, 연결되는 구간으로, 수축 경로에서 나온 Feature를 확장 경로로 전달하는 역할을 합니다. 논문에서는 단순히 전달하지 않고 Instance Normalization 과 두 개의 3x3x3 Conv layer를 거치는 Res-Block을 추가했습니다.
여기서 Instance Normalization이란 평균과 표준편차를 구할 때 batch와 channel과는 무관하게 구한 뒤 표준화를 하는 것을 의미합니다. ( Transformer에서는 Layer Norm을 채택하므로 Batch와 무관하게 평균과 표준편차를 구합니다 )
Expanding Path(확장경로)
- global feature를 앞 단의 Local Feature들과 차례차례 결합하는 경로
- Deconvolution과 Res-Block을 사용하며 Output Shape이 2배씩 커짐

확장 경로는 Bottleneck Feature로부터 얻은 Global정보에 앞 단(윗 단)의 Local Feature들을 차례 차례 결합하는 경로입니다. 이 때 결합을 위해 Shape을 맞춰주기 위해서 Deconvolution을 진행합니다. 또한 Res-Block을 사용하며 특징을 다시 한 번 추출한다. 확장 경로의 초반에는 Global Feature정 보만 다시 추출하게 되지만, 후반으로 갈수록 Global에 점점 더 정교한 Local Feature들이 결합되 면서 Global과 Local 정보가 적절하게 담긴 Feature Map을 형성할 수 있습니다.
아래는 yolo v3 리뷰했을 때 FPNs를 계산했던 그림입니다.
Method
Patch Partition & Linear Embedding
- Patch Partition : Input을 크기가 P인 패치들로 분할 후 변환하는 과정 ( Pixel → Patch )
- Linear Embedding : 채널축을 C로 재구성하는 과정 ( 벡터의 차원이 C가 되는 과정 )
- 논문에서 초기 패치 크기(P)는 2, C는 48로 주어짐

Patch partition과 Embedding은 Swin Block에 들어오기 전에 거치는 과정입니다.
Patch partition은 입력값을 크기가 P인 패치들로 분할 후 변환하는 과정으로 입력값의 각 원소가 pixel이라면 이것을 Patch 기준으로 변환시키는 것입니다.
예를 들어32x32x32인 입력은 2x2x2 패치가 width, height, dimension 방향으로 각각 16개있다고 생각할 수 있습니다.
따라서 Patch기준으로 Reshape하면 16x16x16이 되는 것이고, Resolution과 Dimension이 줄 어든 대신 채널인 S가 늘어나므로 S는 4에서 4 곱하기 2의 3제곱이 된다. 또한 여느 Transformer와 다를 바 없이 Embedding을 진행해서 채널을 C로 재구성한다고 한다. 논문에서 C는 48로 주어진다.
Patch Merging
- 이웃한 2x2x2 패치들을 하나의 패치로 재구성하는 과정
- Linear 연산을 통해 차원 수를 2C로 변경 → Resolution과 Dimension은 2배만큼 감소되고, Channel은 2배만큼 증가되는 구조
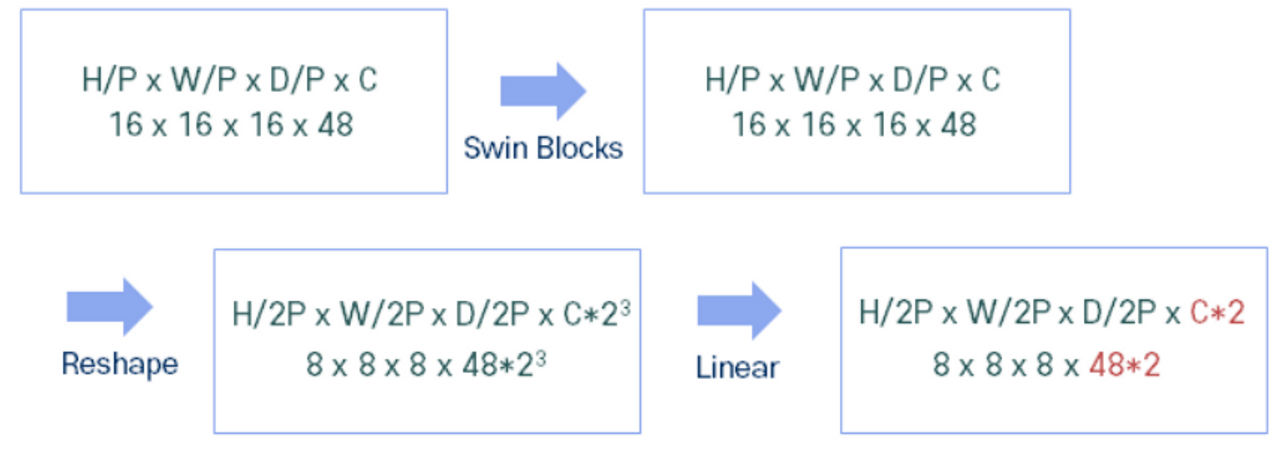
Patch Merging은 이웃한 2x2x2 패치들을 하나의 패치로 재구성하는 과정입니다. 따라서 16x16x16인 Shape은 8x8x8이 됩니다. Patch Partion과 마찬가지로, Resolution과 Dimension이 줄어든 대신 채널인 C가 늘어나므로 C는 48에서 48*23이 된다. 또한 Linear 연산을 통해 채널은 2C로 다시 변경됩니다.
Window MSA & Shifted Window MSA
- Layer 1은 W-MSA를 진행, Layer l+1은 SW-MSA를 진행합니다.
- (M/2 , M/2, M/2) voxel를 이용해서 3D cyclic-shifting를 진행합니다.
Voxel이란 2D 이미지를 구성하는 최소 단위인 pixel(picture element)을 3D로 확장한것입니다.
→ (2,2,2), (2,4,2) (4,4,2) 등의 Shape로 이루어진 윈도우들 ( 3x3x3 )을 Reshape 해서 Attention 하지 않으니 연산량이 낮아짐

처음 Input이 32x32x32라고 가정했기 때문에, 이 그림은 Swin의 stage2인 8x8x8(patch partion과 patch merging을 한 번씩 거친 상태)이라고 생각하면 편합니다.
Layer l 그림을 보면, 이전에 8x8x8개의 패치들이 크기가 4인 윈도우들로 재구성이 되서, 윈도우가 총 2x2x2개 만들어진 상태이고, 각 윈도우 내에서 어텐션을 진행하겠다는 의미입니다.
Layer l+1에서는 width, height, dimension기준으로 각각 윈도우 개수를 한 개씩 늘려서 크기가 제 각각인 윈도우가 총 3x3x3개 만들어지는데, 이렇게 윈도우를 늘리는 이유는 layer l에서 윈도우끼 리 겹치는 부분은 어텐션을 계산할 수 없었기 때문입니다.
그러나 진짜 이 27개의 윈도우에 대해 어텐션 연산을 모두 진행하면, 크기가 제각각인 윈도우들을 다시 (4,4,4)로 Reshape해야 되기 때문에 연산량이 엄청나게 늘어난다. 따라서 크기가 (M/2,M/2,M/2)인 Voxel(윈도우)을 우측 하단으로 Shift시키는 방식으로 결국 Layer l과 같은 Shape을 구성한다. 그럼 결국 크기가 (4,4,4)인 윈도우 8개로 어텐션을 진행할 수 있는 것입니다.
Swin Transformer Blocks
- 윈도우 내 어텐션(W-MSA)과 윈도우 간 어텐션(SW-MSA)을 순차적으로 수행하는 구조
- 원본 Transformer와 달리 LayerNorm을 먼저 수행
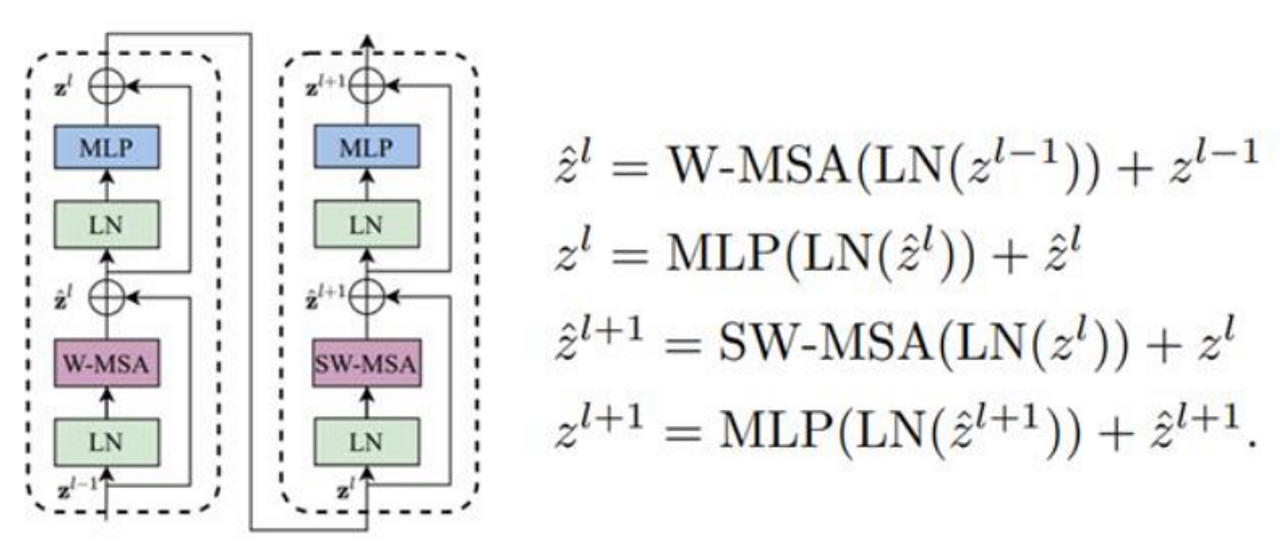
앞서 설명한 W-MSA와 SW-MSA를 다루는 모듈이 Swin Transformer Blocks입니다. 이 Blocks은 두 개의 Block으로 구성되며 한 개는 W-MSA를 하고 한 개는 SW-MSA를 합니다. 또한 수식을 보면 원본 Transformer와 달리 LayerNorm을 먼저 수행한다는 점에서 차이가 있습니다.
Residual Block
- Res-Block은 전환 구간, 연결 구간, 확장 경로에 사용
- Instance Normalization Layer와 두 개의 3x3x3 Conv Layer로 구성됩니다.

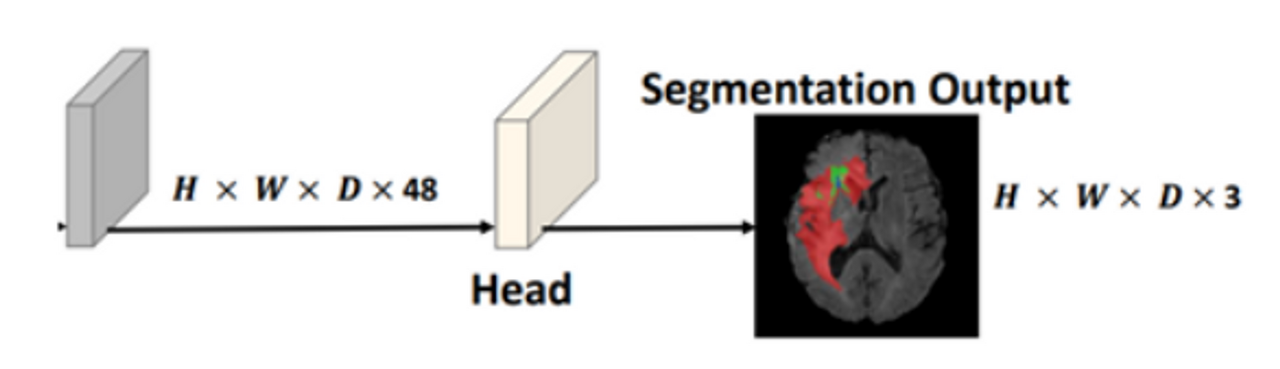
Final Segmentation Output
- Head는 1x1x1 Convolution으로 이루어짐
- 이후 Sigmoid Activation Function을 이용합니다. ( 0 ~ 1 사이의 값으로 예측 )
Res-Block은 Instance Normalization Layer와 두 개의 3x3x3 Conv Layer로 구성된다.
모델의 Output같은 경우, Head Module을 거쳐 채널을 3으로 재구성하고, 활성화 함수로 Sigmoid 를 채택하면서 각 채널에서 픽셀별로 Tumor Score를 0~1사이의 값으로 예측하게 된다.
Loss Function
- Soft Dice Loss를 사용함
- Dice Loss = 1 - Dice Score
- Dice Score : 정밀도와 재현율을 한 번에 표현한 함수
- G = Ground Truth , Y = Predicted , l = Voxel 수 , J = class 수

Dice Score는 정밀도와 재현율을 한 번에 표현한 점수로 1에 가까울수록 GT와 Predicted 가 유사하다고 생각하면 됩니다.
파란색으로 나와있는 수식이 Dice Score 공식인데, Swin UNETR같은 경우, 여러 클래스도 고려해야 되기 때문에, 클래스마다 계산한 Dice Score를 모두 더한 뒤 클래스 개수인 J로 나누는 방식을 채택하고 있습니다.
그리고 3D input과 output이기 때문에 픽셀마다 처리하지 않고, Dimension 축으로 픽셀들을 묶어서 만든 복셀(Voxel) 단위로 계산을 하는 것 같습니다.

Segmentation에 사용되는 평가지표에 대해 설명을 하겠습니다.
먼저 Dice Score는 정밀도와 재현율을 한 번에 나타내는 F-Score와 완전히 같은 지표이다. 1에 가까울수록 Predicted와 GT 가 유사하다고 생각하면 됩니다. 그런데 이것을 시각화한 자료로 따져보면, 흰 색 손이 GT고 초록색 영역이 Predicted라고 할 때, 1에 가까울수록 초록색 영역은 손의 계형을 따른다고 이해할 수 있습니다.
그리고 공식을 보면, IoU와 유사하기 때문에, 그냥 IoU처럼 겹치는 비중이 많을수록 분자인 교집합이 커져 더 정확하게 예측했다고 생각하면 됩니다.
정리

Swin UNETR의 구조
- Encoder를 통해서 input의 feature map과 downsampling을 한다.
- Encoder를 통과하기 전에 patch partition을 통해서 3D token에 대한 sequence를 만듭니다.
- 여기서 Swin transformer Block 을 지나는데 W-MSA와 SW-MSA 메커니즘을 적용하는 단계입니다.
- 각각의 Swin Transformer Block을 지나면서 총 4개의 중간 output을 skip-connection에 이용합니다.
- Decoder 단계에서는 , 3D UNET 구조를 통해서 각각의 sequence를 다시 3D voxel 형태로 reshape한 후 deconvolution을 통해서 upsampling 합니다.
- Skip-Connection을 총 4회 진행 후 voxel 사이즈로 원상 복귀 합니다.
- 마지막 단계에서는 기존의 input voxel의 channel을 48로 만들고 3D UNET구조에서 나온 최종 결과값과 concatenate를 진행합니다.
- 마지막 1x1x1 conv layer와 sigmoid를 통해서 H x W x D x 3 shape로 만들어줍니다.
추가
SSL Swin UNET 논문 = Swin UNETR + SSL ( Self Supervised learning) 모델