
https://arxiv.org/pdf/1512.04150.pdf
Learning Deep Features for Discriminative Localization - 2015
기존의 CNN 모델에서는 Input → Conv layers → Fc layers → softmax 의 매커니즘을 통해 특정 이미지를 클래스로 분류하는 학습 과정을 거칩니다. 이는 매우 일반적인 방법으로 마지막 feature map을 flatten 하여 1차원 백터들로 만든 후에 이를 Fully Connected Network를 통과하여 Softmax로 분류하는 것이죠.
Learning Deep Features for Discriminative Localization - Introduction ( 논문 발췌 부분 )
Despite having this remarkable ability to localize objects in the convolutional layers, this ability is lost when fully-connected layers are used for classification.
Recently some popular fully-convolutional neural networks such as the Network in Network (NIN) [13] and GoogLeNet [24] have been proposed to avoid the use of fully-connected layers to minimize the number of parameters while maintaining high performance.
In order to achieve this, [13] uses global average pooling which acts as a structural regularizer, preventing overfitting during training. In our experiments, we found that the advantages of this global average pooling layer extend beyond simply acting as a regularizer - In fact, with a little tweaking, the network can retain its remarkable localization ability until the final layer.
Furthermore, we demonstrate that the localizability of the deep features in our approach can be easily transferred to other recognition datasets for generic classification, localization, and conceptdiscovery
요약
- Convolutional layer의 마지막에 사용되는 FC layer는 이미지의 위치 정보를 잃게합니다.
- NIN or GooLenet 과 같은 유명한 신경망은 고성능을 유지하면서 매개변수 수를 최소화하기 위해 FC layer를 사용하지 않도록 제안합니다.
- 저자들은 GAP(Global Average Pooling)는 단순한 정규화 기능뿐만 아니라 이미지의 위치 정보를 유지할 수 있다는 것을 발견.
Fully connected layer를 사용하면 object의 localize하는 특징을 잃어버리는 이유가 뭘까?
Convolution layer의 출력이 FC로 전달되면 데이터의 공간 구조가 손실됩니다.
FC layer에서는 모든 뉴런이 이전 계층의 모든 뉴런에 연결됩니다. 이는 완전 연결 계층의 뉴런이 컨볼루션 계층에서 학습한 모든 기능에 대해 전역적으로 보는 것을 의미합니다. 그러나 원본 이미지에서 이러한 기능들은 서로 상대적인 위치를 알지 못합니다.
FC의 고질적인 문제는 FC에 집어넣기 위해 직렬화를 수행하면서 픽셀간의 상관관계들을 잃게된다는 점입니다. 따라서 데이터의 전체 관계를 고려하게 되지 못하는 문제점이 발생합니다.
GAP ( Global Average Pooling )은 왜 사용해야해?
이 논문에서 가장 중요한 기술인 GAP는 입력 이미지의 특정 위치 정보에 덜 민감합니다. 이것은 같은 물체가 다른 이미지에서 다른 위치에 나타날 수 있기 때문에 유용하게 사용됩니다.
또한 GAP는 로컬 위치별 세부 정보가 아닌 전역 기능에 집중하도록 합니다. 모델이 이미지에서의 위치가 아닌 전체 기능을 기반으로 객체를 인식하는 방법을 학습하므로 모델이 새 이미지에 대해 더 잘 인식할 수 있습니다.
Fully Connected Layer와 달리 연산이 필요한 파라미터 수를 크게 줄일 수 있으며, 결과적으로 regularization과 유사한 동작을 통해 오버피팅을 방지할 수 있습니다.

Related work
Visualizing CNNs: There has been a number of recent works [29, 14, 4, 33] that visualize the internal representation learned by CNNs in an attempt to better understand their properties.
While these approaches can invert the fully-connected layers, they only show what information is being preserved in the deep features without highlighting the relative importance of this information
Class Activation Mapping
저자는 CNNs에서 GAP를 사용해 class activation maps 을 생성하는 절차에 대해 설명합니다.
아래의 figure ( 논문 참고 )은 CAM의 구조를 보여줍니다. 우선 기본적인 구조는 NIN(Network in Network)와 GoogleNet 이랑 흡사하다. 하지만 결정적인 차이는 마지막 Conv Layer를 Fc-Layer로 Flatten 하지 않고, GAP(Global Average Pooling)을 통해 새로운 weight 들을 만들어 낸다는 것이다.
마지막 컨볼루션을 FC-layer 로 바꾸는 대신에, GAP (Global Average Pooling) 을 적용하면, 별다른 추가의 지도학습 없이 CNN 이 특정 위치들을 구별하도록 만들 수 있다는 것입니다. 위 그림을 보면 CAM 을 통해 특정 클라스 이미지의 Heat Map 을 생성할 수 있다. 이 Heat Map 을 통해 CNN 이 어떻게 그 이미지를 특정 클라스로 예측했는지를 이해할 수 있습니다.
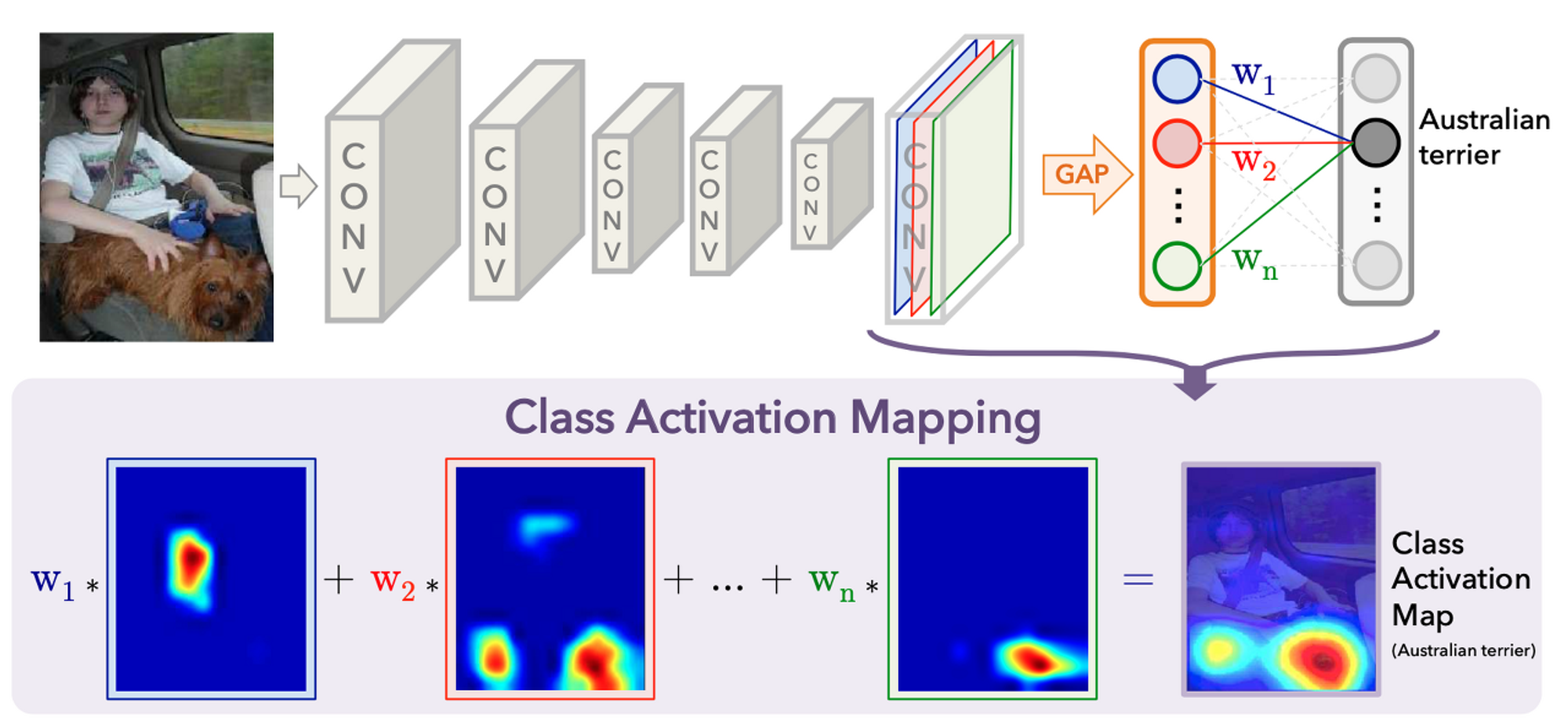
the final output layer (softmax in the case of categorization), we perform global average pooling on the convolutional feature maps and use those as features for a fully-connected layer that produces the desired output (categorical or otherwise).
we can identify the importance of the image regions by projecting back the weights of the output layer on to the convolutional feature maps, a technique we call class activation mapping.
Global average pooling (GAP) vs global max pooling (GMP): Given the prior work [16] on using GMP for weakly supervised object localization, we believe it is important to highlight the intuitive difference between GAP and GMP.
[Global Avg. Pooling (GAP) vs Global Max Pooling(GMP)]
GAP(Global Average Pooling): 이 작업은 각 Feature map에 있는 모든 값의 평균을 계산합니다. 깊이(특징 맵 수)를 유지하면서 입력 볼륨의 공간 차원(높이 및 너비)을 1x1로 줄이는 데 도움이 됩니다. 이 작업은 개체 지역화를 위한 클래스 활성화 맵(CAM)을 생성하기 위해 논문에서 사용됩니다. 저자는 분류 작업에서 GAP(GoogLeNet-GAP와 같은)를 사용하는 네트워크가 GAP가 없는(GoogLeNet과 같은) 네트워크와 유사하게 수행된다는 것을 발견했습니다. 또한 저자들은 GAP 네트워크가 localization 작업에 대한 다른 접근 방식을 능가한다는 사실을 발견했습니다.
GMP(Global Max Pooling): 이 작업은 각 기능 맵에 있는 모든 값의 최대값을 계산합니다. GAP와 마찬가지로 입력 볼륨의 공간 크기를 1x1로 줄입니다. 그러나 저자는 GoogLeNet-GAP가 현지화 작업에서 GoogLeNet-GMP를 능가한다는 사실을 발견했으며, 이는 평균 풀링이 이 컨텍스트에서 개체의 범위를 식별하는 데 최대 풀링보다 더 효과적임을 나타냅니다.
마지막 Conv Layer 에 GAP 혹인 GMP 를 적용함에 따라 CAM 결과에 적지 않은 영향을 끼칠 수 있습니다. GAP 은 네트워크가 특정 object 의 전체적인 분포를 구분할 수 있도록 도와주는 반면, GMP 은 가장 높은 특정 분포들만 구분할 수 있도록 도와줍니다. Classification Task 에서는 둘의 성능이 비슷하지만, Localization Task 에서는 GAP 가 더 좋은 결과를 가져옵니다

논문에서 제시한 수식을 잘 정리한 이미지이다.
아래는 수식을 수기로 기록한 부분 … ㅎ


위의 그림과 수식을 함께 보면 수식을 쉽게 이해할 수 있습니다.
Weakly-Supervised Object Localization
데이터는 ILSVRC 2014를 활용하여 CAM을 활용했을 때와 기존의 CNN 모델의 성능을 비교했다.
GAP를 사용했을 때 에러가 소폭 증가하지만 Fc-layers 를 전혀 사용하지 않은 점이 높게 평가된다.
Note that it is important for the networks to perform well on classification in order to achieve a high performance on localization as it involves identifying both the object category and the bounding box location accurately.

다음은 Localization의 결과입니다. 우선 Localization을 테스트하기 위해서 원본 이미지에서 특정 클래스의 bbox를 만들어야 합니다. bbox는 CAM이 표시한 부분 중 20%가 넘는 부분들이 먼저 선택되었고 이 부분들을 가장 많이 포함할 수 있는 box가 선택되었습니다. 예측한 상위 5개의 클래스마다 이러한 bbox를 만들었습니다.

Table 2 에서 볼 수 있듯이 CAM 을 활용한 네트워크들이 다른 네크워들보다 Localization 성능이 뛰어나다는 것을 확인할 수 있습니다. GoogLeNet-GAP 은 top-5 에러가 43% 밖에 되지 않았는데, bounding box 에 별다른 학습을 하지 않았다는 것을 고려할 때 매우 놀라운 결과입니다.

Pattern Discovery
저자들은 CAM(Class Activation Mapping) 기술이 텍스트 또는 상위 수준 개념과 같은 개체를 넘어 이미지의 공통 요소 또는 패턴을 식별할 수 있는지 여부를 탐색합니다. 저자는 심층 기능을 사용하여 세 가지 패턴 발견 실험을 수행했습니다.


We train a one-vs-all linear SVM for each scene category and compute the CAMs using the weights of the linear SVM.
장면에서 유익한 개체 발견: 저자는 주석이 완전히 달린 이미지가 200개 이상 포함된 SUN 데이터 세트에서 10개의 장면 범주를 가져와 총 4675개의 주석이 달린 이미지를 얻었습니다. 각 장면 범주에 대해 일대다 선형 SVM을 훈련하고 선형 SVM의 가중치를 사용하여 CAM을 계산했습니다. 그들은 높은 활성화 영역이 특정 장면 범주를 나타내는 객체에 자주 해당한다는 것을 발견했습니다.
Using the hard-negative mining algorithm from [32], we learn concept detectors and apply our CAM technique to localize concepts in the image.
약하게 레이블이 지정된 이미지의 개념 현지화: 저자는 하드 네거티브 마이닝 알고리즘을 사용하여 개념 탐지기를 학습하고 CAM 기술을 적용하여 이미지의 개념을 현지화했습니다. 짧은 문구에 대한 개념 탐지기를 훈련하기 위해 포지티브 세트는 텍스트 캡션에 짧은 문구가 포함된 이미지로 구성되고 네거티브 세트는 텍스트 캡션에 관련 단어가 없는 무작위로 선택된 이미지로 구성됩니다.
저자는 그들의 기술이 텍스트나 높은 수준의 개념과 같은 객체를 넘어 이미지의 공통 요소나 패턴을 식별하는 데 성공했음을 발견했습니다. 이는 물체 위치 파악뿐만 아니라 이미지의 패턴 발견을 위한 CAM 기술의 다양성과 강력함을 보여줍니다.
Conclusion
논문의 결론에서 저자들은 GAP를 사용한 CAM이라는 기술을 CNN과 함께 사용할 것을 제안합니다. 이 기술을 사용하면 분류를 위해 훈련된 CNN이 bounding box를 사용하지 않고 객체를 Localization할 수 있습니다. CAM을 사용하면 주어진 이미지에서 예측된 클래스 점수를 시각화하여 CNN에서 감지한 식별 가능한 객체를 강조 표시할 수 있습니다.
My Insight
YOLO 논문 리뷰할 때 bounding box를 계산했었는데, 이 부분을 생략하고 바로 객체를 탐지할 수 있다면 더욱 가벼운 모델이 될 것 같습니다.
하지만 CAM은 GAP를 사용하도록 설계되었는데 Fc-layers가 반드시 필요한 아키텍쳐를 가진 모델에서는 사용할 수 있을까 ? 이 부분을 조금 더 공부해봐야 되겠네요.
그리고 XAI 알고리즘의 한 종류로 논문을 읽고 공부했는데, 확실히 단순 객체 탐지보다 훨씬 explainable하지만 모델이 결정을 내리는 방식을 이해하는 측면에서 해석 가능성을 제공하지는 않는다고 생각합니다.
강조 표시된 영역은 모델이 찾는 위치를 보여주지만 최종 분류에 도달하기 위해 이러한 Localization 기능을 결합하는 방법은 찾지 못한거 같네요,
또한 CAM은 CNN의 이미지 분류 성능이 정확하다고 가정합니다. 모델이 이미지를 잘못 분류하면 CAM이 관련 없는 영역을 강조 표시하여 잠재적으로 오해의 소지가 있는 해석으로 이어질 수 있지 않을까 싶습니다!