
Search | Kaggle
www.kaggle.com
안녕하세요 !
오늘은 Kaggle의 spaceship titanic 데이터로 머신러닝 End to End를 진행했습니다.
총 3시간정도 소요됐고 머신러닝의 전체적인 workflow를 연습하는 과정삼아 처음부터 끝까지 한 번에 했습니다.
위의 링크로 들어가시면 kaggle 대회의 overview 와 데이터셋을 다운받으실 수 있습니다.
Data 다운받는 방법
kaggle에 등록된 데이터를 다운받는 방법은 두 가지가 있습니다.
우선 그냥 링크에 들어가서 파일로 올라온 데이터들을 다운 받으신 후 실습할 디렉토리에 저장하는 방법입니다.
이건 너무 쉽죠 ?!
하지만 저는 데이터 셋을 하나씩 다 다운 받은 후에 파일을 옮겨주는 과정이 귀찮아서 주피터 노트북에서 바로 kaggle 데이터를 다운 받는 방법을 사용하는데요
코드는 다음과 같습니다. ( 코랩도 동일합니다. )
!pip install -q kaggle
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/kaggle.json
!chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions download -c spaceship-titanic
!unzip spaceship-titanic.zip1. kaggle 라이브러리를 다운받습니다.
2. mkdir -p ~/.kaggle은 현재 사용자의 홈 디렉토리에 .kaggle이라는 디렉토리를 생성하고 필요한 상위 디렉토리를 생성합니다.
3. kaggle.json 파일을 2에서 생성한 폴더에 복사합니다.
kaggle.json 파일은 kaggle 사이트에서 로그인후 Setting에 들어가게 되면 API가 있습니다.
여기서 create new token 을 누르시면 json 파일이 다운로드 되고 다운로드 된 그 파일을 2에서 만든 폴더로 옮겨주시면 됩니다.
4. kaggle.json 파일의 권한을 변경합니다. chmod 600 명령은 파일 소유자만 파일을 읽고 쓸 수 있도록 권한을 설정하는데, 이는 API 자격 증명을 보호하기 위한 보안 조치입니다.
5. Kaggle API를 사용하여 spaceship-titanic 대회 데이터를 다운로드합니다.
6. Kaggle 대회에서 다운로드한 파일인 spaceship-titanic.zip 파일의 압축을 풉니다. unzip 명령은 zip 파일의 내용을 추출하는 데 사용됩니다.

Load in and Do Fast EDA
전처리를 빠르게 해보겠습니다.
이번에는 pandas-profiling 을 사용해서 사용할 데이터 ( train.csv ) 의 전체적인 정보를 빠르게 파악해봅시다.
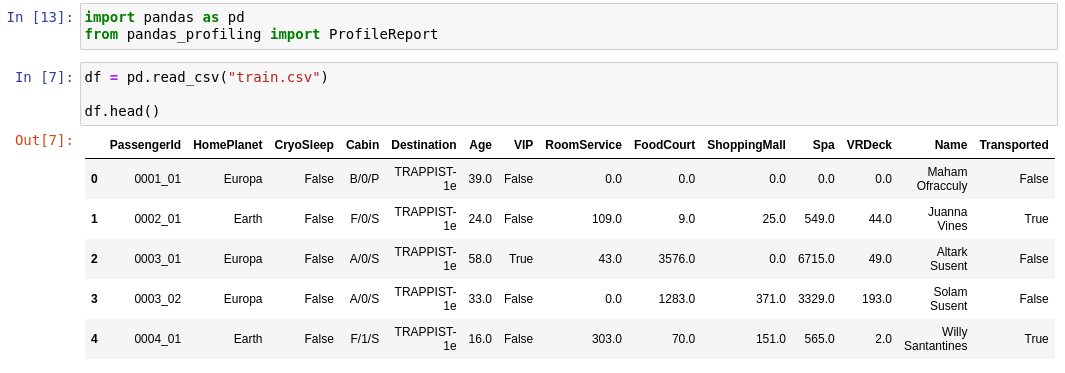
우리가 사용할 데이터를 먼저 살펴볼게요.
파일 및 데이터 필드 설명
train.csv
약 8700명의 승객에 대한 개인 기록이며, 훈련 데이터로 사용됩니다.
데이터 필드
-**PassengerId**: 각 승객에 대한 고유 ID입니다. 각 ID는 gggg_pp 형태를 가지며, 여기서 gggg는 승객이 함께 여행하는 그룹을 나타내고 pp는 그룹 내에서의 번호입니다. 그룹에 있는 사람들은 종종 가족이지만 항상 그런 것은 아닙니다.
- **HomePlanet**: 승객이 출발한 행성으로, 일반적으로 그들의 영구 거주 행성입니다.
- **CryoSleep**: 승객이 여행 기간 동안 중단 애니메이션에 들어가기로 선택했는지 여부를 나타냅니다. Cryosleep에 있는 승객들은 객실에 제한됩니다.
- **Cabin**: 승객이 머무는 객실 번호입니다. deck/num/side 형태를 가지며, 여기서 side는 Port를 위한 P 또는 Starboard를 위한 S가 될 수 있습니다.
- **Destination**: 승객이 탈선할 행성입니다.
- **Age**: 승객의 나이입니다.
- **VIP**: 승객이 여행 동안 특별 VIP 서비스를 위해 지불했는지 여부입니다.
- **RoomService, FoodCourt, ShoppingMall, Spa, VRDeck**: 승객이 Spaceship Titanic의 많은 고급 편의 시설에서 청구한 금액입니다.
- **Name**: 승객의 이름과 성입니다.
- **Transported**: 승객이 다른 차원으로 전송되었는지 여부입니다. 이것은 목표로, 예측하려는 열입니다.
test.csv
나머지 약 4300명의 승객에 대한 개인 기록이며, 테스트 데이터로 사용됩니다. 여러분의 임무는 이 세트의 승객에 대한 Transported 값을 예측하는 것입니다.
sample_submission.csv
올바른 형식의 제출 파일입니다.
PassengerId
테스트 세트의 각 승객에 대한 ID입니다.
Transported
목표입니다. 각 승객에 대해 True 또는 False를 예측해야 합니다.
Note
1. 그룹에 속한 Passenger은 가족일 확률이 높지만 항상 그런 것은 아니다. ID 뒤에 _02는 그룹 여행을 뜻한다
2. Cabin 은 deck/num/side로 나뉘게된다.
3. RoomService, FoodCourt, ShoppingMall, Spa, VRDeck
Task - Predict Transported ( Binary Classification )
To do
1. Missing value를 채우기
2. 불균형한 칼럼이 있다면 데이터세트의 균형을 맞춰주기
3. 높은 카디널리티( 특정컬럼의 중복수치 ) 컬럼 제거
EDA
pandas profiling 을 사용해서 칼럼마다 특징을 살펴보고 어느 부분을 집중해서 전처리 해줘야 하는지 파악할 수 있습니다.

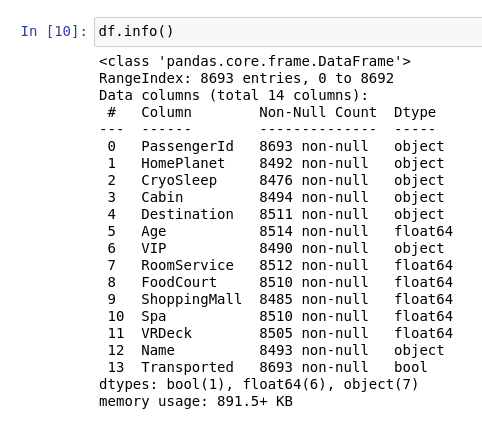
이 코드를 실행하면 다음과 같은 화면이 나오는데요

컬럼의 갯수와 전체 데이터의 수를 비롯해 결측값의 개수와 비율을 알려주네요.
info() 를 통해 결측값을 파악하고 처리해줄 수 있지만 이렇게 각 컬럼마다 자세하게 보려면 pandas profiling이 정말 편합니다.
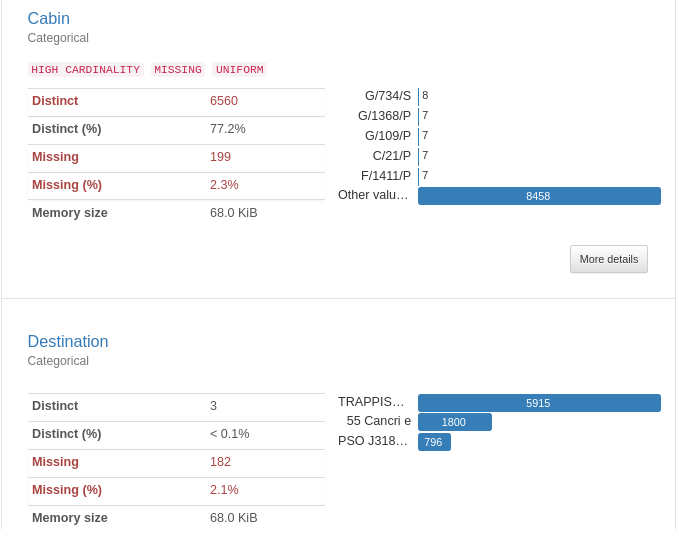
데이터를 하나씩 보면서 어떻게 결측값을 처리해줄지 생각해보고 전처리를 한번에 수행하는 함수를 만들겠습니다.
우선 'Cabin' 데이터를 보면 아까 데이터 설명에 나와있듯이 deck/num/side 이런식으로 나뉘게 됩니다. 제 생각엔 한 컬럼에 3가지 정보가 담겨있어서 높은 카디널리티가 나온거 같네요.

/ 를 기준으로 split 하여 deck과 side를 개별 칼럼으로 꺼내는 작업을 해야합니다.

- if len(str(x).split('/')) < 3: 이 줄은 캐빈 번호가 '/' 문자로 분할될 때 결과가 3부분 미만인지 확인합니다. str(x).split('/') 부분은 x를 문자열로 변환하고 '/' 문자가 있는 부분으로 분할합니다. len(...) 부분은 부분의 개수를 가져옵니다. 따라서 x가 'A/123'과 같으면 길이가 2인 ['A', '123']으로 분할되므로 일부 누락된 것으로 간주됩니다.
- return ['Missing', 'Missing', 'Missing']: 객실 번호에 일부가 누락된 경우 함수는 세 개의 'Missing' 문자열이 포함된 목록을 반환합니다.
- else:: 선실 번호에 누락된 부분이 없으면 실행되는 부분입니다.
- return str(x).split('/'): 선실 번호에 누락된 부분이 없으면 함수는 '/' 문자로 번호를 분할하고 결과 목록을 반환합니다. 예를 들어, x가 'A/123/P'이면 ['A', '123', 'P']로 분할됩니다.
위의 함수를 정의한 후, 'Cabin' 컬럼에 lambda 함수를 apply 하여 함수를 적용시켜줍니다.
df['TempCabin'] = df['Cabin'].apply(lambda x : split_cabin(x))
df['deck'] = df['TempCabin'].apply(lambda x: x[0])
df['Side'] = df['TempCabin'].apply(lambda x: x[2])
그리고 각 컬럼마다 fillna 함수를 사용해서 결측값을 채운 코드입니다.
preporcessing 이라는 함수를 정의하여 결측값들을 모두 채웠습니다.
# Crteate a preprocessing function to transform our dataset
def preprocessing(df):
df['HomePlanet'].fillna("Missing", inplace=True) # HomePlanet 컬럼의 결측값을 Missing으로 채웁니다.
# Cryosleep - high correlated - drop na rows
df['CryoSleep'].fillna("Missing", inplace=True)
# deck 와 Side 정보만 따로 컬럼을 만들어 줍니다. - Cabin 컬럼 전처리
df['TempCabin'] = df['Cabin'].apply(lambda x : split_cabin(x))
df['deck'] = df['TempCabin'].apply(lambda x: x[0])
df['Side'] = df['TempCabin'].apply(lambda x: x[2])
df.drop(columns=['TempCabin', 'Cabin'], axis=1 , inplace=True)
# Destination
df['Destination'].fillna('Missing', inplace=True)
# AGE
df['Age'].fillna(df['Age'].mean(), inplace=True)
#VIP - drop na rows ( bool )
df['VIP'].fillna('Missing', inplace=True)
# Monetary spending col
df['RoomService'].fillna(0, inplace=True)
df['FoodCourt'].fillna(0, inplace=True)
df['ShoppingMall'].fillna(0, inplace=True)
df['Spa'].fillna(0, inplace=True)
df['VRDeck'].fillna(0, inplace=True)
# Drop 높은 카디널리티
df.drop('Name', axis=1, inplace=True)
# Drop remaining rows
# df.dropna(inplace=True)
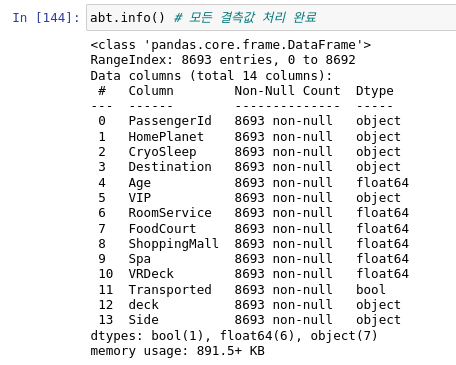
이후에 abt라는 df의 복사본을 만든 후 preprocessing 전처리 함수에 abt를 넣었습니다.
그 결과 모든 결측값이 처리가 된 것을 확인하실 수 있습니다.
Modelling
이제 전처리가 다 되었으니 모델링을 진행해야겠죠?
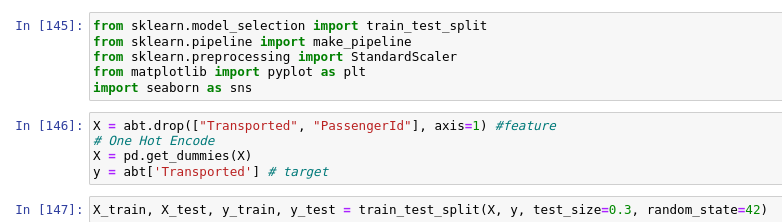
모델링에 사용할 데이터를 train_test_split 으로 나눴습니다. abt 데이터에서 Transported ( Target ) 과 PassengerId 컬럼을 제거했습니다. 승객의 아이디 정보는 학습시 필요없다고 판단하여 삭제했습니다.
그리고 X에 범주형 변수들을 수치형 변수로 변환하기 위해 get_dummies 함수로 변환을 해주었습니다.
MLPipeline
저도 이번에 파이프라인을 처음 사용했는데, 굉장히 편하고 효율적인 방법이라고 생각합니다.
기존에 사용하던 방법은 사용할 모델을 가져와서 하나씩 돌려보는 것인데 , 파이프라인을 사용하면 한 번에 지정한 모델들을 학습하고 성능까지 확인할 수 있습니다.
아래의 코드는 랜덤 포레스트 모델과, 그레디언트부스팅 분류기를 사용한 파이프라인입니다.
piplines라는 변수에 딕셔너리 형태로 사용할 모델들을 지정하고 아래의 grid에는 GridSearchCV 모델에 사용할 파라미터를 지정합니다.
반복문을 통해 pipelines에서 지정한 모델들을 가져오고 grid에서 맞는 학습 파라미터 중 최적의 하이퍼 파라미터를 골라 자동으로 학습을 진행합니다.

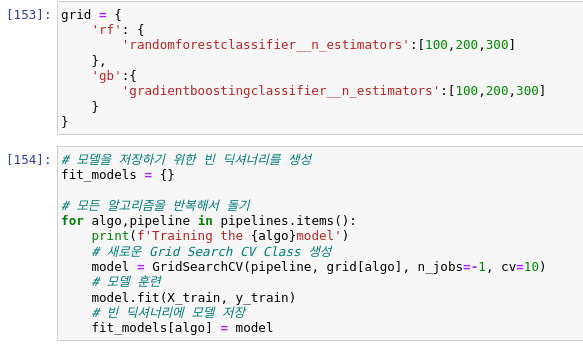
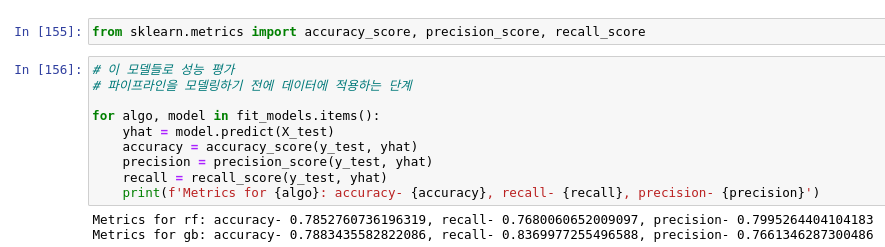
성능 평가를 해보면 그레디언트 부스팅 알고리즘이 아주 미세하게 더 좋은 성능을 보여주네요.
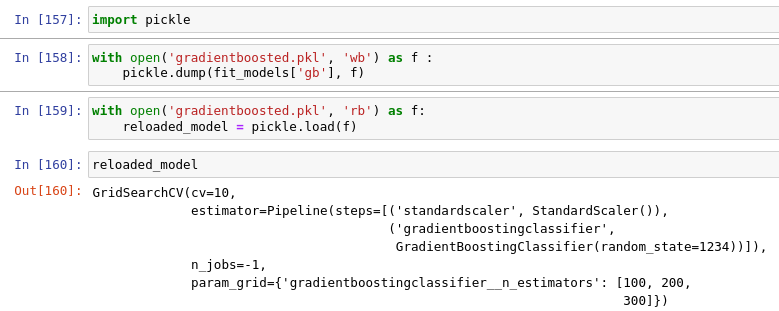
Save Best Model
성능이 좋았던 그레디언트 알고리즘을 pickle 형태로 저장해봅시다.
pickle은 텍스트 상태의 데이터가 아닌 파이썬 객체 자체를 ( 리스트 , 튜플 등 ) 바이너리 파일로 저장하는 것.
text 파일을 사용하는 경우 필요한 부분들을 파싱해야 하지만 pickle은 이미 필요한 형태대로 저장이 되어 있기 때문에 훨씬 빠르다고 합니다.
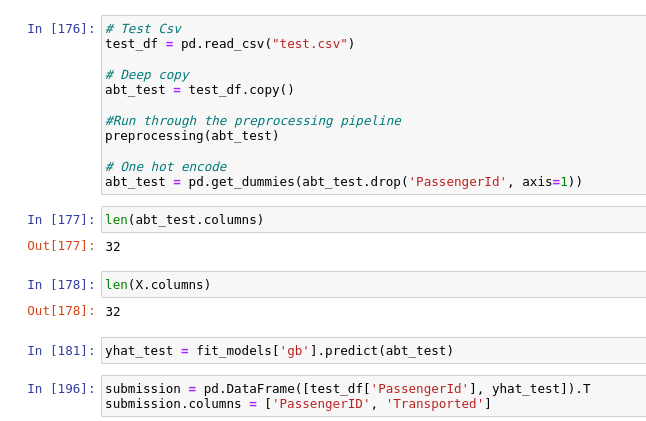
Predict on test data
그렇다면 test 데이터를 활용해 예측값을 얻어봐야겠죠?
test 데이터도 똑같이 전처리 과정을 거친 후 yhat_test 라는 변수에 예측값을 넣어줍니다.
그리고 submission을 생성합니다.

Submit to kaggle
자 그럼 submission 파일을 제출하려면 어떻게 해야할까요 ?
맨 아래의 코드를 실행시키면 자동으로 캐글 대회의 사이트에 업로드 됩니다 !!
