
주성분 분석 개요
주성분 분석 ( Princial component analysis, PCA )은 서로 상관관계를 갖는 많은 변수를 상관관계가 없는 소수의 변수로 변환하는 차원 축소 기법입니다.
주의해야 할 점은 데이터 하나한에 대한 성분을 분석하는 것이 아닌 여러 데이터들이 모여 하나의 분포를 이룰 때, 이 분포의 주성분을 분석하는 것입니다. 주성분이란 그 방향으로 데이터들의 분산이 가장 큰 방향 벡터를 의미합니다.
변환에 사용되는 소수의 변수를 주성분(princial component) 또는 성분(component)이라고 합니다.
주성분 분석을 토대로
1. 회귀분석에서 설명 변수의 개수 결정
2. 인자분석의 전초작업
3. 군집분석의 전초작업으로 사용됩니다.
주성분 분석 모델
주성분 분석 모델에서 주성분은 변수들의 선형결합으로 표현됩니다. 선형 결합을 위한 가중치는 주성분 간 상관관계가 없으면서 각 주성분이 설명하는 분산이 최대화 되도록 결정합니다.
상관관계를 갖는 다수의 변수에 포함된 정보를 가능한 많이 포착하면서 이 다수의 변수를 상관관계를 갖지 않는 그보다 더 적은 개수의 새로운 변수로 대체합니다. 변수들이 가지고 있는 총표본분산을 많이 설명해주는 순서대로 순차적으로 변수 개수만큼의 성분을 추출합니다.
추출된 성분 중 가장 많은 설명력을 제공하는 처음 몇 개의 소수의 성분만을 이용하여 데이터를 분석함으로써 데이터의 복잡성이 감소됩니다.
R에서 PCA를 다루는 데는
prcomp() 함수를 사용합니다.
prcomp() 함수의 인자로
formula - 수식
data - 데이터
subset - 그룹 자료
na.action - 결측치 처리
x - 분석 대상의 데이터
retx - 변수축 회전 여부
center - zero 원점 설정 여부
scale - 표준화 여부 ( 상관계수 행렬 이용 )
tol - 산정 과정의 허용 오차
주성분 분석을 할 때 고려해야 할 요인들이 좀 있는데요
우선 상관 행렬과 공분산 행렬 중 어느 것을 선택할 것인지 정해야합니다.
주성분 분석의 경우 척도에 영향을 받습니다. 변수들의 선형 결합을 유도할 때 분산을 이용하기 때문에 결과적으로 공분산 행렬로부터 유도된 주성분은 측정단위의 크기에 좌우되죠.
설문조사처럼 모든 변수들이 같은 수준으로 점수화가 된 경우에는 공분산 행렬을 사용해도 되지만, 변수들의 scale 값이 서로 많이 다른 경우에는 값이 큰 특정 변수가 전체적인 경향을 좌우하기 때문에 상관계수 행렬을 사용하여 추출하여야 합니다.
그리고 주성분의 개수를 정해야합니다.
PCA로 차원축소를 할 때 몇 개의 PCs를 선택할 것인가에 대해 학문적으로 정해진 정답은 없으며 많이 사용되는
경험에서 나온 법칙 ( rule of thumb ) 은 3가지가 있습니다.
1. 누적기여율 (설명된 분산의 누적 비율)이 최소 0.8 이상일 것.
2. 단지 평균 분산보다 큰 PC만 선별할 것.
3. Scree plot을 그렸을 때, 꺾이는 부분 (elbow)가 있다면 elbow 지점 앞의 pc 개수 선택
R의 기본 데이터셋 state.x77 으로 주성분 분석 테스트를 진행해보겠습니다.
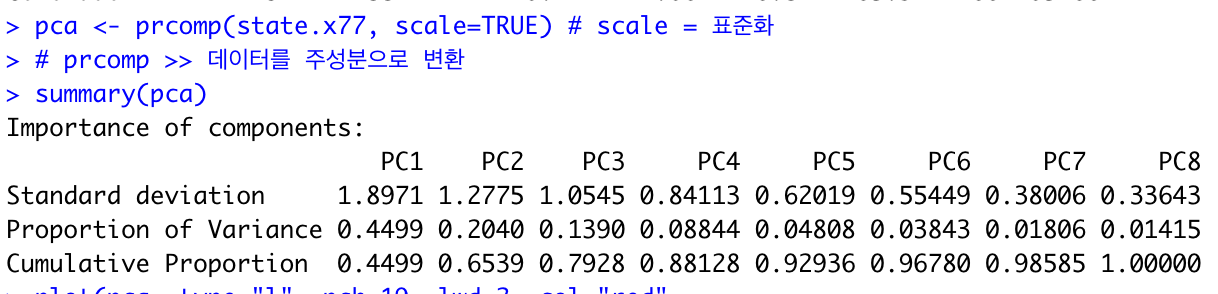
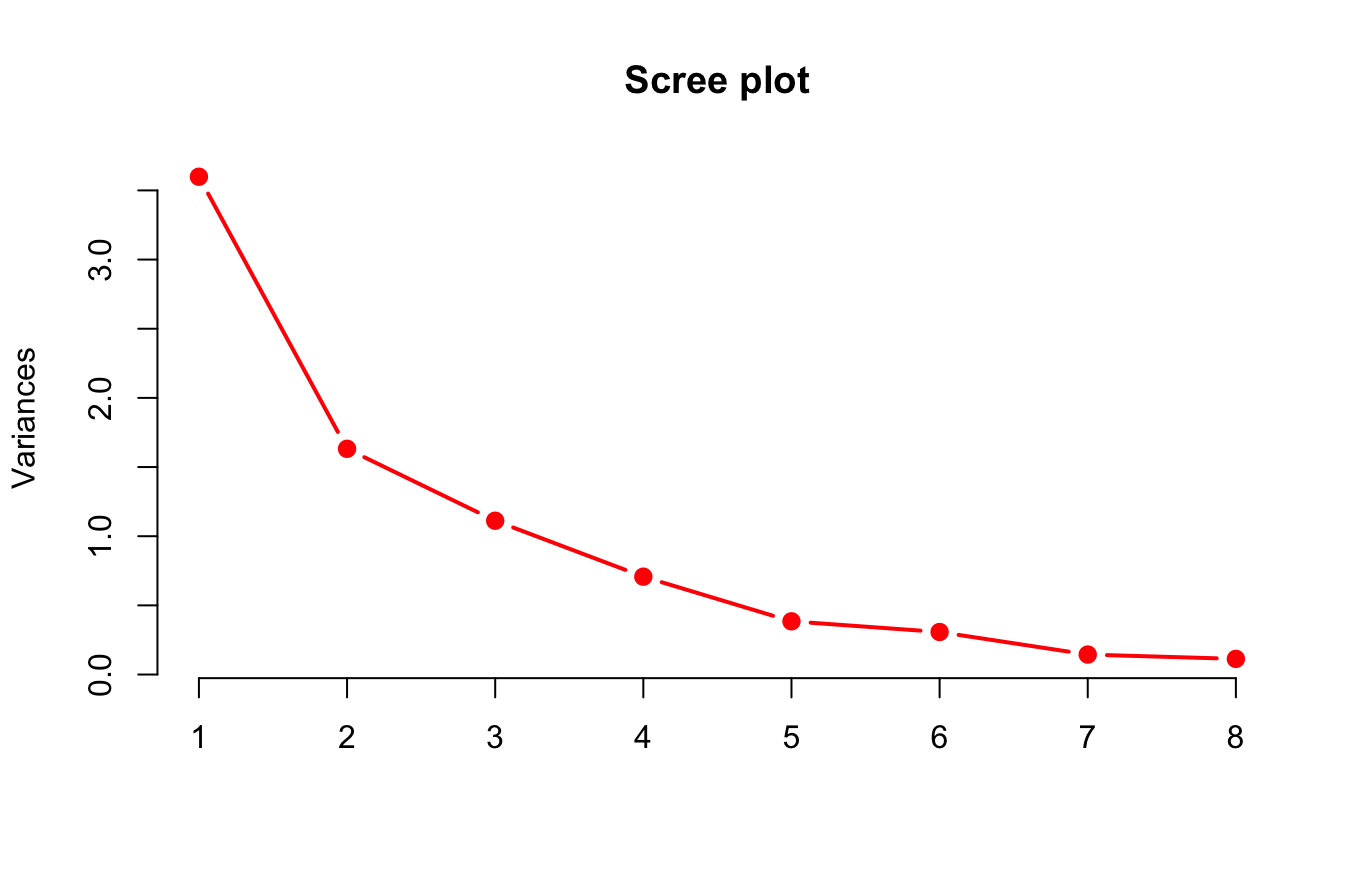
scree plot 으로 확인한 결과 주성분의 개수는 2로 설정하면 될 것 같네요.
# 꺾이는 지점이 가장 큰 곳이 설명력이 큰 성분의 개수를 나타냄
# prcomp() 함수의 결과는 리스트형으로 저장되며
# 리스트 sdev, rotation, center, scale, x 5개의 원소가 있습니다.
# sdev는 고유치의 제곱근, rotation은 주성분 변환 계수,
# center은 각각 x1 ~ x4의 평균, scale은 표준화 여부,
# x(주성분 변환이된 데이터)을 의미하겠고 중요하게 확인할 원소들은 rotation, x 정도가 되겠습니다.
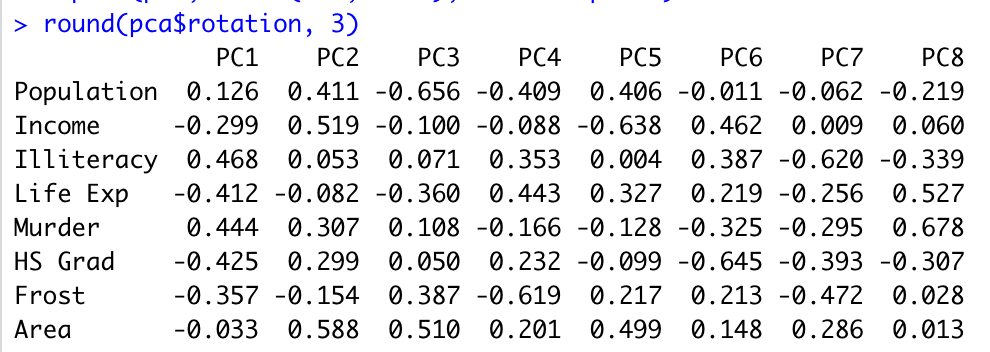
round(pca$rotation, 3) 로 성분 적재값 (component loading)을 구합니다.
그 다음 표준화 된 데이터셋 행렬과 성분 적재값 행렬의 곱으로 성분 점수 (component score)를 구해서 설명력이 가장 큰 상위 2개의 변수를 찾아봅시다.
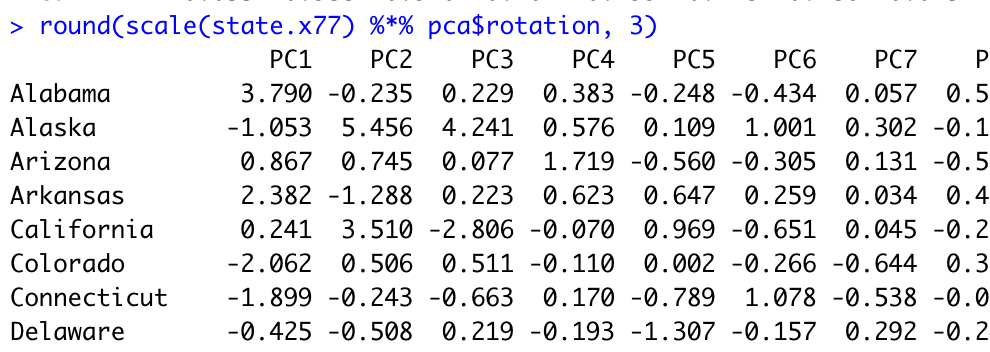
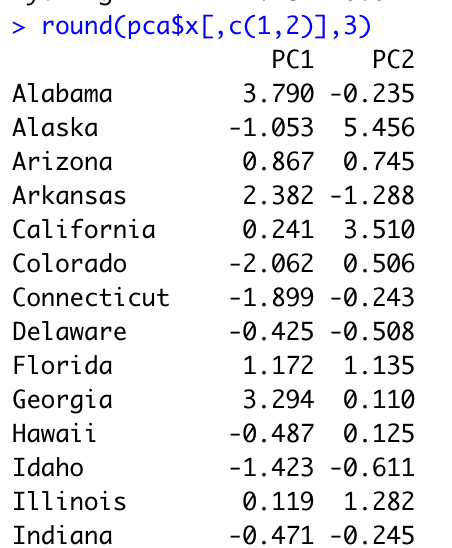
설명력이 가장 큰 성분 두개가 추려졌네요 !

성분간의 상관관계 역시 바로 확인하고
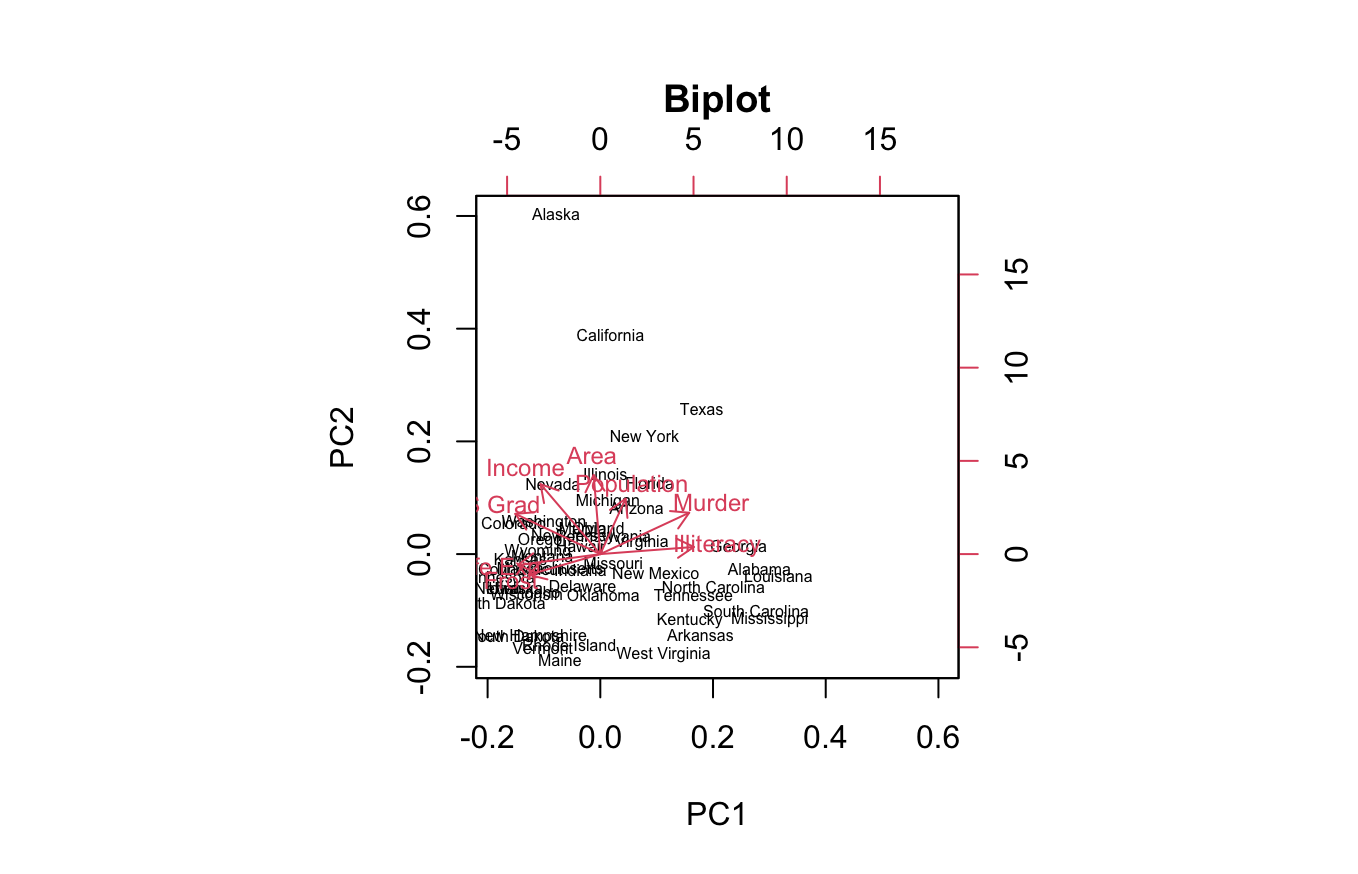
biblpot 으로 플로팅을 해보면 주성분 분석에 대한 시각적인 자료를 확인 하실 수 있습니다 !!