
https://arxiv.org/pdf/1912.04958.pdf
논문 원본
https://minyoungxi.tistory.com/42
StyleGAN 2019 - 고해상도 이미지를 고퀄로 생성해보자
https://arxiv.org/pdf/1912.04958.pdf 논문 본문의 링크입니다. Contribution 본 논문에서 제안된 style-based generator로 고해상도 이미지를 높은 퀄리티로 생성합니다. Disentanglement를 측정하는 지표 두가지를 제
minyoungxi.tistory.com
필수 논문 : StyleGAN - 이전 포스팅
논문 소개
다양한 고해상도의 이미지를 생성할 수 있습니다.
- 성능 개선 : 기존의 StyleGAN보다 더 높은 품질의 이미지를 생성하고, 이미지를 부드럽게 변경할 수 있습니다.
- 기존 아키텍쳐의 blob-like artifact와 phase artifact 문제를 해결했으며 inversion이 더 잘 동작합니다.
🌟 inversion → 한 장의 이미지를 가지고 있을때 그 이미지를 만들 수 있는 Latent vector를 찾는 과정 ( 논문마다 표현법이 다름 , mapping encoding 등)
GAN Inversion 은 입력 이미지와 유사한 결과 이미지를 얻을 수 있도록 하는 latent vector를 찾는 과정입니다.
일반적으로 GAN이 학습되면 random latent vector로부터 이미지를 생성해낼 수 있게 됩니다.
GAN Inversion은 이의 역과정 입니다. 우리가 latent vector를 알기 원하는 이미지에 넣었을 때 GAN의 latent space의 latent vector로 input image를 inverting 시키는 것입니다.


- StyleGAN2 의 이미지 생성 결과를 truncation trick에 따라서 확인할 수 있습니다.
- Low FFHQ → 값이 작을 수록 퀄리티가 높지만 이미지의 다양성이 낮음
- High FFHQ → 다양한 이미지를 만들수 있지만 평균에서 멀어져서 이미지를 더욱 어색하게 만들어질 수 있음.
- 퀄리티를 높일지 다양성을 높일지 선택할 수 있도록 해주는 장치가 truncation trick
GAN 분야의 배경지식

- 생성자(Generator)와 판별자(Discriminator) 두 개의 네트워크를 활용한 생성 모델
- Genrator : new data instance → 여기서 인스턴스는 사진 한 장과 같은 데이터 단위
- Discriminator : 진짜 이미지와 가짜 이미지를 판별할 수 있도록 학습 ( Real:1 , Fake:0 )
PGGAN - Progressive Growing of GANs



Style GAN2 의 Contribution
- 본 논문에서는 W space에서의 analysis를 진행합니다.
- 이전 연구와 마찬가지로 Z → W 매핑 네트워크를 사용합니다.
- 기존 아키텍처의 문제점을 지적합니다.
- AdaIN style transfoer → blob-like artifect 발생
- Progressive growing → 얼굴의 특정 부분이 fixed position을 갖는 문제 발생
⭐️ blob-like artifect → 생성된 이미지는 물방울같은 모양의 blob한 Artifects가 관찰됩니다.
- 64 x 64 해상도를 중심으로 나타나기 시작하고 점점 강해집니다.
- 최종 이미지에는 잘 안보이더라도 중간 피처맵에서 존재
- 이는 각 feature map의 mean과 variance를 개별적으로 normalize 함으로써 feature map간 상대적 차이에서 나오는 크기 정보를 잠재적으로 파괴하는 AdaIN의 문제로 발생한다고 본다.
- ( 저자들의 가정 ) → 실제 데이터 기반의 통계 기반의 강력하고 localized 된 spike를 만듦으로써 Generator가 다른 원하는 곳에 효과적인 신호를 줄 수 있다고 판단. 실제로 AdaIN 부분의 normalization을 Generator에서 제거했을 때 artifact가 완전히 사라짐.
- 성능을 개선하기 위한 방법을 제안합니다.
- Path length regularzation
- A fixed-size step in W results in a fixed-magnitude change in the image.
- 결과적으로 latent interpolation에 따라서 이미지가 부드러운(smooth) 변화를 보이게 됩니다.
- 이미지를 latent vector로 inversion하는 새로운 알고리즘 제안.
- Path length regularzation
GAN 발전 과정

- 빨간색으로 네모된 부분이 FID 스코어, PGGAN → StyleGAN → StyleGAN2 로 갈수록 점수가 개선되는 것을 확인할 수 있습니다. ( 점수가 낮을수록 성능이 좋음 )
- 본 논문에서 강조하는 Path Length 역시 지속적으로 감소함.
- PPL(Perceptual Path Length)지표는 모양의 안정성과 일관성과 연관이 깊기에 이를 regularizer로 활용함으로써 이미지의 질적 향상을 이룰 수 있다.
Style GAN의 문제 상황 1. Blob-like ( Droplet ) Artifacts

Figure 15에서 보이듯 초기 resolution feature map에서 droplet이 없는 경우(2행) , overshot , curupted image( 심각하게 문제되는 이미지)가발생되지만 1행과 같이 droplet이 지속적으로 생기는 경우 일부분만 문제가 된다.
- 물방울(water droplet) 형태의 인공물 → 인간이 보기에 정상적인 이미지가 아님.
Feature map 상에서
- Droplet artifact가 있는 경우
- Normal 이미지 생성
- 대부분 결과가 정상 99.9%
- Droplet artifact가 없는 경우
- Corrupted 이미지 생성
- 약 0.1% 확률로 발생
( 나동빈 comment ) → Latent manipulation 과정에서 쉽게 발견되는 문제
StyleGAN의 문제 상황 2. Phase Artifact


- Latent manipulation 과정에서 특정 요소가 고정됨.
- Progressive growing이 원인으로 추정됨.
- 각 resolution이 iutput resolution에 즉시 영향을 미침
- 최대한 높은 frequency detail을 생성하고자 함.
- 각 resolution이 iutput resolution에 즉시 영향을 미침
→ 본 논문에서는 Progressive growing 을 제거
StyleGAN2 : Removing Normalization Artifacts
- AdaIN 은 각 feature map의 mean/std를 개별적으로 정규화해 서로 연관된 feature 들의 정보가 소실될 수 있습니다.
- Normalization mean/std → Modulate mean/std
- 또한 본 논문의 저자들은 standard deviation만 변경해도 충분하다는 것을 알아냈습니다.
- 결과적으로 standard deviation만 변경하면서, 최대한 style block의 외부에서 feature map들의 값을 변경하고자 합니다.
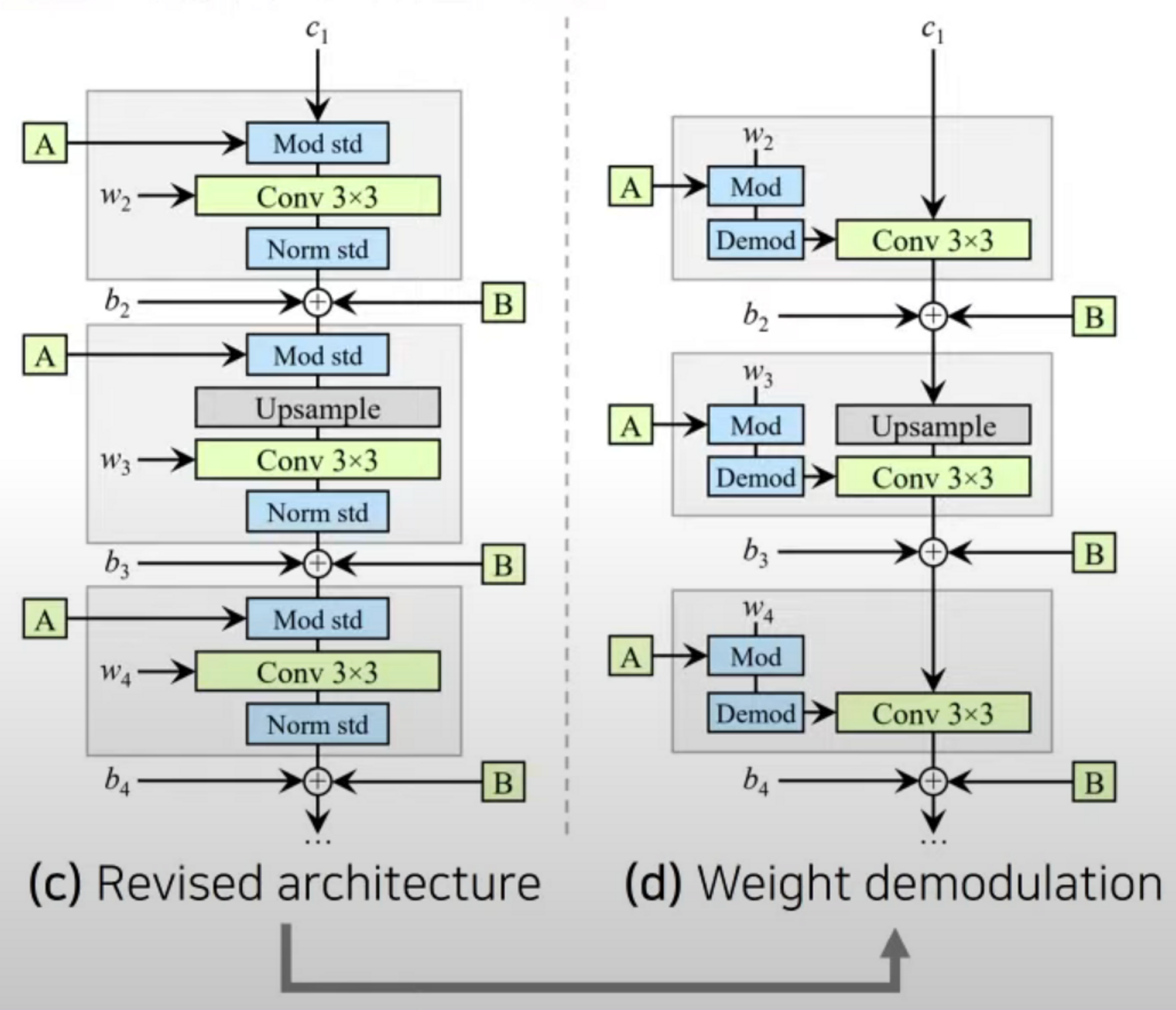
- 더 나아가 convolution 연산을 거친 feature map에 대해 바로 modulation을 적용하지 않도록 합니다.
- 대신에 weight 값에 대하여 modulation을 진행합니다.
- 핵심 아이디어 : 직접적으로 정규화를 하지 않고 feature map의 statistics를 예측하여 정규화를 적용합니다.
- Modulation 을 할 때 convolution weight를 대신 scaling 하는 방법을 사용할 수 있음.
- Modulated wieghts
- Modulation 을 할 때 convolution weight를 대신 scaling 하는 방법을 사용할 수 있음.
- 모든 input activation이 i.i.d. random variable 일 때 ( with unit std )
- 기대되는 Output activation의 std
- 즉, 다음의 w’’로 convolution 연산을 하면 됩니다.
- 이로써 기존의 AdaIN의 기능을 대체하는 것이 가능.
- 기존의 AdaIN을 사용하는 것과 다르지 않지만 아키텍쳐를 바꿈으로써 feature map을 직접적으로 건드리지 않고 Convolution에 사용되는 weight 값만 바꿔주었기 때문에 서로 연결되어 있는 feature들의 연관성을 덜 헤치기 때문에 결과적으로 더 좋은 이미지가 생성된다.
⭐️ AdaIN
AdaIN은 content 이미지 x에 style 이미지 y의 스타일을 입힐 때 사용하는 Normalization으로 style transfer에 거의 공식적으로 사용됩니다.
기존 AdaIn과 비교하면, convolution을 거친 featuremap이 AdaIN의 content이미지의 역할이고 w 가 style이미지의 역할입니다.
feature map은 statistic하게 normalization되고 w으로 부터 나온 scaling factor와 곱해지고, bais factor가 더해집니다. normalize연산은 AdaIN,IN과 동일하게 당연히 channel specific하게 진행됩니다.
adaptive instance normalization (AdaIN) → 이 방법은 간단하게 content 와 style input 이 주어졌을 때, 두 입력의 평균과 분산을 style input과 동일하도록 조절합니다. (이때, content를 먼저 맞춘 후에 style을 맞춰줍니다.)
그리고 decoder network는 AdaIN output을 다시 image space로 inverting 함으로써 마지막 stylized image를 생성하도록 학습합니다.


- Style GAN 은 high-resolution 이미지를 효과적으로 생성하지만, visible artifacts가 존재
- Style GAN2를 이용햇을 때 droplet artifact가 제거되고 결과 이미지의 quality가 좋아진 것을 확인할 수 있습니다.
- Weight demodulation 이 있는 경우
- 각 스타일이 generator에서 적절히 localized 됩니다.
- 왼쪽 애니메이션에서는 coarse-grained 한 스타일이 고정된 상태로 fine-resolution 스타일이 효과적으로 변경되는 것을 알 수 있습니다.
→ 이미지가 변화하는 과정을 인간이 예측할 수 있을 정도로 전반적으로 모든 이미지가 같은 방식으로 변ㄱ여
- Weigth demodulation 이 없는 경우
- Scale-specific하지 않으며, 스타일이 누적됩니다.
- High-level과 low-level feature를 적절히 섞기 어렵다.
- Overshooting( 급격한 변동 ) : 특정한 style combination이 artifacts를 생성합니다.
- Leaking : 특정한 feature 들이 여러 개의 스타잉ㄹ(배경, 인종, 등)로부터 영향을 받습니다.
StyleGAN2: Image Quality and Generator Smoothness
- FID 혹은 Precision & Recall score 가 같더라도 PPL 에 따라서 image quality가 달라질 수 있습니다.
- PPL(Perceptual Path Length)이 낮을수록 더욱 자동차 모양의 ( car-shaped ) object를 잘 생성합니다.
- Model 2 : config f / Model 1 : config A
- 결과적으로 본 논문에서는 PPL을 낮추는 방법을 적용
⭐️PPL(Perceptual Path Length) : Latent Vector 가 변경됨에 따라서 이미지가 얼마나 부드럽게 바뀔 수 있는지 수치적으로 나타난 점수.

- ImageNet으로 학습한 분류 모델은 shape보다는 texture에 기반하여 decision을 내립니다. ( texture-biased )
- FID나 P&R은 Inception V3나 VGG에서 온 higf-level feature에 기반합니다.
- 반면에 인간은 texture 보다 shape에 더 큰 영향을 받습닏.
- 예를 들어, 인간은 펜으로 단순하게 그린 그림도 쉽게 사물로 인식할 수 있습니다.
- Smaller PPL appears to correlate with higher overall image quality
- PPL이 작도록 학습하면? 학습 과정에서 artifact가 포함된 broken image에 penalty를 줍니다.
- 좋은 이미지를 만들 수 있는 latent spacce의 region을 효과적으로 stretch 할 수 있습니다.
( 저자들의 주장 )FID나 P&R 는 전통적인 평가 방식이므로 새로운 평가 지표인 PPL을 사용해야 한다. PPL이 낮을수록 높은 이미지 퀄리티를 가질 수 있다.
- 어떻게 PPL을 줄일 수 있을까? 단순히 PPL을 줄이긴 어려우므로 path length regularize를 사용
- Lazy Regularization
- Main Loss Function 보다 regularization term을 적게 계산해 computational resource를 아낄 수 있습니다.
- 실제로 16번의 mini-batch마다 한 번씩 R1 regularization과 path length regularization을 적용해도 충분했습니다.
- Path Length Regularization
- 네트워크가 신뢰할 수 있는 방향으로 동작하도록 만듭니다.
- 이러한 regularizer를 사용해 학습을 진행하면 jacob matrix Jw 가 w에 대하여 orthogonal하도록 유도됩니다.
- 방향과 상관없이 w가 일정하게 움직이는 만큼 G(w)도 일정하게(특정항 length만큼) 움직이게 됩니다.
- 이렇게 생성된 smmother generator가 더욱 inversion이 잘 됩니다.
StyleGAN2 : Progressive Growing Revisited
- Progressively-grown generator의 문제점 : 치아나 눈이 부드럽게 이동하지 않는 경우가 많다.
- 자주 보이는 현상 : “Strong location preference” for details like teeth and eyes
- Next preferred location으로 jumping 하기 전에 특정 부분(치아 등)이 stuck됩니다.
- Phase artifact 문제가 발생하는 원인?
- PGGAN은 각 resolution마다 충분히 학습을 마치고 다음 resolution을 학습합니다.
- 이때 각 resolution은 output resolution에 대해서 최선의 결과를 만들고자 합니다
- 결과적으로 intermediate layer에서 과도한 high frequency detail을 유발합니다.
- PGGAN은 각 resolution마다 충분히 학습을 마치고 다음 resolution을 학습합니다.
- Latent manipulation 과정에서 특정 요소(teeth 등)가 고정됨
- Prgressive growing 대신에 단순한 feedforward 네트워크를 사용하는 방식을 다시 사용합니다.
- PGGAN은 각 resolution마다 완전히 학습하며 먼저 low-resolution features를 만들고, finer detail을 채우는 방식입니다.
- Progressive growing을 사용하지 않는 본 논문의 3개 아키텍쳐들은 higher-resolution 레이어에 의해서 크게 영향을 받지 않는 low resolution 이미지를 생성합니다.
- MSG-GAN 은 Multi skip connection 을 사용해 G와 D의 해상도를 매칭합니다.
- 참고 : 일반적인 U-net 구조는 생성자 G 안에서만 skip connection 적용
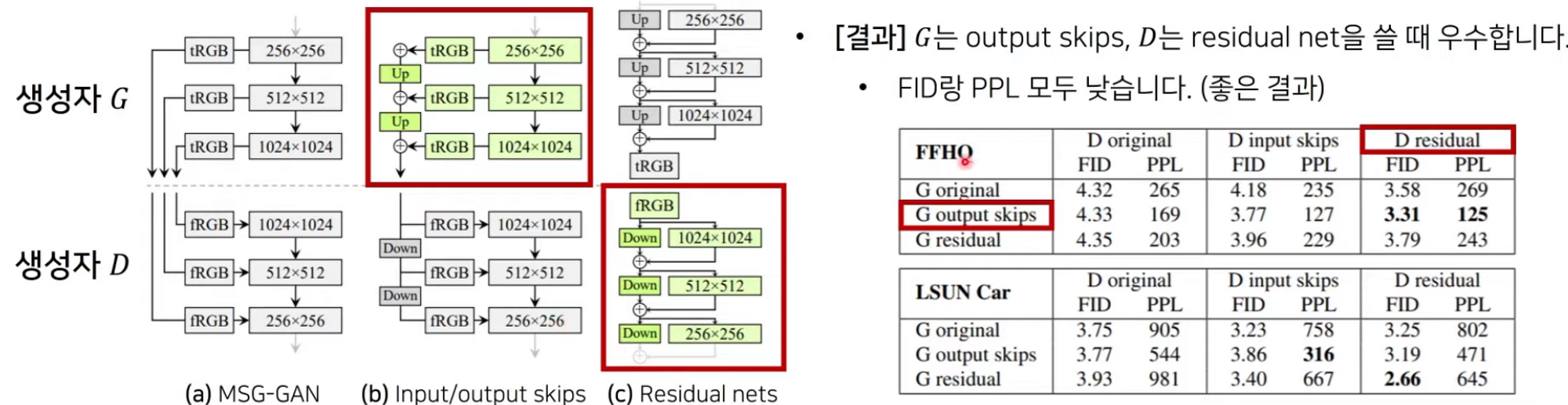
- Style GAN2 는 progressive growing의 장점을 유지한 상태로 단점을 개선
StyleGAN2 : Resolution Usage
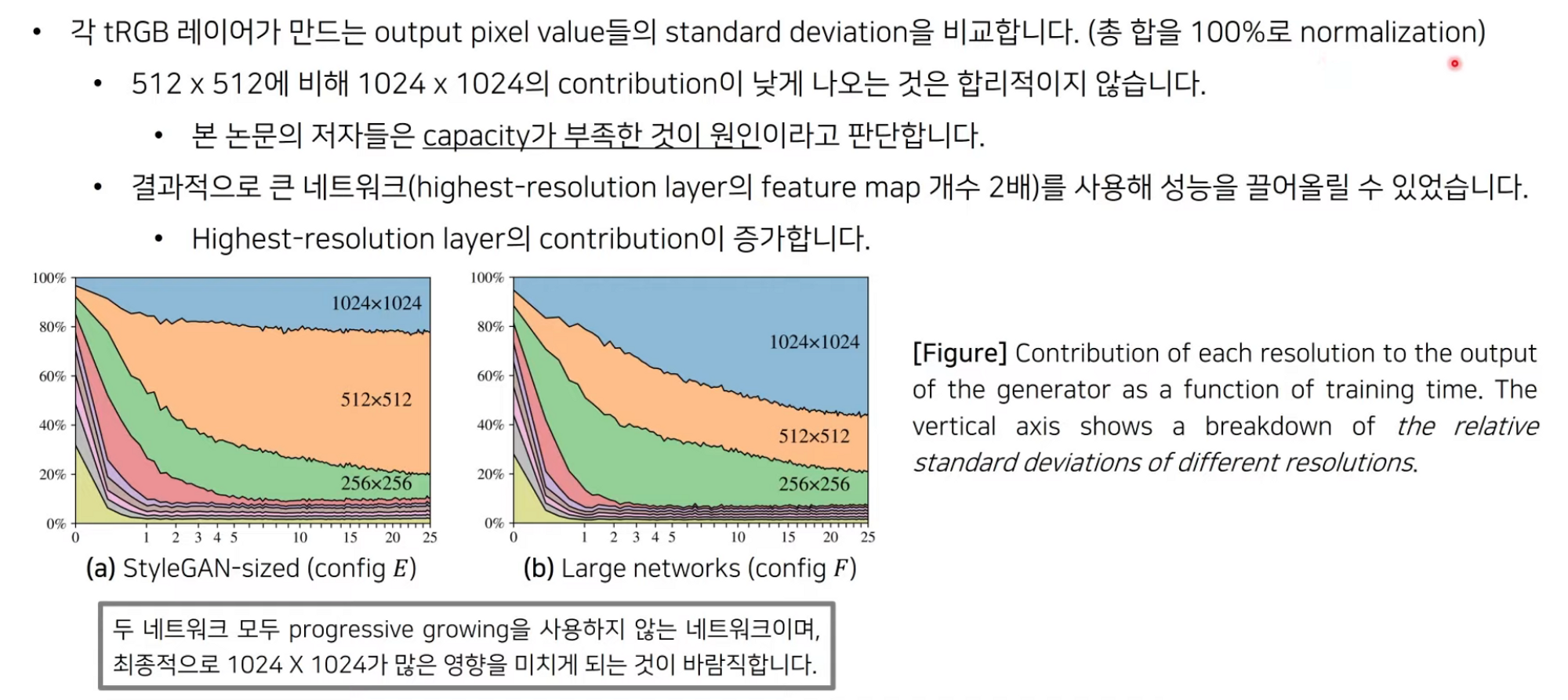
연구 배경 : Image Manipulation Using StyleGAN

- 이미지 x를 입력으로 받을 때 이러한 x를 만드는 latent vector를 찾는 과정을 Encoding step 이라고 한다. 적절한 w를 인코딩 하였다면
- Manipulation 을 진행하여 latent vector를 업데이트하여 웃는 표정으로 바꿈.
연구 배경 : StyleGAN Encoding (Inversion) : Gradient Descent

StyleGAN2 : Inversion
- 본 논문은 새로운 Projection(inversion) method를 제안합니다.
- 확장된 latent space를 사용하지 않고, generator가 충분히 만들 수 있는 수준의 이미지를 생성하도록 w를 업데이트
- Style noise 를 ramped-down 방식으로 업데이트하여 종합적으로 latent space를 탐색하도록 합니다.
- Stochastic noise 또한 최적화를 진행합니다.
- 간섭이 있는 signal 을 예방합니다.
- 생성된 가짜 이미지의 경우 inversion이 더 잘 이루어집니다.
Conclusion
