Book- fastai와 파이토치가 만나 꽃피운 딥러닝
Fastai 는 제레미 하워드라는 사람이 만든 Pytorch의 상위 wrapper 라고 생각하면 됩니다.
Pytorch를 한번 더 감싸서 많은 것들을 자동화 시켜주고 모델러들이 핵심에 집중할 수 있도록 하는 것을 목표로 합니다.
실제로 코드를 보면 Pytorch 나 Tensorflow처럼 복잡한 로직이 필요없고 간단하게 원하는 모델을 구현할 수 있다.

위의 두 줄의 명령어의 실행이 완료된 다음, 반드시 런타임을 재시작 해야합니다.
마이크로소프트 Bing 검색엔진을 통한 이미지 검색 등의 라이브러리는 FASTAI 차원에서 제공하는 일반화된 라이브러리가 아닙니다. 다만, 책 내용의 실습을 위해서 fastbook 저장소에서 별도로 작성되어 제공됩니다.
교재에서는 search_images_bing 을 사용하여 Bing 검색엔진에서 이미지를 다운로드 하여 활용합니다.
Bing으로부터 이미지 다운로드 및 데이터 셋 구축
Azure Cognitive Service API 키 값
MS Azure 의 계정에 가입을 하신 후 API 키를 발급 받으셔야 합니다. 자세한 내용은 아래 포스팅 내용을 참고해주세요.
코드의 전반적인 내용은 아래의 블로그 코드와 교재의 내용을 함께 다룹니다.
https://fast-ai-kr.github.io/tutorials/disney_character_classification/
디즈니 캐릭터 분류 모델
fastai 라이브러리를 사용한 디즈니 캐릭터 분류 모델 만들어보는 튜토리얼 노트북입니다. fastbook의 라이브러리의 일부를 사용하는 방법과, MS Azure의 Cognitive Service를 활용하여 이미지 검색/다운로
fast-ai-kr.github.io
Fastai Tip
search_images_bing 등의 API 를 사용하고 싶다면 fastbook 패키지를 import 해줘야 합니다.

fastbook의 유틸리티 함수로서 작성된 함수의 목록
- searc_images_bing
- plot_function
- draw_tree
- cluster_column
Path는 fastai에서 개발한 fastcore에 포함된 기초 라이브러리로, 기본적으로는 Python에서 표준적으로 제공하는 pathlib.Path 를 확장한 것. pathlib.Path의 기능을 모두 그대로 사용 가능하지만, 여기에 다음의 몇 가지 편의 사항을 추가함.
- readlines()
- read()
- write()
- save()
- load()
- ls()
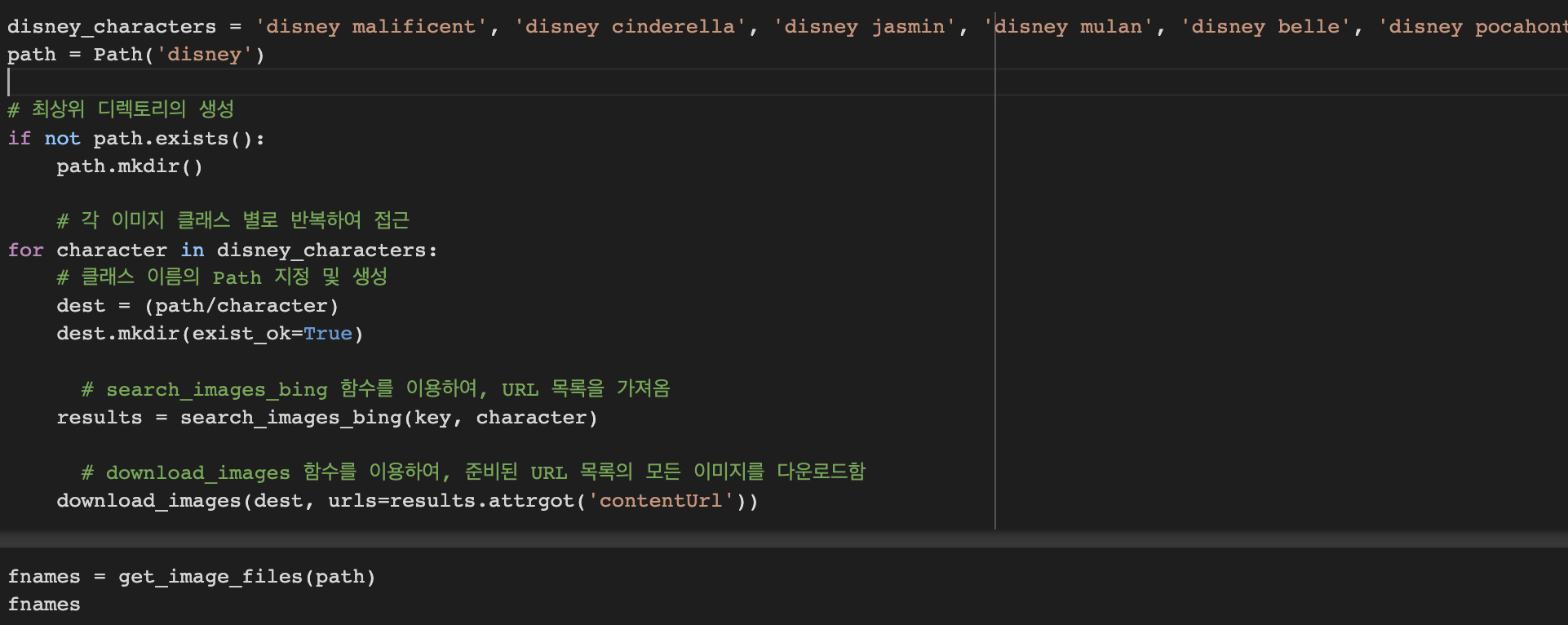
search_images_bing : 함수를 이용하여 URL 목록을 가져옴
- Azure Cognitive Service API Key 및 검색하고자 하는 키워드를 파라미터로서 제공해 줘야함.
- 이 함수가 반환하는 객체는 Python의 표준 객체인 list를 확장한 L이라는 객체임. (fastcore)
download_images : 함수를 이용하여, 준비된 URL 목록의 모든 이미지를 다운로드함.
- 정확히는 results가 URL의 목록은 아니며, Bing Search Service가 반환한 JSON 포맷의 내용임.
- L 객체는 attrgot 이라는 메서드를 제공하는데, 리스트에 포함된 모든 아이템으로부터 인자로 지정된 속성의 값들만을 추출하여, 별도의 리스트 반환
- 첫 번째 인자인 dest가 이미지 다운로드 후 저장될 위치.
모든 이미지 파일의 Path 목록
fastai에서 제공하는 get_image_files는 지정된 Path를 기점으로, 하위에 포함된 모든 이미지 목록을 재귀적으로 검색하여 들고옴. 구분없이 몽땅 들고오는 이유는 다음과 같음.
- 다운로드된 이미지는 폴더 이름 단위로 클래스가 구분됌.
- 이후 DataBlock 또는 ImageDataLoaders 객체 생성시 클래스를 구분해내기 위한 로직 추가가 가능함.
- 구분하는 별도의 함수를 만들게 되며, 단순히 규칙을 지정해 주기만 하면 된다.
코드의 실행결과는 fnames 객체 내용을 출력
- 출력 결과의 앞 부분은 리스트에 포함된 아이템의 개수를 의미함. 원래 표준 list 객체는 이러한 정보를 출력하지 않으나, L은 출력하는 특성이 있음.
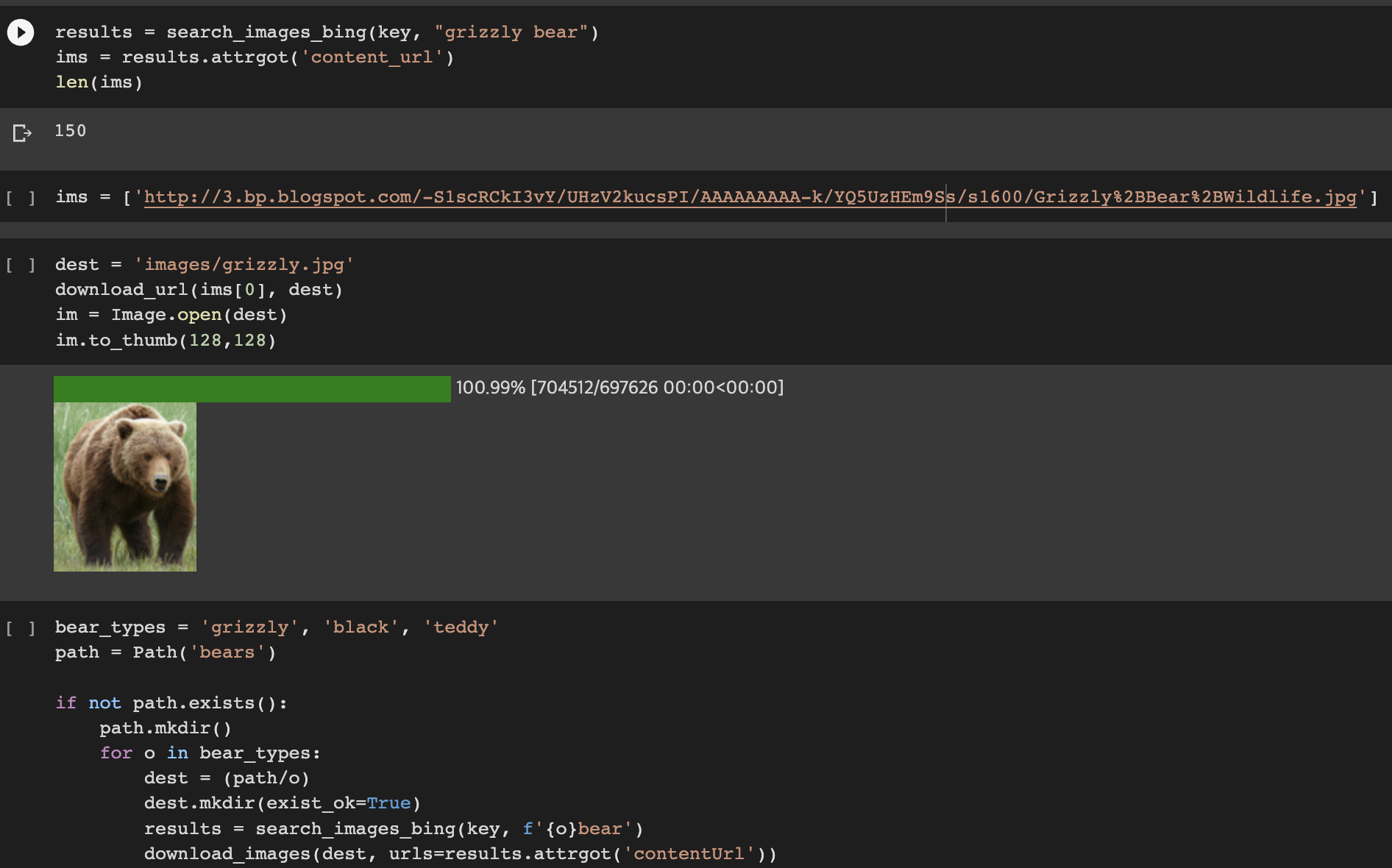
다음은 교재에서 작성한 코드입니다.
공통적으로 사용되는 코드와 변수는 그냥 외우는게 좋을 것 같습니다.
예를 들어 dest는 클래스 이름과 같은 path를 지정 및 생성하고, download_images와 같은 코드죠.
코드를 작성하는 방법이 조금 다르지만 결국에는 클래스별로 폴더를 따로 생성하고 클래스별 이미지 url 을 가져오는 것은 똑같습니다.

망가진 링크의 이미지를 검사하여, 그 목록을 삭제하기
L 객체에는 함수형 언어적 기능인 map 메서드가 구현되어 있음. map 메서드가 호출되는 순간, 각 아이템을 반복적으로 접근하면서, 제공된 함수를 각 아이템에 적용하여 반환된 결과를 싹 모아서 새로운 L 객체를 만들어줌.
Path.unlink 라는 함수가 하는 일은 failed에 포함된 모든 아이템(Path)에 대하여, 파일을 삭제하는 일을 수행.
망가진 링크의 이미지를 검사하여, 그 목록을 삭제하기
L 객체에는 함수형 언어적 기능인 map 메서드가 구현되어 있음. map 메서드가 호출되는 순간, 각 아이템을 반복적으로 접근하면서, 제공된 함수를 각 아이템에 적용하여 반환된 결과를 싹 모아서 새로운 L 객체를 만들어줌.
Path.unlink 라는 함수가 하는 일은 failed에 포함된 모든 아이템(Path)에 대하여, 파일을 삭제하는 일을 수행.
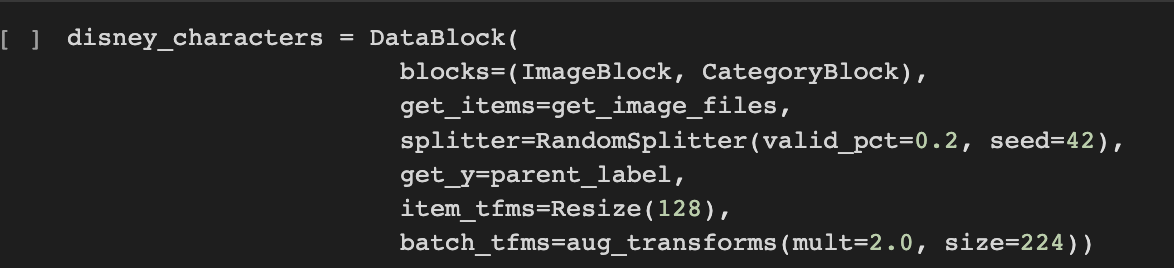
DataBlock 의 생성
DataBlock은 DataLoaders를 만들기 위한 저수준의 API. 각 인자가 가지는 의미는
- blocks: Block의 리스트. Block은 데이터를 표현하는 수단
- 두 개 이상의, 여러개의 Block을 지정하는것도 가능함. 단, 이때는 n_inp 라는 파라미터의 값을 조절하여, 입력으로 사용될 Block이 몇 개인지를 지정해 줘야만 함. 예를 들어서 blocks=(ImageBlock, BBoxBlock, BBoxLblBlock) 처럼 설정했는데 그 중 첫번째만을 입력으로 삼고 싶다면, n_inp=1 이라고 지정해 줘야하만함.
- 이미지처리 관련, 정의된 Block은 다음과 같은것들이 있음. 기본적으로 모두, TransformBlock 인스턴스를 반환함. TransformBlock은 단순히, type_tfms, item_tfms, batch_tfms, dl_type, dls_kwargs 내용들을 잡아두기 위한 Wrapper 클래스임.
- ImageBlock
- MaskBlock
- PointBlock
- BBoxBlock
- BBoxLblBlock
- get_items: 데이터를 가져오기 위한 함수를 지정
- DataBlock 생성 후, DataLoaders를 반환받기 위해서, dataloaders()라는 메서드를 사용하게 됨. dataloaders() 메서드에는 경로(Path)를 지정해 주게 되어 있는데, 이 경로를 기반으로 get_items의 행동이 결정됨.
- 가령 아래처럼 get_image_files를 지정하면, dataloaders(path) 메서드 호출시, path 밑에 딸린 모든 이미지를 긁어오게됨
- splitter: 데이터를 학습/검증으로 분리해내기 위한 수단을 지정
- 다양한 Splitter 클래스가 존재함
- RandomSplitter
- TrainTestSplitter
- IndexSplitter
- GrandparentSplitter
- FuncSplitter
- MaskSplitter
- FileSplitter
- ColSplitter
- RandomSubsetSplitter
- 경우에 따라서, 데이터셋이 미리 train/valid 와 같은 디렉토리로 나뉘어져 제공되는 경우가 있음.
- 이 때는 splitter에 할당되는 객체의 valid_pct값을 지정하지 않으면 됨. 그러면 자동으로 train 및 valid라는 이름의 디렉토리를 대상으로 삼음. 즉, 다른 이름의 디렉토리라면, 이 이름을 train 및 valid 라는 이름으로 맞춰줘야함.
- get_y: 레이블을 지정하는 수단을 지정
- blocks의 출력 개수가 여러개 될 수 있듯이, get_y 또한 여러개가 지정될 수 있다. 이 경우는 리스트에 두 개의 함수를 포함시켜주면 됨.
- 기본 제공 parent_label은 단순히, 부모 디렉토리명을 레이블로 보겠다는 뜻이된다.
- RegexLabeller도 기본제공되는데 regex 기반으로 레이블을 지정할 수 있어서, 매우 강력함.
- item_tfms: 각 아이템 별 데이터 변형
- 보통 이미지의 경우, Resize를 해줌
- 왜 Resize를 batch_tfms에서 해주지 않는가 하면, 이미지의 크기가 모두 제각각이기 때문임. GPU는 동일한 크기, 동일한 연산을 동시 다발적 (배치 단위)으로 단순히 계산하는데 최적화 되어 있음. 따라서, 모두 제각각인 이미지를 일단 최초에 동일한 크기로 맞추는 작업은 개별적으로 CPU에서 수행될 필요가 있음.
- batch_tfms: 배치단위의 데이터 변형
- item_tfms에서 모두 동일한 크기로 맞춰지거나, 쨋든 GPU에서 배치단위로 계산되기에 최적화된 데이터 묶음에 대하여, 묶음 형태의 데이터 변형을 가한다.
- 여러가지 변형 방법이 기술될 수 있지만, aug_transforms 를 사용하는것이 초반에는 선호됨. 다양한 데이터 증강 기법들이 모두 포함되어 있음.
약간 상위레벨에서 보자면, 크게 세 종류의 변형(Transform)이 일어남
- Type Transform
- blocks 인자를 통해서, 입력/출력에 대한 Type 변형
- Item Transform
- item_tfms 인자를 통해서, 각 아이템별 데이터 변형
- Batch Transform
- batch_tfms 인자를 통해서, 배치단위의 데이터 변형
DataBlock API
이미 정의된 메서드에 들어맞는 상황을 다룰 때는 팩토리 메서드 factory method 를 접했습니다.
그런데 딱 들어맞는 메서드가 없으면 어떻게 해야 할까요? fastai는 이러한 상황에 사용할 수 있는 데이터블록 datablock 이라는 유연한 시스템을 제공합니다. 데이터 블록 API를 사용해 DataLoaders 생성에 관련된 모든 단계를 완전히 사용자의 상황에 맞게 정의할 수 있습니다.
DataLoaders
fastai가 제공하는 여러 DataLoader를 저장하는 클래스입니다. 개수 제한 없이 원하는 만큼 DataLoader를 저장할 수 있지만, 보통 학습용과 검증용으로 DataLoader 두 개를 저장합니다. 상기 코드에서 알 수 있듯이 처음 저장된 두 DataLoader를 train과 valid라는 속성으로 지정합니다.


DataBlock 은 "어떻게 어떻게 데이터를 구성하겠다" 와 같은 일종의 선언문입니다. 이것이 실제 적용된 결과를 얻기 위해서는 , DataBlock에 실제 데이터의 정보를 흘려줄 필요가 있습니다. DataBlock에는 dataloaders라는 메서드가 있는데, 이 메서드에 이미지들이 들어있는 경로를 지정해주면 됩니다.
교재에서는 DataLoaders 클래스를 위와 같이 정의한 후에 DataBlock을 작성해줍니다.
위의 disney_characters의 내용과 동일하게 작성합니다.


각 인자를 살펴보면서 어떤 DataBlock 객체가 만들어지는지 확인했습니다. 이 객체는 DataLoaders 를 생성하는 템플릿과도 같쇼ㅡㅂ니다.
DataLoaders를 생성하는 dataloaders 메서드를 보면 템플릿이라고 표현한 이유를 알 수 있습니다. dataloaders 메서드를 호출할 때 비로소 실제 데이터의 경로를 지정하기 때문.
앞서 이미지를 다운로드 해둔 경로를 담은 path 를 지정해줍니다.
DataLoader 클래스는 한 번에 여러 배치 batch 를 GPU로 제공하는 역할도 담당합니다. DataLoader에 반복적으로 접근하면, 기본으로 한 번에 64개의 요소를 들고 옵니다. 즉 요소 64개가 텐서 하나에 쌓입니다.
fastai는 DataLoader에 show_batch 라는 편의성 메서드를 구현해 두었는데, 하나의 배치의 요소 중 일부를 화면에 출력할 수 있는 기능을 제공합니다.
이를 통해 데이터블록 API가 구성한 데이터를 모델에 주입하기 전에 미리 확인 가능합니다.
모델 훈련과 훈련된 모델을 이용한 데이터 정리

fastai의 cnn_learner 메서드를 이용해 dls를 훈련시킵니다.
learner 객체는 cnn_learner 함수가 반환하는 객체입니다.

오차 행렬 confusion matrix 를 만들어 모델의 실수를 파악할 수 있습니다.
오차 행렬에서 행은 데이터셋에 지정된 곰의 유형을 표현하고 열은 모델이 예측한 곰의 유형을 표현합니다.
따라서 올바르게 분류한 이미지는 대각선에 표시되고 잘못 분류한 이미지는 그 외의 위치에 표시됩니다.
결과는 짙은 파란색 대각선을 제외한 나머지가 모두 흰색이 되는 상태가 가장 이상적입니다. 모두 흰색이라는 것은 모델이 실수를 단 한 번도 하지 않았음을 의미합니다.

손실 Loss
손실에 관한 내용은 교재에만 나와있습니다.
손실은 모델이 올바르지 않거나 올바르지만 결과를 신뢰할 수 없으면 값이 높아집니다. 손실을 계산하는 방법, 모델의 학습 과정에서 손실이 사용되는 방식 등 손실에 관한 자세한 내용은 추후에 다루게 됩니다.
지금은 plot_top_losses 메서드가 가장 손실이 높은 이미지를 보여준다는 점만 알아둡니다.
출력된 이미지는 예측된 범주 / 실제 범주 ( 타깃 레이블 ) / 손실 / 확률 정보도 포함합니다.
여기서 확률이란 0부터 1 사잇값의 신뢰 수준을 의미합니다.

출력 내용을 보면 가장 손실이 큰 이미지는 "grizzly" 회색곰 이라고 예측한 이미지입니다.
그리고 신뢰도를 보면 모델은 예측이 올바르다고 매우 확신함을 알 수 있습니다. 하지만 빙 이미지 검색에서 "black 흑곰" 으로 레이블링 되었습니다.
즉 모델은 올바르게 예측하였으나 레이블이 틀렸으니, 레이블을 'grizzly'로 바꿔야 합니다
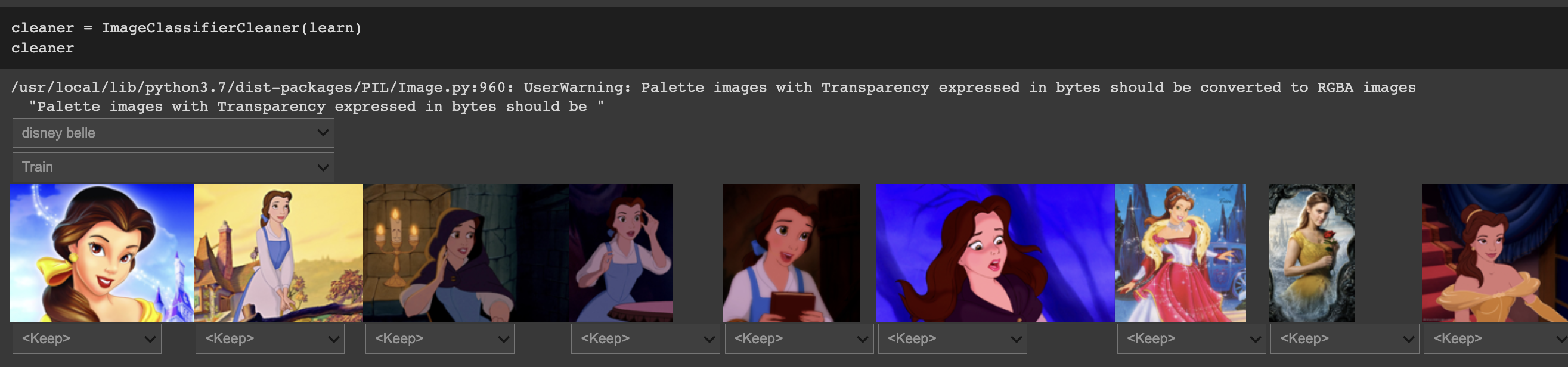
마지막에는 ImageClassifierCleaner 를 통해 마무리합니다.