
Validation ( 검증 )
머신러닝의 프로세스에서 전체 데이터를 학습데이터와 훈련데이터로 나누는 단계는 매우 중요한 단계입니다.
학습 데이터로 모델을 생성한 뒤에 중간 과정을 생략한 후 테스트 데이터로 모델을 평가한다면, 이렇게 생성된 모델은 과적합이나 과소적합이 발생할 우려가 있습니다.
이런 문제를 해결하기 위해서 테스트 데이터 전에 자신을 점검해 볼 수 있는 과정이 필요한데, 그 과정을 검증(Validation)이라고 하며 검증에 사용하는 데이터셋을 검증 데이터셋(Validation dataset)이라고 합니다. 검증 데이터셋은 학습 데이터셋의 일부를 사용합니다.
Various Validation
머신러닝 모델의 검증 방법은 크게 3가지로 나눌 수 있습니다. 첫 번째가 Holdout, 두 번째가 K-fold CV, 마지막이 LOOCV 입니다.
각각에 대해 알아봅시다.
Holdout
Holdout 검증은 가장 기본적인 모델 검증 방법입니다.
전체 데이터에서 테스트 데이터를 분리하고, 남은 학습데이터의 일부를 검증 데이터로 분리하는 방법이죠. 즉, 전체 데이터를 3개(학습 데이터, 검증 데이터, 테스트 데이터)로 나누게 되는 것입니다.
하지만 학습데이터에 손실이 있기 때문에 너무 적은 데이터에는 사용이 어렵습니다. 그리고 검증을 한 차례만 할 수 있다는 단점이 있죠.

K-fold CV
holdout 의 단점을 개선하기 위해 사용하는 교차검증(Cross Validation, CV) 는 검증을 최소 2번 이상 진행합니다.
각 검증 결과치의 평균을 모델의 검증 결과로 사용하게 되죠.
교차검증의 대표적인 방식으로 K-Fold 교차검증(K-fold Validation) 이 있습니다.
K-fold 교차 검증은 학습 데이터를 k개로 나눈 뒤 차례대로 하나씩을 검증 데이터셋으로 활용하여 k번 검증을 진행하는 방식입니다.
이 방법도 학습 과정마다 학습 데이터에 손실이 있기는 하지만, 결국 전체 데이터를 다 볼 수 있다는 장점이 있고 검증 횟수를 늘릴 수 있다는 장점도 있습니다.
일반적으로 5 이상 11이하의 범위에서 K값을 설정합니다.
LOOCV(Leave-one-out cross validation)
LOOCV(Leave-one-out cross validation)는 K-fold 교차 검증의 극단적인 형태로, 학습 데이터셋이 극도로 작을 때 사용할 수 있는 교차검증 방법입니다. LOOCV는 오직 한 개의 인스턴스만을 검증 데이터셋으로 남겨 놓습니다(Leave-one-out). 검증 데이터가 하나이므로 학습 데이터가 총 NN 개라면 총 NN 번의 교차 검증을 진행하게 됩니다. 학습 데이터의 손실을 최소화 할 수 있지만, 샘플 데이터 수가 1000개만 되어도 총 1000번의 학습과 검증을 진행해야 하기 때문에 시간과 컴퓨팅 자원이 많이 소모된다는 단점이 있습니다. 아래는 LOOCV가 진행되는 방식을 그림으로 나타낸 것입니다.
아래는 위 3개의 검증 방법을 비교하는 이미지입니다.
Hyperparameter Optimization
검증을 통해서 과적합이 일어나는 지점을 찾는 것도 중요하지만, 성능이 좋은 모델을 찾는 것 역시 모델 검증을 해야하는 이유입니다.
더욱 성능이 좋은 모델을 만들기 위해 하이퍼파라미터를 최적화 해주어야 합니다.
하이퍼파라미터(Hyperparameter)는 학습 과정에서 모델이 알아서 바꾸는 파라미터 외에 모델을 만드는 사용자가 지정하는 파라미터를 의미합니다.
대표적으로 경사 하강법에서 학습률(learning rate) , 정규화(Regulation)의 정도를 조정하는 알파 등이 있습니다.
모델마다 설정해줘야 하는 하이퍼파라미터가 다르기 때문에 사용하는 모델에 따라 필요한 하이퍼파라미터를 적당히 조정해주어야 합니다.
최적의 하이퍼파라미터 조합을 찾는 것 역시 매우 중요한 과정이고 크게 4가지로 나눌 수 있습니다.
Manual Search
말 그대로 수동(Manual)으로 하이퍼파라미터를 조정하는 방식입니다. 모델을 설계하는 사람이 경험에 의한 직관을 사용하여 최적의파라미터 조합을 설정합니다.
Grid Search
하이퍼파라미터마다 적용하고 싶은 값의 목록을 설정해둔 뒤에 그 조합을 모두 시행해보고 최적의 조합을 찾아내는 방식입니다. 직관적으로 이해하기가 쉽지만 조정할 하이퍼 파라미터가많아지면 학습 횟수가 많아지는 단점이 있습니다. 예를 들어, 학습률 η=[0.001,0.01,0.1,1]η=[0.001,0.01,0.1,1] 로 4개, 정칙화 파라미터 α=[0.001,0.01,0.2,3]α=[0.001,0.01,0.2,3] 로 4개의 목록을 작성한 뒤에 각 조합에 대해 모두 학습을 수행하므로 총 4×4=164×4=16 번에 대한 학습 및 검증을 하게 됩니다.
Random Search
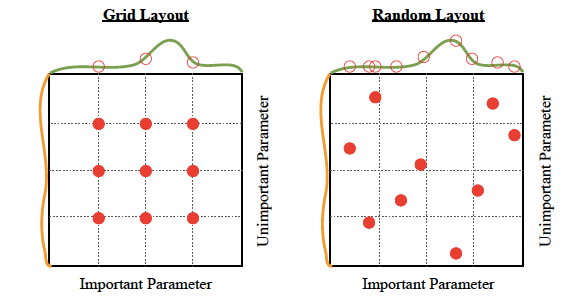
조정하고 싶은 하이퍼파라미터 마다 조정하고 싶은 범위를 정합니다. 실제 학습 과정에서는 범위 내에 있는 임의의 값을 설정하여 각 파라미터에 대한 조합을 정합니다. Grid search는 지정한 값에 대해서만 학습과 검증을 시도하지만 Random search는 범위 내에 있는 임의의 값에 대하여 예상치 못한 조합을 시도해볼 수 있다는 장점이 있습니다. 아래는 Grid search 탐색법과 Random search 탐색법을 비교할 수 있는 이미지입니다.
이 4가지 탐색법 외에도 베이지안 최적화(Beyesian Optimization) 등 다양한 하이퍼파라미터 탐색법이 있습니다.
베이지안 최적화에 대한 자세한 내용은 다음 포스팅에서 다뤄보도록 하겠습니다.
Evaluation
지금부터는 검증(Validation)과 테스트(Test) 단계에서 어떤 지표를 가지고 모델을 평가할 수 있는 지에 대해서 알아보겠습니다.
Confusion Matrix
분류(Classification)에서 가장 많이 사용되는 오차 행렬(Confusion matrix)에 대해서 알아보겠습니다. 오차 행렬은 각 인스턴스의 실제 클래스와 예측 클래스의 개수를 행렬의 성분에 채워넣은 것입니다. 아래 오차 행렬에서는 각 열에 예측 클래스를, 각 행에 실제 클래스를 배치하고 있습니다. (배치는 그리는 사람에 따라 달라질 수 있습니다)
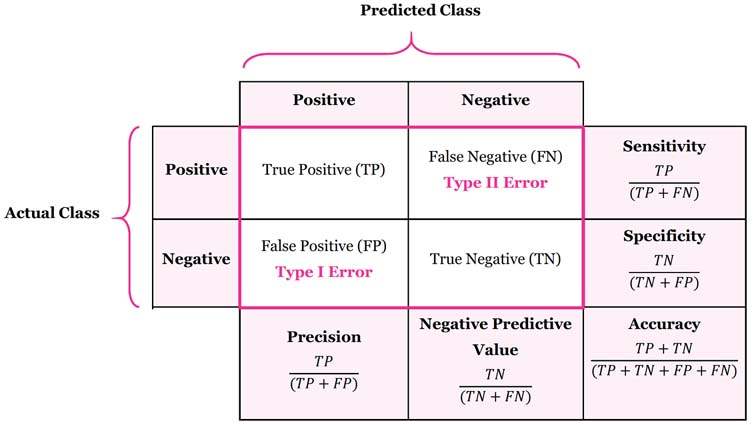
스팸 메일 분류의 예를 들어 보겠습니다. 정상적인 메일을 Negative클래스, 스팸 메일을 Positive클래스라고 하면 TP는 스팸 메일을 스팸 메일로 분류한 경우, FN은 스팸 메일을 정상 메일로 분류한 경우입니다. FP는 정상 메일을 스팸 메일로 분류한 경우이며 TN은 정상적인 메일을 정상 메일로 분류한 경우입니다. 다음은 이 4개의 성분(TP, FN, FP, TN)을 활용한 정확도와 정밀도 및 재현율에 대해 알아보겠습니다.
F-score(F-measure)는 정밀도와 재현율 수치를 한 번에 보기 위해서 만들어진 수치입니다. 가장 일반적으로 사용되는 수치는 F1-scoreF1-score 입니다. 이 수치는 정밀도와 재현율의 조화평균으로 정리하면 아래와 같은 수식으로 나타낼 수 있습니다.
분류 모델 성능 평가를 위해서 AUC(Area Under Curve) 역시 많이 사용됩니다. AUC는 말 뜻 그대로, ROC 곡선 아래의 넓이를 나타냅니다. ROC 곡선(Receiver Operation Characteristic Curve)은 2차대전 때 통신 장비의 성능을 평가하기 위해서 나온 수치입니다. ROC곡선은 FPR(False Positive rate)을 X축으로 TPR(True Positive rate)의 그래프입니다. FPR과 TPR은 오차 행렬 내 4개의 요소를 사용한 수치입니다.
혼동행렬에 대한 자세한 내용은 첫번째 포스팅을 참고하시면 도움이 될 것 같네요 !