
Why Genomics?
본 포스팅은 Coursera에 있는 Johns Hopkins University의 게놈 데이터 과학 특화 과정 강의를 정리한 내용입니다.
INTRODUCTION: 이 강의는 유전체학의 중요성과 그것이 우리에게 가르쳐 줄 수 있는 것들에 대해 설명합니다.
유전체학의 기본 개념
- 유전체학은 우리 몸 안의 유전체를 연구하는 분야로, 모든 인간은 99.9% 동일한 유전체를 가지고 있지만, 그 안의 작은 변화로 인해 다양한 차이가 발생합니다.
- 유전체는 우리의 발달과 생물학적 특성을 결정하며, 예를 들어, 신경세포와 피부세포는 동일한 유전체를 가지고 있지만 서로 다른 기능을 수행합니다.
암과 유전적 변이
- 암은 유전적 질병으로, 세포가 통제 없이 분열하는 현상으로 정의됩니다. 이는 유전체 내의 변이가 원인입니다.
- 변이는 DNA 복제 과정에서 발생할 수 있으며, 이러한 변이가 세포 분열을 조절하는 유전자에 영향을 미쳐 암을 유발할 수 있습니다.
정보 흐름과 유전체 분석
- 생물학의 중심 교리는 DNA에서 RNA, 그리고 단백질로 정보가 흐른다는 것입니다. 그러나 최근 연구에 따르면, 단백질이 다시 DNA에 영향을 미치는 피드백 루프도 존재합니다.
- 유전체 분석은 주로 시퀀싱 기술을 통해 이루어지며, 최근 20년간 기술 발전으로 인해 시퀀싱 비용이 크게 감소하고 있습니다. 현재는 개인 연구실에서도 많은 유전체를 빠르게 분석할 수 있습니다.
암이 발생하는 이유
유전체학에서 변이가 암을 유발하는 방식은 다음과 같습니다:
- 변이의 정의: 변이는 DNA의 염기 서열에서 발생하는 변화로, 이는 DNA 복제 과정에서의 오류나 외부 요인(예: 방사선, 화학물질 등)으로 인해 발생할 수 있습니다.
- 세포 분열과 변이: 세포가 분열할 때, DNA는 복제되어야 합니다. 이 과정에서 오류가 발생할 수 있으며, 이러한 오류가 변이를 초래합니다. 일반적으로 세포 분열 시 1~3개의 오류가 발생할 수 있습니다.
- 유전자 기능의 변화: 변이가 발생하면, 특정 유전자가 제대로 기능하지 않게 될 수 있습니다. 예를 들어, 세포 분열을 조절하는 유전자가 변이로 인해 비활성화되면, 세포는 통제 없이 계속 분열하게 됩니다.
- 암의 정의: 암은 이러한 비정상적인 세포 분열로 인해 발생하는 질병입니다. 변이가 특정 세포에서 발생하면, 그 세포는 암세포로 변모하게 됩니다.
- 다양한 암의 종류: 암은 발생한 세포의 종류에 따라 다르게 분류됩니다. 예를 들어, 피부세포에서 발생한 변이는 피부암(흑색종)으로, 폐세포에서 발생한 변이는 폐암으로 이어집니다.
DNA, RNA, Protein 간의 정보 흐름
DNA, RNA, 단백질 간의 정보 흐름은 생물학의 중심 교리인 "중심 교리"에 따라 다음과 같이 이루어집니다.
- DNA에서 RNA로의 전사 (Transcription):
- DNA는 유전 정보를 저장하는 분자로, 특정 유전자가 필요할 때 해당 유전자의 염기 서열이 RNA로 복사됩니다.
- 이 과정에서 DNA의 염기 서열이 RNA로 전사되며, 이때 티민(T)은 유라실(U)로 대체됩니다.
- RNA에서 단백질로의 번역 (Translation):
- 전사된 RNA는 메신저 RNA(mRNA)로 알려지며, 세포의 리보솜으로 이동합니다.
- 리보솜에서 mRNA의 염기 서열이 세 개씩 읽히며, 각 세 개의 염기는 특정 아미노산을 지정합니다. 이 과정을 번역이라고 합니다.
- 아미노산이 연결되어 단백질이 형성됩니다.
- 단백질의 기능:
- 단백질은 세포 내에서 다양한 기능을 수행하며, 효소, 구조 단백질, 호르몬 등으로 작용합니다.
- 단백질은 세포의 기능과 생리적 과정을 조절하는 데 중요한 역할을 합니다.
- 정보 흐름의 피드백:
- 최근 연구에 따르면, 단백질이 다시 DNA에 영향을 미치는 피드백 루프도 존재합니다. 특정 단백질이 DNA에 결합하여 유전자의 발현을 조절할 수 있습니다.
유전체 구조
염기 서열
- 정의: DNA는 아데닌(A), 사이토신(C), 구아닌(G), 티민(T)이라는 네 가지 염기로 구성되어 있습니다.
- 중요성: 이 염기 서열이 유전 정보를 저장하고 전달하는 기본 단위입니다.
- 염색체
- 정의: 유전체는 23쌍의 염색체로 구성되어 있으며, 각 염색체는 유전자의 집합체입니다.
- 중요성: 염색체의 구조는 유전자의 위치와 기능을 이해하는 데 필수적입니다.
- 센트로미어와 텔로미어
- 센트로미어: 염색체의 중앙 부분으로, 세포 분열 시 염색체가 올바르게 분리되도록 돕습니다.
- 텔로미어: 염색체의 끝부분으로, DNA의 손상을 방지하고 세포의 노화를 조절합니다.
유전체학이란?
The branch of molecular biology concerned with the structure, function, evolution and mapping of genomes.
과거의 생물학과 현대의 유전체학의 가장 큰 차이는 뭘까요 ?
과거에는 저 처리량 실험이라고 부르는 표적 실험만 할 수 있었습니다. 하나의 유기체 대신 한 번에 하나의 유전자를 연구하는 것이었죠. 오늘날 우리는 새로운 유전체학 기술을 사용하여 수천 개의 유전자 활동을 한꺼번에 측정하는 실험을 할 수 있습니다. 이것이 유전체학과 초기의 생물학의 가장 큰 차이점입니다.
과거에는 실험이 매우 어려웠으나 기술의 발달로 인해 더 쉽게 할 수 있는 방법들이 많아졌습니다.
Genome Data Science 란?

Statistical Genomics , Bioinformatics 등 다양한 이름으로 사용되지만 유전체 데이터 과학자의 활동은 모두 이와 같거나 유사한 범주에 속합니다.
생물학(Biology), 통계학(Statistics), 컴퓨터 과학(Computer Science) 등 세 가지 분야가 결합되어 유전체 데이터를 수집 및 분석하고 생물학적 결론을 도출하는 데 사용됩니다. 추가적으로 실험 설계, 데이터 전처리 및 정규화, 다양한 분석 기법이 포함될 수 있습니다.
분자 생물학과 세포 생물학(Cell Biology)
가장 기본적인 수준에서 우리는 세포 생물을 세 가지로 나누게 됩니다.
Eukaryota(진핵생물) , Archaea(고세균), Bacteria(박테리아) 인데요, 고세균과 박테리아를 하나로 묶어 Prokaryotes(원핵생물)이라고 부르기도 합니다.
이 두 생물의 아주 근본적인 그룹을 구분하자면 진핵생물은 세포핵을 가지고 있고, 원핵생물은 그렇지 않다는 것입니다.
진화론적으로 이 세 가지의 생명 영역은 아주 오래전, 지구의 생명체가 진화할 때 서로 분리되었다고 합니다.
박테리아와 고세균은 세포를 설명하는 수준에서 매우 유사하게 보입니다.
진핵생물과 원핵생물의 가장 큰 차이는 진핵생물에는 세포핵이 있고 원핵생물에는 세포핵이 없다는 것입니다.
세포핵은 아주 오래전에 DNA를 세포의 나머지 부분으로부터 분리하는 방법으로 진화했습니다.

세포 수준에서 보면 진핵 세포와 원핵세포가 다르게 보입니다. 왼쪽에는 Nucleus(세포핵)이 존재하는 것이 보이죠. 그래서 아주 흔한 효모라는 단세포 진핵생물도 핵이 있습니다.
따라서 인간과 효모 그리고 그 사이에 있는 모든 것들은 진핵생물이라고 보시면 됩니다.
우리 세포에는 핵이 있고, 다른 세포 소기관도 작은 세포 구조입니다. 원핵생물은 세포핵이 없어서 DNA가 그냥 떠다니고 있다고 생각하시면 됩니다. 실제로 떠있는 것은 아니지만 내부에 느슨하게 조직되어 있는 것으로 생각하면 됩니다. 반면 진핵생물의 DNA는 좀 더 조직적인 모습을 가지고 있습니다. 진핵 세포의 DNA는 내부 깊숙하게 격리되어 있습니다.
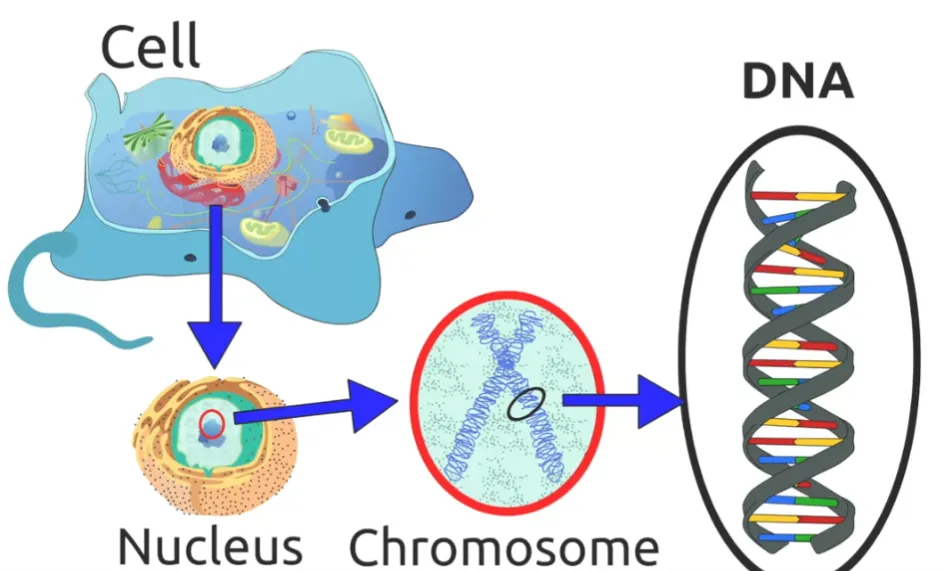
위의 사진을 보면, 벽으로 둘러싸인 진핵 세포 내부에는 자체 세포막 또는 벽이 있는 핵이 있고 그 핵 안에는 DNA를 넣는 곳입니다. 우리의 DNA는 매우 긴 DNA 분자인 염색체로 구성되어 있습니다. 그리고 모든 염색체는 각 세포 안에 있고 세포 안에는 각 세포의 핵이 있습니다.
DNA에는 예외가 있습니다. 진핵 세포 내부의 세포 소기관 중 하나를 미토콘드리아라고 부릅니다.
각 세포에는 여러 개의 미토콘드리아가 있어서 미토콘드리아는 고유의 DNA를 가지고 있습니다. 인간의 경우에는 인간 Genome에서 미토콘드리아 Genome은 매우 작습니다. 우리 DNA의 1%에 불과하죠.
하지만 미토콘드리아는 내부의 유전자가 상당한 양의 에너지 대사를 담당하기 때문에 세포의 발전소라고도 불립니다. 생명에 매우 중요한 부분이라고 할 수 있습니다.
세포는 많은 사람들이 연구하는 특징적인 세포 주기를 거칩니다.
여러 가지 복잡한 주기를 모두 외울 필요는 없습니다. 세포는 아주 잘 정의된 주기를 갖고 있는데요, 가장 중요한 것은 분열 과정입니다. 수정란의 단세포 전구 세포에서 전체 유기체로 이동하는 과정에서 세포는 여러 번 분열하고 싶어 하며 평생 세포는 끊임없이 죽어가며 교체합니다.
손상된 조직을 대체하기 위해서는 대체가 잘 되어야 합니다. 그래서 세포가 분열하여 손상된 세포를 대체하는 것이죠. 따라서 이 과정의 일부를 ‘유사 분열’이라고 합니다. 세포가 두 개의 딸세포로 분리되어 본질적으로 동일한 두 개의 세포를 생성합니다.
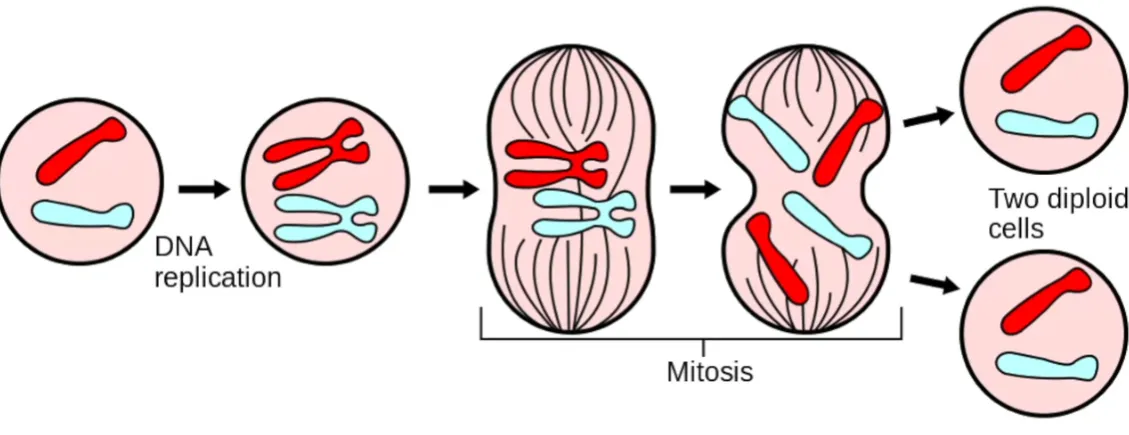
세포가 유사 분열을 겪을 때 세포의 DNA가 복제되어야 합니다. 즉 이전에 한 개가 있던 곳에 두 개의 사본을 만들어야 하는 것이죠. 분열하면서 세포 내의 서로 다른 물리적 구획으로 매우 안정적인 분리를 합니다.
그 결과 원래 세포와 동일한 두 개의 딸 세포가 생성되고 두 개의 딸 세포 모두 이배체입니다.
이배체(diploid) : 생물학 용어로, 모든 염색체가 쌍으로 존재하는 세포나 생물체를 의미합니다. 일반적인 체세포는 이배체이고, 각 염색체는 부모로부터 하나씩 물려받아 쌍을 이룹니다. 인간의 경우 23쌍 총 46개의 염색체를 가지고 있는 상태가 이배체입니다.
세포 생물학에서 또 다른 중요한 점은 모든 세포가 항상 분열하여 동일한 사본 두 개를 생성하는 것이 아니라는 점입니다. 물론 손상된 기존의 세포를 교체하는 경우가 있습니다.
예를 들어, 피부에 상처가 생겼고 새로운 피부 세포를 성장시켜야 한다면 피부 세포가 이전에 존재했던 것과 같은 형태가 되길 원할 것입니다. 하지만 발달 과정에서 세포는 다양한 유형의 세포로 발달해야 합니다.
우리 몸에는 줄기세포(Stem cell)라고 부르는 좀 더 기본적인 세포에서 출발합니다. 줄기세포는 서로 다른 유형의 세포로 분열하고 분화할 수 있는 능력을 가지고 있죠.
따라서 항상 두 개의 딸 세포가 서로 동일하지 않고 약간 다른 세포 분열 과정이 포함됩니다. 그리고 이 세포들은 우리가 ‘발달 경로’라고 부르는 과정을 통해 서로 다른 유형의 성숙한 세포로 분화할 수 있게 해 줍니다.
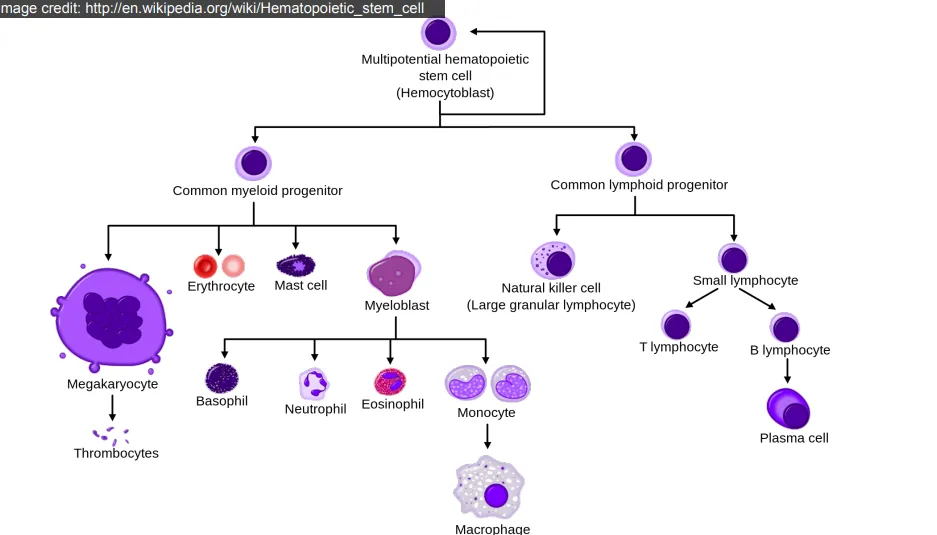
아래의 그림에서 Multipotential hematopoietic stem cell (HSC, 다능성 조혈모세포)라고 부르는 세포로부터 시작을 합니다. 이 세포는 다양한 유형의 혈액 세포를 분열시키고 생산할 수 있습니다. 이 세포들은 주로 골수에서 발견됩니다.
HSC는 적혈구, 백혈구, 혈소판 등 여러 종류의 혈액 세포로 분화할 수 있습니다. 그리고 스스로를 복제하여 새로운 HSC를 생성할 수 있는 능력이 있습니다. 이는 혈액 세포의 지속적인 생산을 보장하죠. 그리고 조혈(혈액 생성) 과정의 시작점으로, 신체의 필요에 따라 다양한 혈액 세포를 생성합니다.
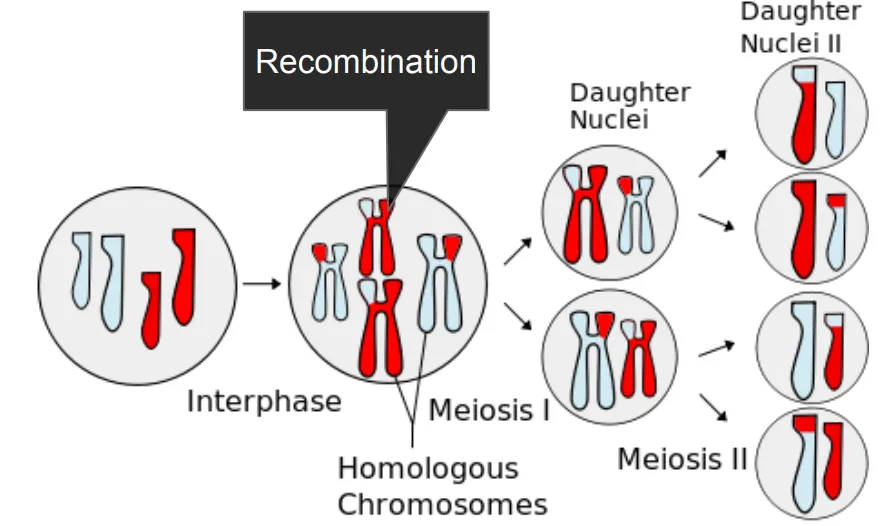
다음 세대의 종(species)을 위한 난자 세포나 정자 세포를 생산할 때는 먼저 어머니와 아버지의 염색체 사본으로 시작해서 감수분열 전에 하나의 구획으로 합쳐집니다. 그런 다음 특별한 과정이 있는데요.
이 과정은 의도적으로 생긴 것이 아니라 재조합(Recombination)이라고 하는 것입니다. 재조합(Recombination)은 유전적 다양성을 증가시키는 중요한 생물학적 과정으로, 주로 생식 세포의 형성과정에서 발생합니다.
재조합은 부모의 염색체가 서로 교차하여 새로운 조합의 유전자를 생성하게 됩니다. 이 과정에서 염색체의 일부가 서로 교환됩니다. 또한, 자손이 부모와는 다른 유전적 조합을 가지게 하여, 생물의 다양성을 증가시킵니다. 이는 진화와 적응에 중요한 역할을 하게 되는 것이죠.
재조합은 주로 감수분열(Meiosis) 과정에서 발생합니다. 이 과정에서 생식 세포(정자와 난자)가 형성되며, 각 세포는 부모의 유전자를 반반씩 물려받습니다. 따라서 재조합은 유전자 변형의 한 형태로 볼 수 있고, 특정 유전자가 새로운 조합으로 나타날 수 있습니다. 이는 유전적 질병의 발생 가능성을 줄이거나 새로운 특성을 부여할 수 있습니다.
분자 생물학에서 중요한 분자(Important molecules in molecular biology)
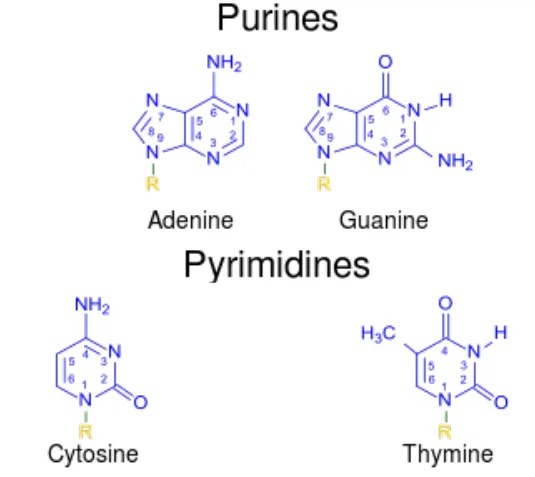
DNA는 모든 유전 물질을 구성하며 아데닌(A), 구아닌(G), 사이토신(C), 티민(T)이라는 네 가지 뉴클레오타이드로 이루어져 있습니다. 아데닌(A)과 구아닌(G)은 퓨린(Purines)이라고 불리는데 여기에 표시된 것처럼 두 개의 고리 구조를 가지고 있습니다. 그리고 티민(T)과 시토신(C)은 피리미딘(Pyrimidines)이고 하나의 고리 구조를 가지고 있습니다. 이 구조를 알거나 기억할 필요는 없지만 C와 T가 비슷하고 A와 G가 서로 비슷한 것 정도만 알고 계시면 될 것 같습니다.
DNA가 구성되는 방식은 이 분자들이 매우 특정한 방식으로 결합한다는 것입니다. A는 항상 T에 결합하고 G는 항상 C에 결합합니다.
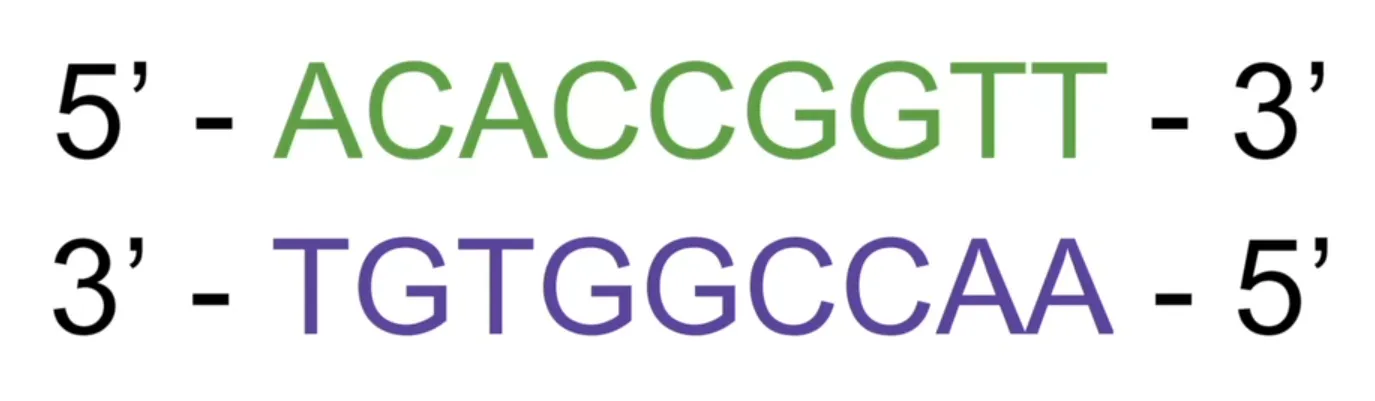
우리가 데이터를 쓰는 방식을 보면 DNA 염기서열 자체는 이러한 화학 구조를 쓰지 않습니다.
DNA에는 사실 방향이 존재합니다. 가닥이라는 것이 있죠.
생화학적 특성에 따라 DNA의 한쪽 끝을 파이프라인 말단이라고 무르고 다른 쪽 끝을 A3 프라임 말단이라고 부릅니다. 이것은 생화학 분자의 구조와 관련이 있지만 굳이 기억할 필요는 없습니다.
또 다른 중요한 분자는 우리 몸이 작동하는 방식과 Genome이 작동하는 방식을 결정하는 중요한 분자입니다.
따라서 RNA는 몇 가지 중요한 차이점을 제외하면 DNA와 거의 흡사합니다. 분명한 차이점은 티민(T) 대신 우라실(U)을 가지고 있다는 점이죠. 따라서 DNA가 복제되거나 RNA로 전사되면 A는 A로 , G는 G로 , C는 C로, T는 U로 대체됩니다. 그러면 DNA와 달리 단일 가닥인 RNA를 생성할 수 있습니다.
따라서 RNA는 이중 가닥 복합체를 형성할 수는 있지만 이중 가닥은 아닌 것이죠. 하지만 일반적으로 RNA는 단일 가닥으로 이루어져 있으며 이 RNA 주형에서 단백질을 생성합니다.
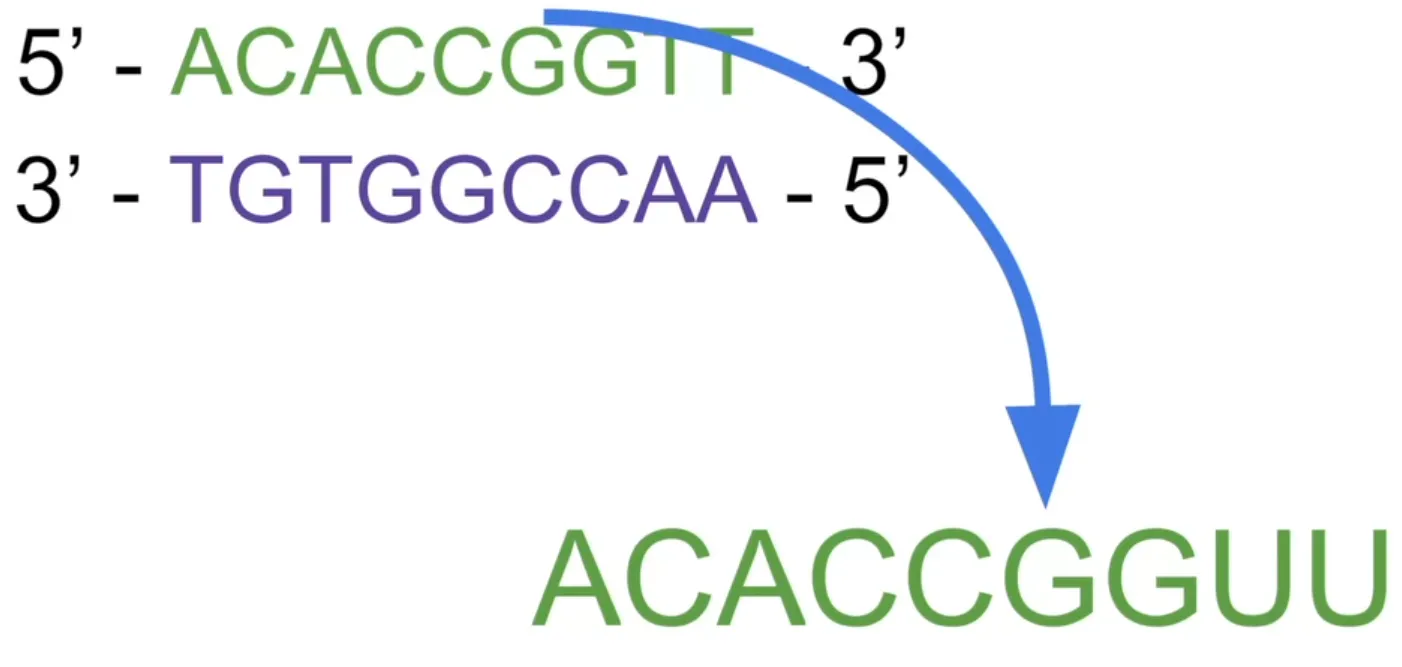
RNA는 똑같은 생화학 구조를 가지고 있습니다. 우라실(U) 분자는 티민(T) 분자와 매우 유사합니다.
유전학적으로 중요한 차이점은 DNA는 유전이라는 것입니다. DNA는 세포가 분열할 때마다 세포들이 한 세대에서 다음 세대로 옮기는 물질입니다. 세포는 원래 세포의 DNA를 복제하는 DNA를 생성합니다.
RNA는 주형을 사용하여 단백질을 만들지만 RNA는 실제로 유전되는 물질이 아닙니다.
우리는 이 분자들을 사용해서 세포가 어떻게 작동하는지 암호화합니다.
DNA는 기본적으로 우리가 알아내는 프로그램입니다. 그리고 리드아웃 프로그램은 RNA로 시작해서 만들어지는데, RNA는 단백질을 만드는 데 사용됩니다. 단백질도 긴 분자이지만 DNA만큼 길지는 않습니다.
아미노산의 길이는 보통 수백, 때로는 수천 개입니다. 그래서 아미노산은 좀 더 복잡한 분자입니다.
아래의 사진에 보이는 아미노산은 서로 연결되어 단백질을 만드는 분자이기도 합니다.
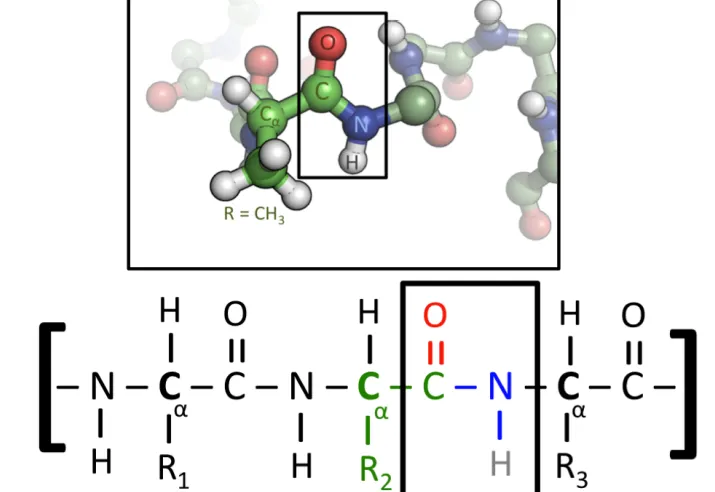
RNA가 단백질로 전환되는 방법은 RNA의 세 글자의 모든 조합이 RNA를 아미노산으로 암호화하는 것입니다.
따라서 이러한 조합은 64가지나 될 수 있습니다. 64개 중 61개는 아미노산을 암호화하고 그중 3개는 정지 코돈입니다. 따라서 번역 기계는 RNA 분자를 따라서 한 번에 세 개의 뉴클레오티드를 읽습니다.
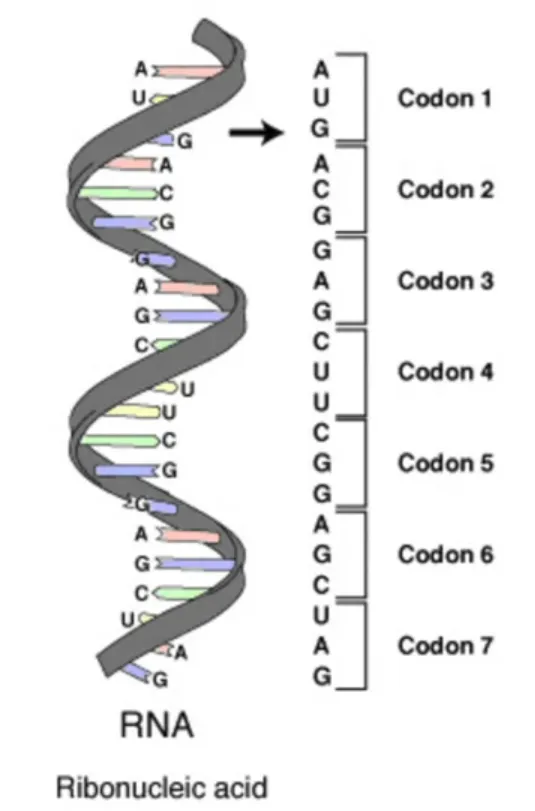
그리고 3개의 뉴클레오티드마다 아미노산이 생성됩니다. 그리고 이 둘은 하나로 합쳐져서 우리가 단백질이라고 부르는 긴 아미노산을 형성합니다. 번역 기계가 정지 코돈 중 하나에 부딪히면 멈추게 됩니다.
아래의 이미지는 3개의 아미노산을 생성하는 9개의 뉴클레오티드로 이루어진 특정한 세트의 번역을 보여주고 있습니다. 우리는 아미노산의 약칭을 위해 사용하는 20자의 알파벳으로 단백질을 씁니다.
인간의 모든 단백질을 구성하는 아미노산은 총 20개입니다. 실제로는 22개인데, 21번째 아미노산이 발견된 것은 그리 오래되지 않았습니다. 22번째도 마찬가지입니다. 이 아미노산들은 주로 인간 이외의 다른 생명체에도 사용됩니다. 일반적으로 인간에 해당하는 생물학에 대해 생각해 보면 64개의 가능한 코돈이 있다고 볼 수 있습니다. 그중 61개는 아미노산을 암호화하고 정확히 20개의 아미노산을 암호화합니다.
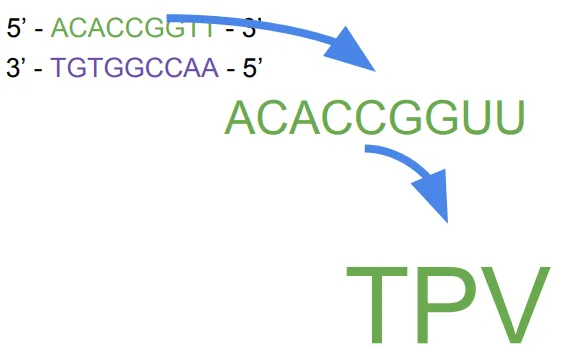
분자 생물학 구조 - Molecular biology structures
이 섹션에서는 대부분 용어와 기능에 대한 설명입니다.
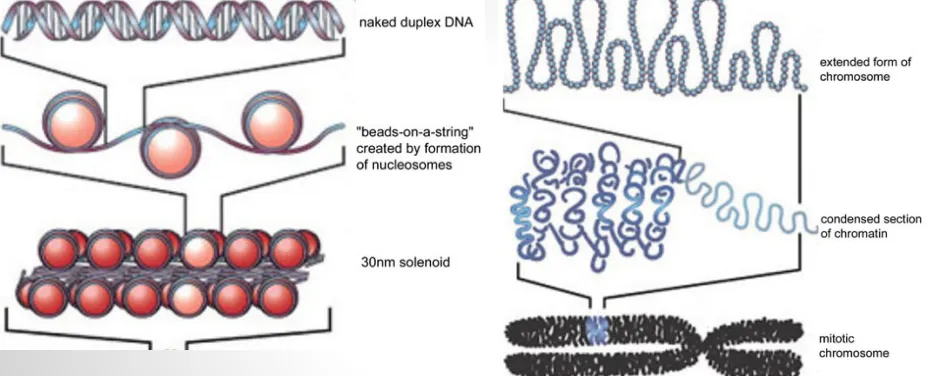
우선 앞서 계속 언급했던 DNA에 대해서 알아보겠습니다. DNA 자체는 매우 긴 분자입니다.
따라서 DNA를 펼쳐보면 각 세포 내부는 길이가 약 2m에 달합니다. 물론 세포는 매우 미세한 크기입니다.
세포 안에 들어갈 수 있으려면 아주 효율적인 방식으로 세포를 감싸야합니다.
이것은 실제로 히스톤이라고 불리는 다른 분자들을 감싸고 있습니다. 아래의 그림에서 왼쪽에 있는 끈에 달린 구슬처럼 말이죠. 그리고 그 히스톤들은 약간 더 긴 조직화된 구조들에 싸여 있습니다.
히스톤 : DNA가 세포 내에서 효율적으로 포장되고 조직될 수 있도록 돕는 단백질의 종류.
이것들이 서로 감겨서 슈퍼 코일링 되어 더 큰 구조로 되어 결국에는 오른쪽에 보이는 염색체를 형성하보니다.
DNA는 자기 주위를 감고 있으며 아주 복잡한 방식으로 자기 주위를 감습니다. 이제 DNA가 전사되고 번역되는 과정을 거치려면 DNA의 포장을 약간 풀어야 합니
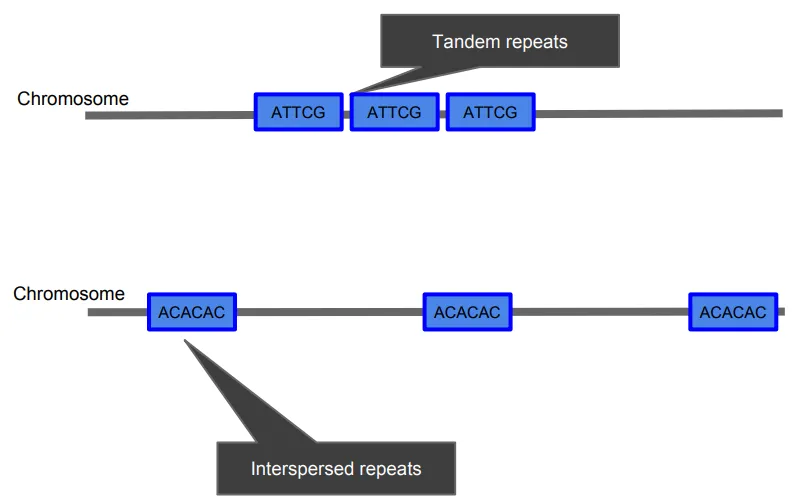
다른 종류의 구조는 물리적인 구조가 아니라 서열 구조라고 하고 이걸 반복(Repeats)이라고 부릅니다. 데이터 분석에서 반복에 대해 많이 듣게 될 것입니다. 반복은 두 가지 유형으로 분류할 수 있습니다.
직렬 반복(Tandem repeats)은 연속해서 일어나는 동일한 수열의 반복입니다. 아래의 그림에서는 ‘ATTCG’가 세 번 반복되고 있는 중이죠? 이는 수백 개의 염기쌍 길이의 염기서열이 수천 번 연속적으로 나타나는 경우가 있습니다. 각 염색체 중심체는 180개 염기쌍의 반복으로 이루어져 있는데, 연속적으로 수십만 번 반복됩니다.
따라서 반복은 매우 길고 복잡해질 수 있습니다.
수많은 반복 시퀀스는 여기저기 흩어져 있어서 다른 유형의 분석에 문제를 일으키기도 하고 때로는 문제를 일으킬 수도 있습니다. 염기서열이 매우 짧으면 DNA 염기서열을 읽을 때 한 번에 수백 개의 염기쌍만 읽는다는 것을 기억해야 합니다.
RNA구조에서 녹색으로 표시된 염기서열이 있는데 이것을 코딩 서열(Coding sequence, CDS)이라고 합니다. 이는 실제로 단백질로 번역이 되는 부분이고 아미노산 서열을 결정하는 정보를 포함하고 있습니다. 3개의 염기가 하나의 아미노산을 지정합니다. 하지만 중요한 점은 DNA에서 전사된 RNA 부분이 이 코딩 서열보다 더 길다는 것입니다. mRNA의 시작 부분에는 번역되지 않는 부분이 있는데, 이를 UTR(비번역 영역)이라고 부릅니다. RNA의 시작점이 5' 말단이기 때문에 이를 5' UTR이라고 합니다. 반대쪽 끝에는 3' UTR이 있으며, 이는 보통 더 긴 길이를 가집니다. 이 역시 단백질로 번역되지 않습니다.
인간 세포를 포함한 진핵 세포의 또 다른 중요한 특징은 폴리 A 꼬리(Poly-A tail)가 추가된다는 것입니다. DNA가 RNA로 전사되고 인트론이 제거된 후, RNA 말단에 일련의 아데닌(A) 염기들이 추가됩니다. 이 폴리A 꼬리는 실험적으로 RNA를 세포 밖으로 추출할 때 활용할 수 있는 일종의 '갈고리' 역할을 합니다.
실제로 DNA에서 RNA로 전사되는 과정은 이보다 더 복잡합니다. 전사되는 DNA에는 인트론도 포함되어 있으며, 이는 나중에 제거됩니다. 최종적으로 단백질을 암호화하는 부분을 찾으려면, UTR을 식별하여 제거하고 남은 코딩 서열을 읽어야 합니다. 이를 통해 아미노산 서열로 직접 번역할 수 있게 됩니다.

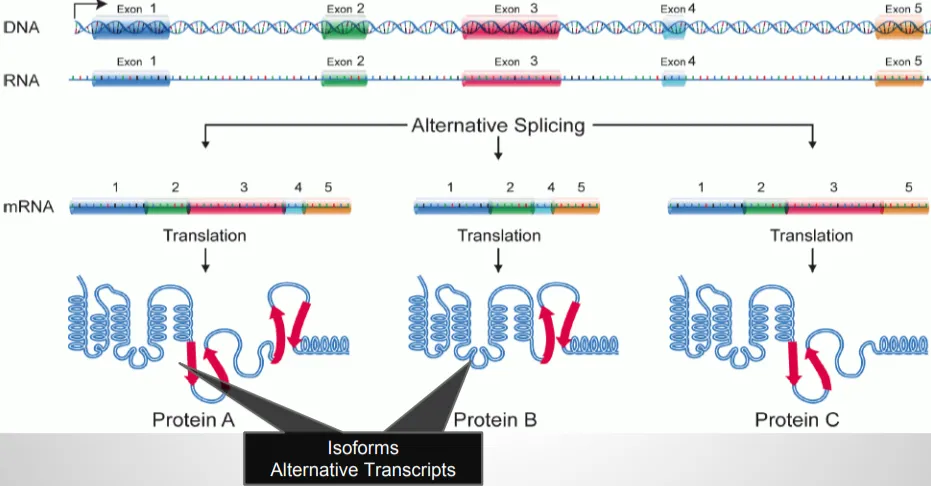
DNA는 RNA로 전사되는데, 이 과정은 생각보다 복잡합니다. 실제로 전사되는 DNA 부분은 최종 RNA 산물보다 훨씬 깁니다. DNA가 RNA로 전사될 때는 엑손과 인트론을 모두 포함합니다. 이미지에 나타난 것과 같이 한 유전자는 서로 다른 색으로 표시된 5개의 엑손을 가질 수 있으며, 이 엑손들 사이에는 인트론이라 부르는 염기서열이 존재합니다.
전사 후에는 중요한 과정이 일어나는데, 인트론이 제거되고 엑손들이 서로 연결됩니다. 제거된 인트론은 세포에서 버려지거나 재활용됩니다. 남은 엑손들이 실제로 단백질로 번역되는 부분입니다. 이전에 설명했던 코딩 서열은 사실 이렇게 서로 연결된 엑손들의 순서였던 것입니다.
이 구조의 중요한 특징은 세포가 엑손들을 다양한 방식으로 조합할 수 있다는 것입니다. 인트론을 제거하고 엑손을 연결하는 과정에서, 엑손들을 서로 다른 조합으로 연결할 수 있는데, 이를 '대체 스플라이싱'이라고 합니다. 이는 매우 흔한 현상으로, 처음 발견됐을 때는 특이하고 드문 현상으로 여겨졌지만 현재는 인간 유전자의 90% 이상이 어떤 형태로든 대체 스플라이싱을 겪는다는 것이 밝혀졌습니다.
이는 매우 중요한 의미를 갖는데, DNA의 전체 서열을 알고 어떤 부분이 RNA로 전사되는지 안다고 해도, 정확히 어떤 단백질이 만들어질 수 있는지 알아내기 위해서는 더 많은 연구가 필요하다는 뜻입니다. 같은 유전자에서 서로 다른 조합의 엑손으로 다른 성숙한 메신저 RNA가 만들어질 수 있고, 이는 결과적으로 서로 다른 단백질을 만들어낼 수 있기 때문입니다.
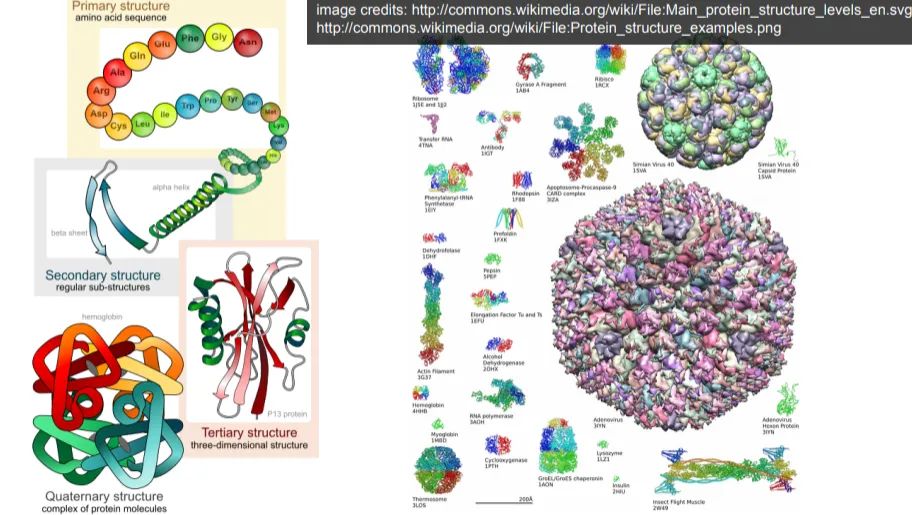
단백질은 매우 복잡한 구조를 형성하는데, 여기에는 중요한 2차 구조가 포함됩니다. 단백질의 가장 대표적인 두 가지 2차 구조는 베타 시트(beta sheet)와 알파 나선(alpha helices)입니다. 아미노산들은 평평한 구조인 베타 시트를 형성하거나, 꼬여서 나선형 구조인 알파 나선을 형성할 수 있습니다.
현재까지 수천 개의 단백질 구조가 해결되었습니다. 생물물리학자들이 이러한 단백질들의 성숙한 구조를 밝혀냈는데, 이는 매우 중요한 의미를 가집니다. 왜냐하면 단백질의 구조에 따라 그 기능이 달라지기 때문입니다. 이것이 바로 우리가 단백질 구조를 연구하는 이유입니다.
단백질의 기능을 이해하기 위해서는 단백질의 어느 부분이 구조 내부에 묻혀 있고, 어떤 부분이 바깥쪽에 있는지를 아는 것이 중요합니다. 바깥쪽에 노출된 부분이 아마도 단백질의 활성이 더 높은 부분일 것입니다. 이러한 구조적 이해는 단백질의 기능을 파악하고 예측하는 데 핵심적인 역할을 합니다.
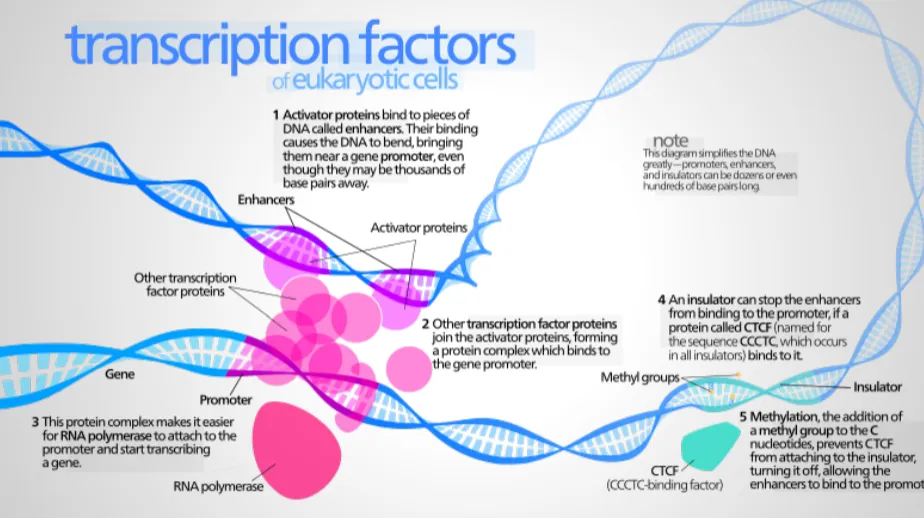
우리 몸의 모든 세포는 동일한 유전자를 가지고 있지만, 세포마다 다르게 행동합니다. 예를 들어, 피부 세포는 혈액 세포와 매우 다르게 행동하는데, 이는 서로 다른 유전자가 활성화되어 있기 때문입니다. 이러한 세포 활동을 조절하는 중요한 방법 중 하나가 전사 인자입니다. 전사 인자(transcription factors)는 게놈에 의해 암호화되는 단백질입니다.
DNA에 돌아가서 DNA 자체나 염색체에 결합하여 단백질의 발현을 조절할 수 있습니다. 이 전사 인자들은 보통 다른 유전자의 상류 부분에 결합하여, 그 유전자의 생산을 가속화하거나 억제할 수 있습니다. 이는 세포가 얼마나 많은 단백질을 생산할지 결정하는 매우 중요한 조절 메커니즘입니다.
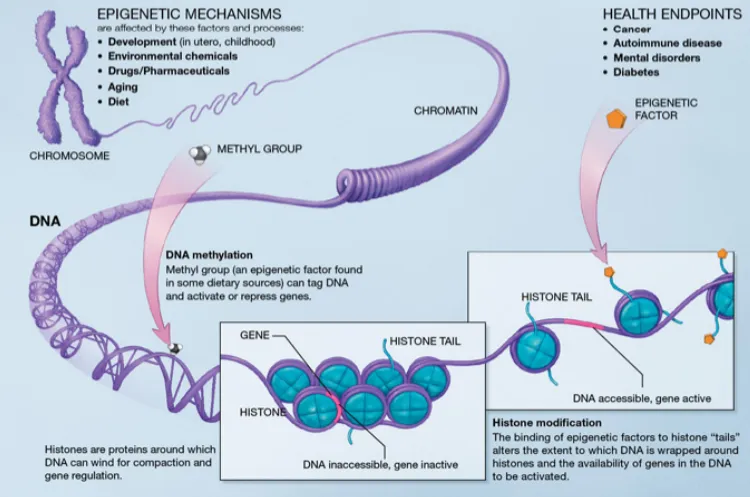
또한, 후생적(후생유전학적) 메커니즘도 중요한 역할을 합니다. 후생유전학은 'genetics를 넘어선 것'을 의미하며, DNA 자체 외부에 있는 요인들을 말합니다. 이러한 요인들은 직접적으로 유전되지는 않지만, 세포의 기능과 유전자 발현 방식을 통제하는 역할을 합니다.
가장 중요한 후생유전학적 구조 중 하나는 메틸기(메틸 그룹)입니다. DNA가 메틸화되면 이 메틸화는 세포 주기를 통해 딸세포로 전달될 수 있습니다. 이러한 메틸화 흔적은 유전자의 양이나 발현 시기에 영향을 미치는 조절 요인이 됩니다.
중요한 점은 메틸화는 세포 간에는 유전되지만, 새로운 개체가 생성될 때는 유전되지 않는다는 것입니다. 즉, 세포가 분열하여 같은 유형의 새로운 세포를 생성할 때만 유전됩니다. 이러한 후생유전학적 메커니즘은 세포의 기능을 이해하는 데 매우 중요한 또 다른 유형의 구조입니다.
유전자에서 표현형까지 - From genotype to phenotype
유전자형( genotype)은 세포 안에 있는 모든 유전자의 서열을 총망라한 것을 의미합니다. 다시 말해, 유전자의 모든 돌연변이를 포함하는 개념으로 볼 수 있습니다. 이러한 유전자형은 신체가 어떻게 기능하는지, 세포가 어떻게 작동하는지를 결정하며, 특정 특성이나 질병의 유무도 결정합니다.
반면 표현형(phenotype)은 이러한 유전자형을 제외한 나머지 모든 것을 의미합니다. 구체적으로는 우리가 관찰할 수 있는 모든 특성들을 말합니다. 예를 들어 머리 색깔, 눈 색깔, 키, 몸무게와 같은 신체적 특징뿐만 아니라 유전병이나 건강 상태, 심지어 성격의 여러 측면까지도 포함됩니다. 유전체학 연구에서는 이러한 유전자형이 표현형과 어떻게 연관되어 있는지를 이해하는 것이 중요한 목표이며 이를 위해 다양한 종류의 실험이 수행되고 있습니다.
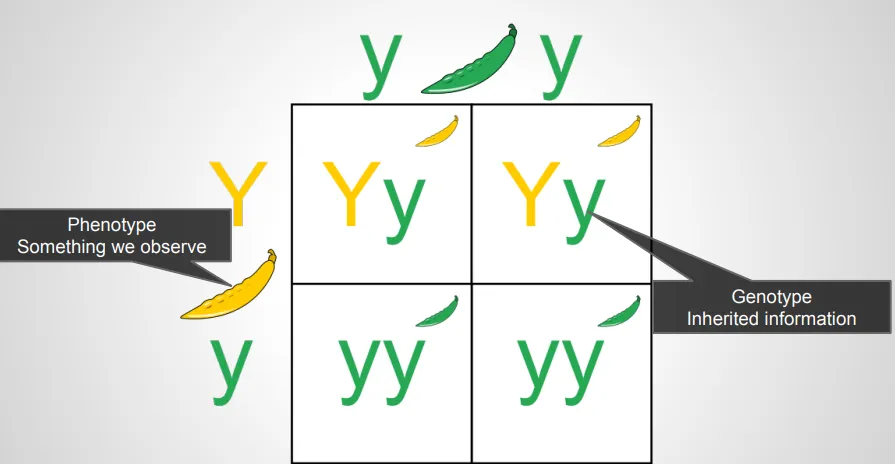
멘델의 완두콩 실험은 유전자형과 표현형의 관계를 이해하는 좋은 예시를 제공합니다. 완두콩은 사람이나 동물처럼 이배체로, 모든 염색체에 두 개의 사본이 있어 모든 유전자에 대해 두 개의 사본을 가집니다.
이 실험에서 녹색 완두콩은 녹색 유전자를 두 개(yy) 가지고 있고, 노란 완두콩은 녹색 유전자 사본 하나와 노란색 유전자 사본 하나(Yy)를 가집니다. 여기서 대문자 Y는 우성 형질을, 소문자 y는 열성 형질을 나타냅니다. 열성 형질은 그 형질의 유전자 사본이 두 개 있어야만 표현되는 반면, 우성 형질은 유전자 중 하나에만 그 형질이 있어도 표현됩니다.
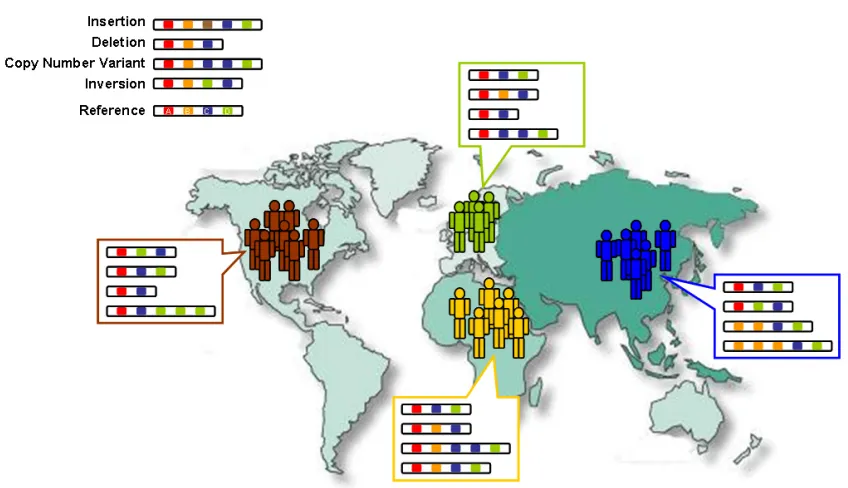
지난 10년간 전체 유전체 염기서열 분석이 크게 확대되면서, 과학계는 전 세계 수천 개의 개별 게놈 염기서열을 분석해 왔습니다. 이를 통해 세계 각지의 유전적 변이를 파악할 수 있게 되었습니다. 연구 결과 세계 각 지역의 사람들이 그 지역에 특징적인 돌연변이를 가지고 있다는 것이 밝혀졌습니다. 이러한 돌연변이는 단순한 염기 다형성(SNP) 일 수도 있고, DNA에 더 큰 덩어리를 삽입하거나 삭제하는 것과 같은 더 큰 변화일 수도 있습니다.
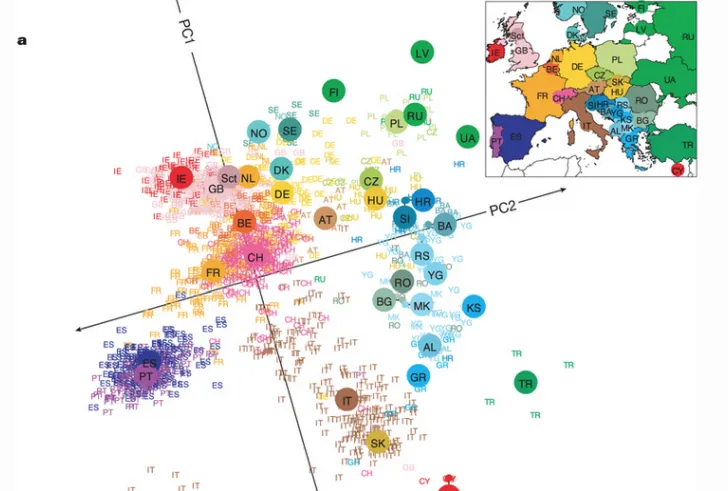
유럽 전역의 사람들을 대상으로 한 유전체 연구는 유전적 특성이 지역화되는 경향을 잘 보여줍니다. 주성분 분석이라는 통계적 방법을 사용하여 수백만 개의 염기서열 정보를 두 차원으로 축소해 분석한 결과, 같은 지역에 사는 사람들은 유전적으로 비슷한 특성을 공유하는 것으로 나타났습니다. 이는 같은 지역의 사람들이 결혼하고 자녀를 낳는 경향이 있기 때문에 나타나는 자연스러운 현상입니다.
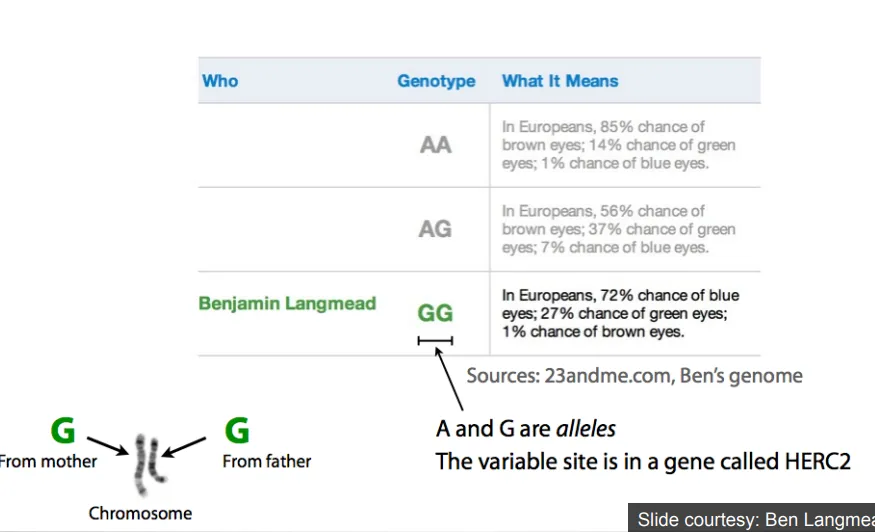
일반적인 유전자형은 AA, AG, GG 이렇게 두 개씩 됩니다. 유럽인의 경우 A가 두 개이면 갈색 눈을 가질 확률은 85%이고, 녹색 눈을 가질 확률은 14%, 파란 눈을 가질 확률은 1%입니다.
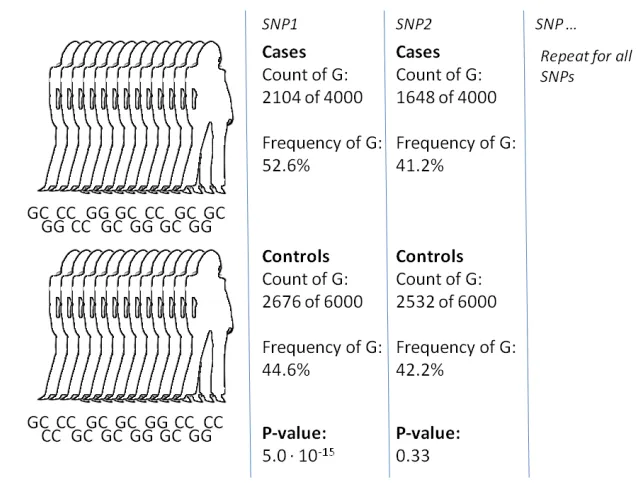
현대의 유전자형과 표현형 사이의 연관성 연구는 매우 효율적으로 이루어지고 있습니다.
특정 특징이나 질병을 가진 많은 사람들의 전체 게놈 염기서열을 분석하여 특정 유전자의 돌연변이를 찾아냅니다. 이러한 게놈 전반의 연관성 연구를 통해 특정 SNP나 유전적 변이와 질병이나 특성 사이의 관계를 밝혀낼 수 있습니다.
하지만 중요한 점은 이러한 연관성이 완벽한 인과관계를 의미하지는 않는다는 것입니다. 특정 유전적 변이가 있다고 해서 반드시 특정 질병이나 특성이 나타나는 것은 아니며, 단지 그러한 가능성이 상대적으로 높아진다는 것을 의미합니다.