

1. Interesting Point
"We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token.”
저자들은 기존의 SSM 모델들의 주요한 약점 이 내용 기반 추론(content_based reasoing)을 수행하지 못한다는 것을 발견하고 몇 가지 개선점을 제시합니다. 우선, SSM parameters를 단순히 입력의 함수로 만들어 이산화하여 약점을 해결하고, 현재 토큰에 의존하여 시퀀스 길이 차원을 따라 정보를 선택적으로 전파하거나 잊을 수 있도록 합니다.
We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences.
이러한 선택적 SSM을 어텐션이나 심지어 MLP 블록조차 없는 단순화된 end-to-end 신경망 아키텍쳐(Mamba)에 통합합니다. Mamba는 빠른 추론(Transformer 보다 5배 높은 처리량)과 시퀀스 길이에 대한 선형 스케일링을 제공하며 실제 데이터에서 최대 백만 길이 시퀀스까지 성능이 향상됩니다.
However, this property brings fundamental drawbacks: an inability to model anything outside of a finite window, and quadratic scaling with respect to the window length. An enormous body of research has appeared on more efficient variants of attention to overcome these drawbacks (Tay, Dehghani, Bahri, et al. 2022), but often at the expense of the very properties that makes it effective.
self-attention은 유한한 윈도우 밖의 것들은 모델링할 수 없고 윈도우 길이에 대해 제곱으로 스케일링 됩니다. 이러한 단점을 극복하기 위해 어텐션의 더 효율적인 변형들에 대한 연구가 많이 진행되었습니다.
However, they have been less effective at modeling discrete and information-dense data such as text.
구조화된 상태 공간 시퀀스 모델(SSMs)이 시퀀스 모델링을 위한 유망한 아키텍처 클래스로 부상했고, 이 모델들은 RNN과 CNN의 조합으로 해석될 수 있습니다. 그러나 텍스트와 같은 이산적이고 정보 밀도가 높은 데이터를 모델링하는 데는 덜 효과적입니다.
Mamba Motivation Summary
우선 트랜스포머의 모델부터 텍스트 생성 모델까지 간단하게 살펴보겠습니다. Transformer 모델의 주요 장점은 입력값이 무엇이든, 시퀀스의 이전 토큰을 참고할 수 있어서 그 표현을 도출할 수 있다는 점이죠 ?
모델의 구성을 보면 텍스트를 받아서 Encoder에 들어가고 그 후에 Decoder 블록을 통과하게 되어있습니다. 이 구조를 사용하여 GPT 모델처럼 디코더만을 사용하는 생성 모델을 만들 수 있습니다.

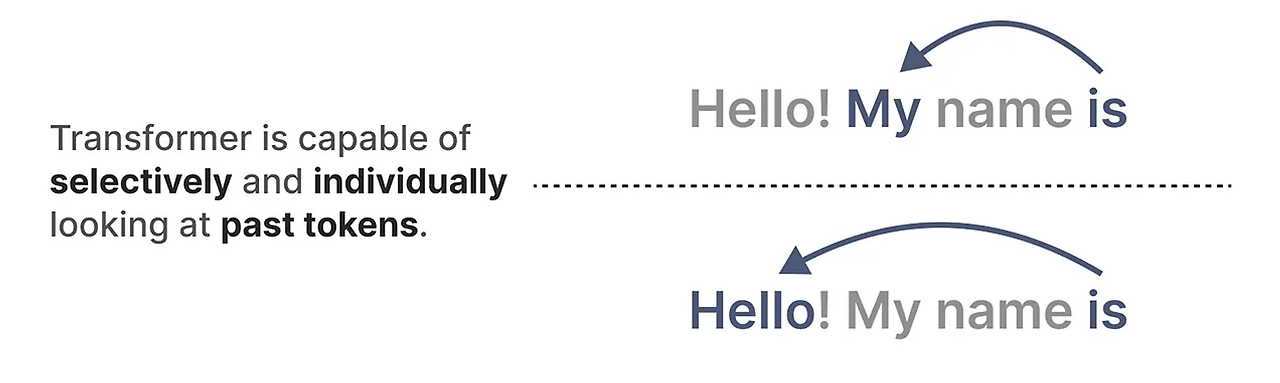
우리가 잘 알고있는 트랜스포머 기반 모델인 GPT(Genrative Pre-Trained Transformer, GPT)는 디코더 블록을 사용하여 어떤 입력 텍스트를 완성하게 되는 것입니다.

하나의 Decoder 블록에는 masked self-attention과 피드포워드 신경망으로 구성되어 있습니다.
self-attention은 이 모델들이 작동하는 주요 이유 중 하나라고 배웠습니다. 전체 시퀀스에 대한 압축되지 않은 관점을 제공하여 훈련 속도를 빠르게 해주죠. 각 토큰은 이전의 토큰과 비교하여 행렬을 생성하게 됩니다. 행렬의 각 가중치는 토큰 쌍이 서로 얼마나 관련이 있는지에 의해 결정됩니다. 이는 병렬 처리를 가능하게 하여 훈련 속도를 크게 높일 수 있는 것이죠.

하지만 다음 토큰을 생성할 때, 이미 일부 토큰을 생성했더라도 전체 시퀀스에 대한 Attention을 다시 계산해야하죠.
길이가 L인 시퀀스에 대한 토큰을 생성하는 데는 대략 L 제곱만큼의 계산이 필요하며, 시퀀스의 길이가 증가하면 비용이 증가합니다.
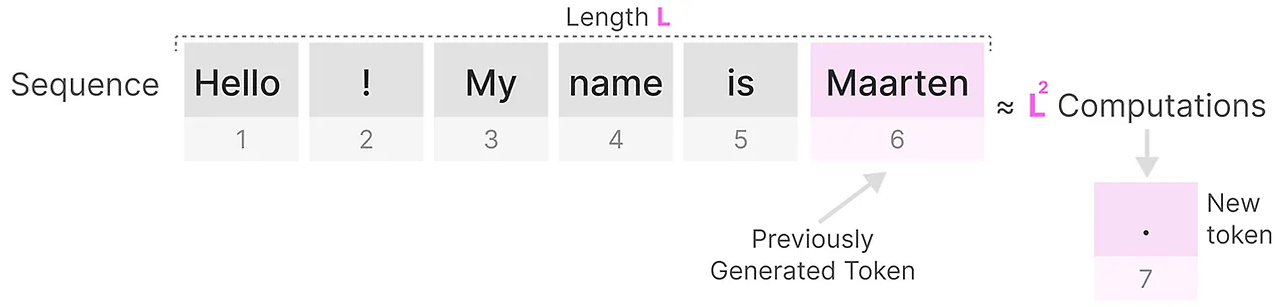
상태 공간 모델 ( State Space Models, SSM )
상태 공간 모델(State Space Models, SSM)은 트랜스포머와 RNN과 마찬가지로 정보의 시퀀스를 처리합니다.
본 논문에서 제시하는 Mamba 모델의 뼈대를 이루고 있는 아키텍처라고 볼 수 있습니다.
SSM은 흔히 제어이론에서 사용되고 있는 상태 공간 방정식과 동일합니다. 이는 연속형 변수를 가정해서 사용하는 방정식인데, 딥러닝의 경우 변수가 전부 이산형 변수이기 때문에 이산화 과정을 거쳐야 합니다.
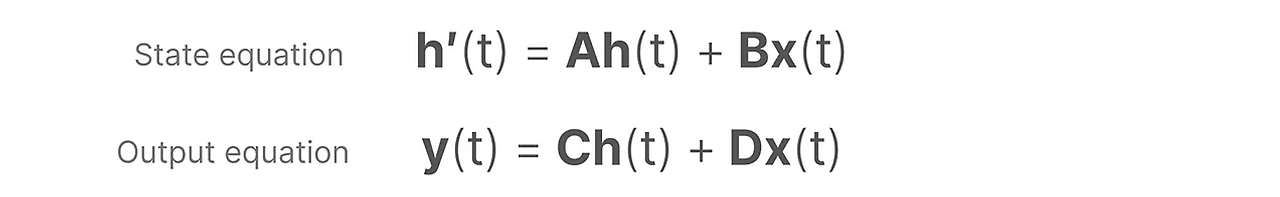
이산화 방식은 다양하지만 Mamba의 경우 ZOH 방식을 채택합니다.
Discrete time state space model 의 수식을 보면 t가 커질수록 B와 C는 고정된 상태에서 A만 계속해서 곱해지는 경향이 발생합니다.
그렇기에 이를 커널로 정의하여 컨볼루션 형식으로 작성합니다.


상태 공간 방정식을 쭉 풀어서 전개해보면 Training 단계에서는 그렇게 좋지 않습니다. 왜냐하면 Training시 이미 입력과 출력의 모든 토큰을 가지고 있기 때문에, 병렬화해야 합니다. SSM 모델은 합성곱(Convolutional) 모드도 제공하므로 이를 통해 학습 단계에서의 계산을 효율적으로 병렬화가 가능합니다.

컨볼루션 표현을 위한 수식 전개입니다. CNN이 동작하는 방식은 고정된 길이의 Kernel을 이동하여 이미지의 특징을 추출하죠 ?
이번에는 이미지가 아닌 텍스트를 다루고 있기 때문에 1차원 관점이 필요합니다.

여기서 kernel 즉, 필터를 나타내기 위해 사용하는 커널은 SSM 공식에서 도출할 수 있습니다.
위의 그림에서 kernel ( 핑크색 )이 각 토큰 세트를 통과하고 출력을 계산할 수 있습니다.


행렬 A
행렬 $\bar{A}$의 중요한 이유는 크게 세 가지가 있습니다.

우선 이전 상태의 정보를 포착할 수 있습니다. 행렬 A는 이전 상태의 정보를 새로운 상태로 전달합니다.
또한 행렬 A는 정보가 시간이 지남에 따라 어떻게 전달되는지 결정합니다. 이는 모델이 시간에 따른 입력 정보의 변화를 적절히 반영할 수 있도록 합니다. 그리고 언어 모델에서 다음 토큰은 이전 토큰(프롬프트)에 의존합니다. 행렬 A가 이전 입력의 기록을 잘 포착해야 모델이 적절한 다음 출력을 생성할 수 있습니다.
행렬 A를 생성하는 것은 따라서 몇 개의 이전 토큰만 기억하는 것과 지금까지 본 모든 토큰을 포착하는 것 사이의 차이를 만들 수 있습니다. 특히 재귀적 표현의 맥락에서는 이전 상태만을 고려하기 때문입니다.
그렇다면 우리는 어떻게 큰 메모리(맥락 크기)를 유지하는 방식으로 행렬 A를 생성할 수 있을까요?
우리는 헝그리 헝그리 히포(Hungry Hungry Hippo) 또는 HiPPO(High-order Polynomial Projection Operators)$^3$를 사용합니다. HiPPO는 지금까지 본 모든 입력 신호를 계수의 벡터로 압축하려고 시도합니다.
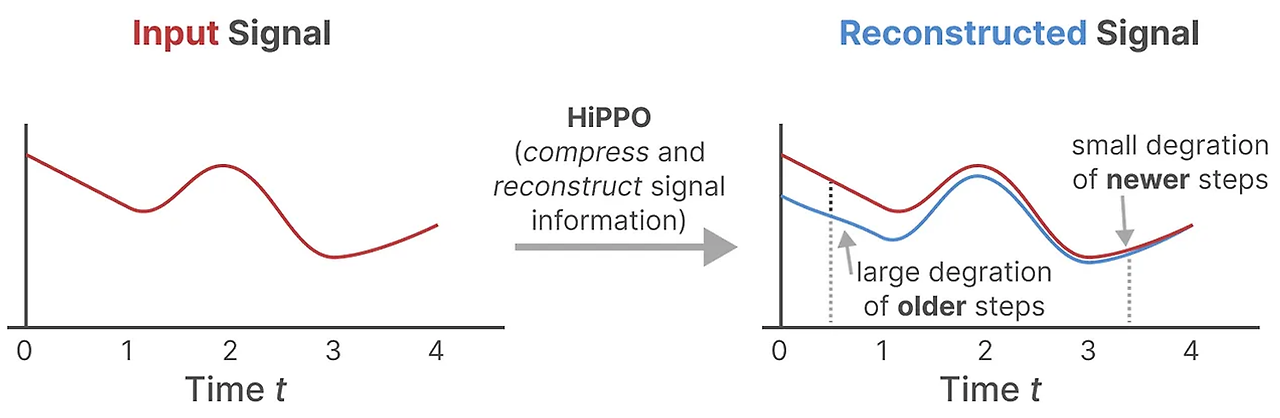
이는 행렬 A를 사용하여 최근 토큰을 잘 포착하고 오래된 토큰을 감소시키는 상태 표현을 구축합니다. 그 공식은 다음과 같이 표현될 수 있습니다:

정사각형 행렬 A를 가정하면, 우리는 다음을 얻습니다.
Hippo Matrix로 행렬을 초기화하면 A행렬은 지금까지 본 모든 입력 신호를 계수 벡터로 근사하는 방식으로 구축합니다.(Legendre)
생성된 하삼각행렬의 각 행은 Legendre 다항식 차수에 해당합니다.
Hippo Matrix로 초기화된 행렬 A는 입력 값의 시간적 특성을 효과적으로 포착하고 SSM의 성능을 향상시킵니다.

Hippo Theory

HiPPO를 사용하여 행렬 A를 구축하는 것은 무작위 행렬로 초기화하는 것보다 훨씬 나은 것으로 나타났습니다. 결과적으로, 이는 오래된 신호(초기 토큰)보다 새로운 신호(최근 토큰)를 더 정확하게 재구성합니다. HiPPO 매트릭스의 아이디어는 그것이 그 역사를 기억하는 숨겨진 상태를 생성한다는 것입니다. 수학적으로, 이는 르장드르 다항식의 계수(Legendre polynomial)를 추적함으로써 이전 역사의 모든 것을 근사화할 수 있게 함으로써 그렇게 합니다.
HiPPO는 장거리 의존성을 처리하기 위해 앞서 본 재귀적 및 컨볼루셔널 표현에 적용되었습니다. 결과는 시퀀스를 효율적으로 처리할 수 있는 SSM 클래스인 Structured State Space for Sequences (S4)였습니다.$^5$
이는 세 부분으로 구성됩니다:
- 상태 공간 모델
- 장거리 의존성을 처리하기 위한 HiPPO
- 재귀적 및 컨볼루셔널 표현을 생성하기 위한 이산화

이 SSM 클래스는 선택한 표현(재귀적 대 컨볼루셔널)에 따라 여러 가지 이점을 가지고 있으며, 텍스트의 긴 시퀀스를 처리하고 HiPPO 매트릭스를 기반으로 메모리를 효율적으로 저장할 수 있습니다.
상태 공간 모델, 심지어 S4(Structured State Space Model)조차도 언어 모델링 및 생성에서 중요한 특정 작업에서는 성능이 떨어집니다. 즉, 특정 입력에 집중하거나 무시하는 능력입니다.
이는 선택적 복사(Selective Copying) 및 유도 헤드(induction heads)라는 두 가지 합성 작업으로 설명할 수 있습니다.
선택적 복사 작업에서, SSM의 목표는 입력의 일부를 복사하여 순서대로 출력하는 것입니다.
왼쪽의 예시는 입력을 한 번에 한 토큰씩 다시 쓰되, 시간 이동(Time-shift)을 적용합니다. 이는 바닐라 SSM으로 수행할 수 있으며, 시간 지연은 컨볼루션 연산을 통해 학습할 수 있습니다.
하지만 선택적 복사의 경우, 예를 들어 트위터의 댓글이 주어졌을 때, 모든 나쁜 단어(흰색 토큰)를 제거하여 댓글을 다시 작성합니다.
이는 바닐라 SSM으로는 수행할 수 없는데, 이는 내용 인식 추론(content-aware reasoning)을 필요로 하기 때문입니다. 바닐라 SSM은 시간 불변(Time invariant)하기 때문에 내용 인식 추론을 할 수 없습니다. 시간 불변이란 생성하는 모든 토큰에 대해 매개변수 A,B,C가 동일하다는 것을 의미합니다.
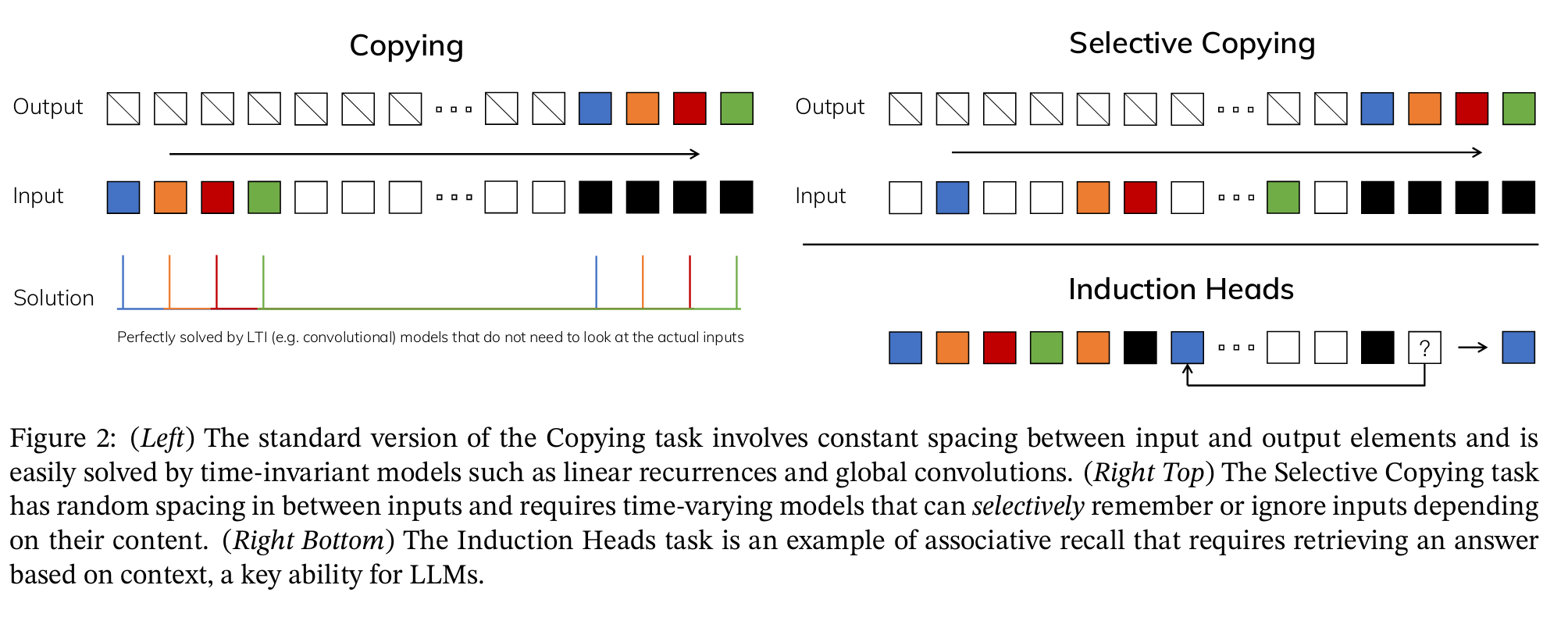
SSM이 성능이 떨어지는 두 번째 작업은 유도 헤드(induction heads)로, 입력에서 발견된 패턴을 재현하는 것이 목표입니다.
아래의 예시에서 우리는 기본적으로 한 번의 프롬프팅을 수행하고 있습니다. 여기에서 우리는 모델에게 "Q:" 후에 "A:" 응답을 제공하도록 "가르치려고" 시도합니다. 그러나 SSM이 시간 불변성을 가지고 있기 때문에, 이전 토큰 중 어떤 것을 기억할지 선택할 수 없습니다.

이를 행렬 B에 집중하여 설명해 봅시다. 입력 x가 무엇이든 관계없이 행렬 B는 정확히 동일하게 유지되므로 x와 독립적입니다.
마찬가지로, A와 C도 입력에 관계없이 고정되어 있습니다. 이는 지금까지 본 SSM의 정적인 특성을 보여줍니다.
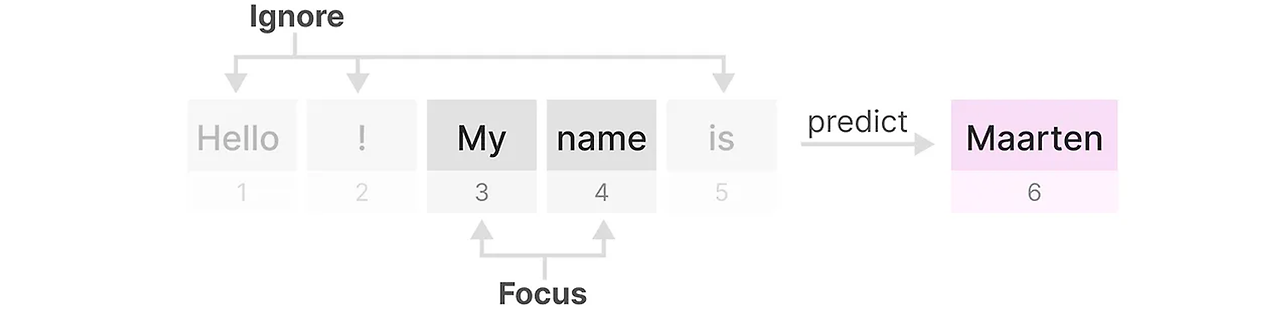
비교적으로, 이러한 작업들은 트랜스포머에게는 상대적으로 쉽습니다. 트랜스포머는 입력 시퀀스에 따라 동적으로 어텐션을 변경할 수 있습니다. 그들은 시퀀스의 다른 부분을 선택적으로 "보거나" "주의를 기울일" 수 있습니다.
SSM이 이러한 작업에서 성능이 떨어지는 것은 시간 불변성 SSM의 근본적인 문제, 즉 A, B, C 행렬의 정적인 특성으로 인한 내용 인식 문제를 시사합니다.

여러 작업(synthetic tasks)에서의 직관을 사용하여 선택 메커니즘에 대한 동기를 얻습니다. 그 후에 이 메커니즘을 상태 공간 모델(State Space Models)에 어떻게 통합하는지 설명합니다. 선택 메커니즘을 통합한 SSM은 시간에 따라 변하는(time-varying)한 특성을 가지게 되므로, 기존의 컨볼루션 연산을 직접 사용할 수 없습니다. 또한 저자들은 모던 하드웨어의 메모리 계층 구조를 고려한 알고리즘을 통해 문제해결을 논의합니다. 이후에 등장하는 간소화된 SSM 아키텍처는 Attention과 MLP 블록을 포함하지 않습니다.

Mamba Contribution1. input-dependent(입력 종속)방식으로 데이터를 효율적으로 선택하지 못하므로 선택 메커니즘에 대해 주요한 기여를 통해 상태 공간 모델 접근 방식 제안(simple selection mechanism). parameters 들을 매개 변수화 합니다.
SSM의 재귀적인 표현은 전체적인 기록을 압축하는 효율적인 작은 상태를 생성합니다.
그러나 어텐션 행렬을 통해 기록들을 전혀 압축하지 않은 Transformer와 비교해본다면 덜 강력한 상태이죠.
Mamba는 Transformer만큼의 성능을 내면서 작은 크기를 유지하고자 합니다.
이는 앞서 언급한 SSM처럼 데이터를 선택적으로 압축함으로써 이뤄낼 수 있습니다. 입력 문장을 가지고 있을 때, 종종 중요한 의미를 가지지 않는 정보 ( Stop words ) 가 있죠? 정보를 선택적으로 압축하려면 입력에 따라 매개변수가 달라져야 합니다. 이를 위해, 훈련 중 SSM의 입력과 출력의 차원을 먼저 알아야합니다.


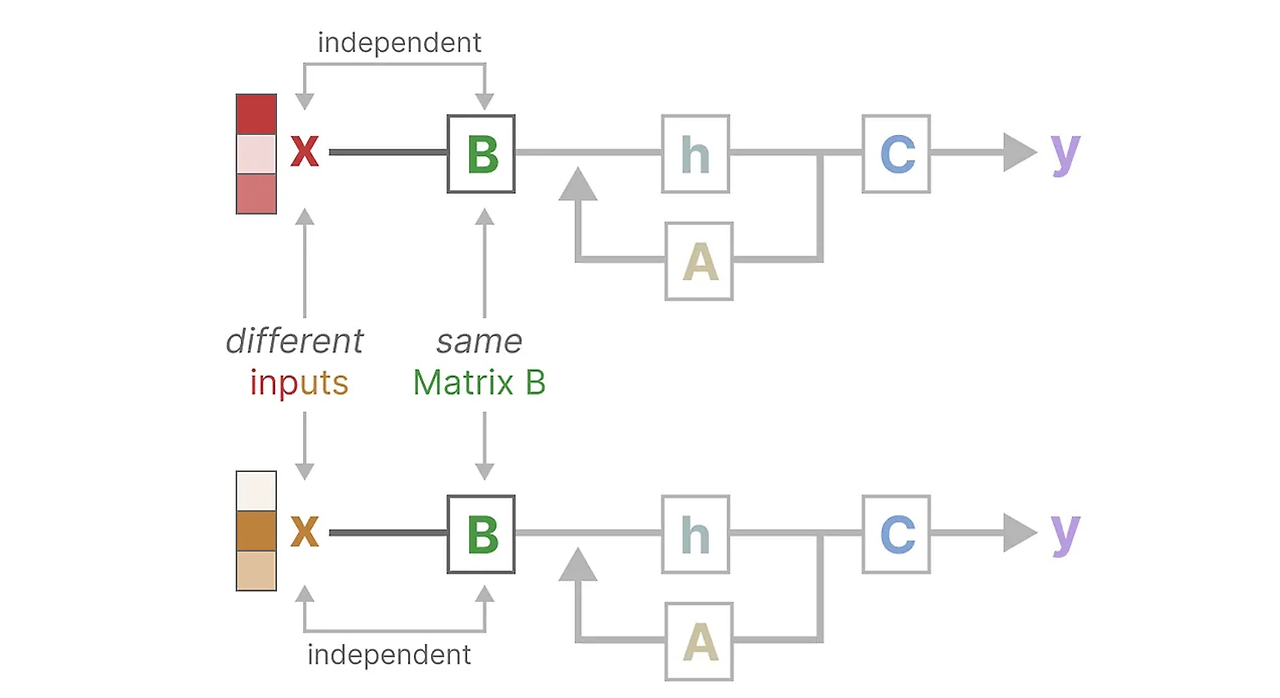
Structured State Space Model (S4)에서, 행렬 A, B, C는 입력과 독립적입니다. 그들의 차원 N과 D는 정적이며 변하지 않습니다.


대신, 맘바는 행렬 B와 C, 심지어 스텝 크기 ∆를 입력에 의존하도록 하여 입력의 시퀀스 길이와 배치 크기를 포함합니다.
이것은 이제 모든 입력 토큰에 대해 서로 다른 B와 C 행렬을 가지고 있다는 것을 의미합니다. 이렇게 만들면 내용 인식 문제를 해결할 수 있습니다.

행렬 A는 동일하게 유지됩니다. 왜냐하면 우리는 상태 자체가 정적으로 유지되기를 원하지만, 이것이 영향을 받는 방식(B,C를 통해)은 동적으로 유지되기를 원하기 때문입니다. 그리고 입력값에 의존하여 숨겨진 상태에서 어떤 요소를 유지하고 무시할지 선택적으로 고를 수 있습니다. 작은 Step size는 특정 단어를 무시하고 대신 이전 맥락을 더 사용하는 데 초점을 맞추게 됩니다. 큰 Step size는 맥락보다 입력 단어에 더욱 집중하도록 학습됩니다.

Mamba Contribution2. Convolution 대신 scan을 사용하여 모델을 반복적으로 계산하는 하드웨어 인식 알고리즘 제안합니다. a100 gpu 기준 최대 3배 더 빠릅니다.
앞서 언급했듯이 우리의 행렬이 동적이기 때문에, 고정된 kernel을 가정하는 컨볼루션을 더이상 사용할 수 없습니다.
컨볼루션의 병렬화를 잃고 재귀적인 표현만을 사용할 수 있습니다.
각 상태는 이전 상태(행렬 A에 의해 곱해진)와 현재 입력(행렬 B에 의해 곱해진)의 합입니다. 이것을 스캔 작업이라고 하며, for 루프를 사용하여 쉽게 계산할 수 있습니다. 병렬화와는 대조적으로, 이전 상태를 가지고 있어야만 각 상태를 계산할 수 있으므로 불가능해 보입니다. 그러나 맘바는 병렬 스캔 알고리즘을 통해 이것을 가능하게 합니다. 이것은 연산 순서가 중요하지 않다고 가정함으로써 수행됩니다. 결과적으로, 우리는 시퀀스를 부분적으로 계산하고 반복적으로 결합할 수 있습니다.
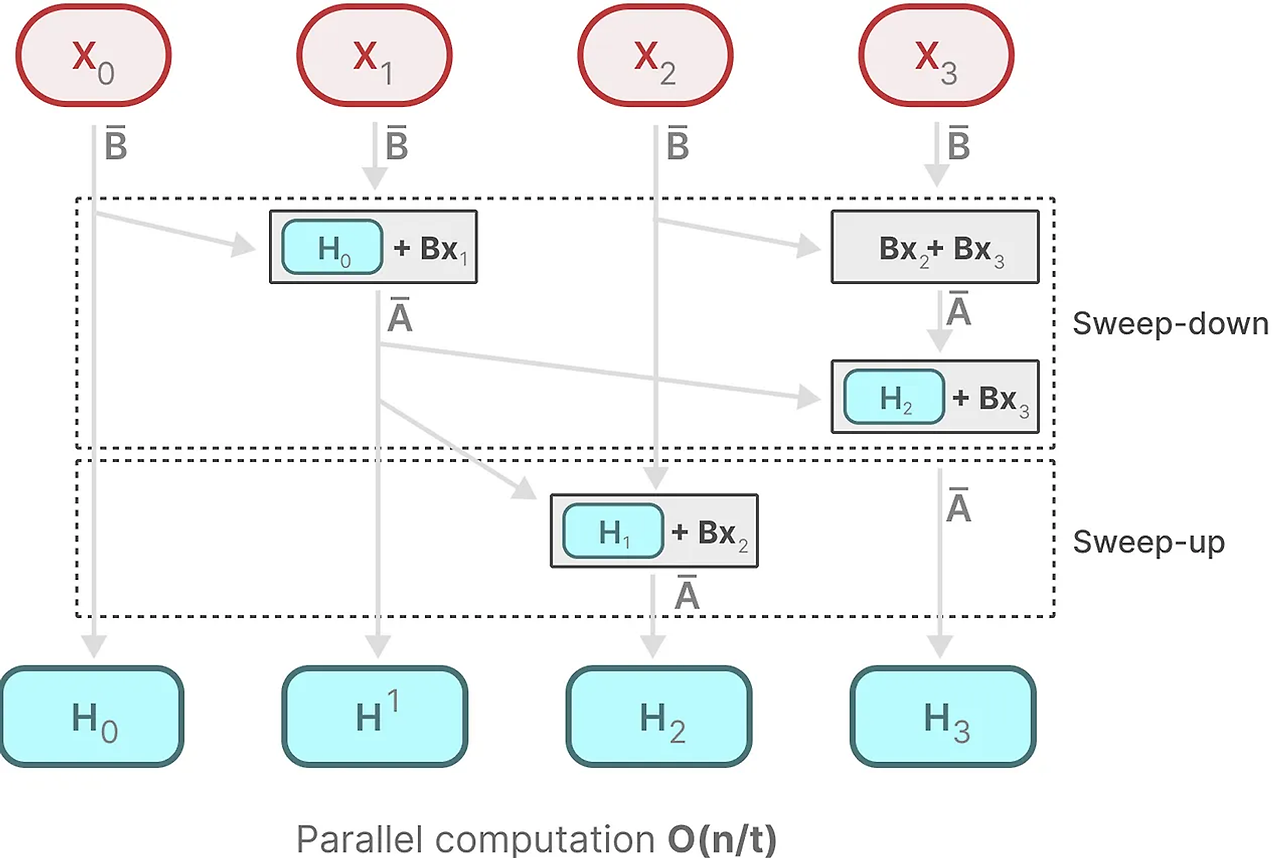
함께, 동적인 행렬 B와 C, 그리고 병렬 스캔 알고리즘은 재귀적 표현을 사용하는 동적이고 빠른 특성을 나타내는 선택적 스캔 알고리즘을 생성합니다.
하드웨어 인식 알고리즘
최근 GPU의 단점 중 하나는 작지만 매우 효율적인 SRAM과 크지만 약간 덜 효율적인 DRAM 사이의 전송(IO) 속도가 제한되어 있다는 것입니다. SRAM과 DRAM 사이에 정보를 자주 복사하는 것은 병목 현상이 됩니다. 딥러닝 프레임워크에서 텐서 연산 수행 시 , GPU의 HBM과 SRAM 간의 데이터 복사가 반복적으로 발생합니다. 데이터 복사 작업이 전체 수행 시간의 상당 부분을 차지하죠.
여러 개의 CUDA 커널을 하나의 커스텀 CUDA 커널로 융합하여 중간 결과를 HBM에 복사하지 않고 연산을 수행합니다.
최종 결과만 HBM에 저장함으로써 연산 속도를 향상시킬 수 있죠.
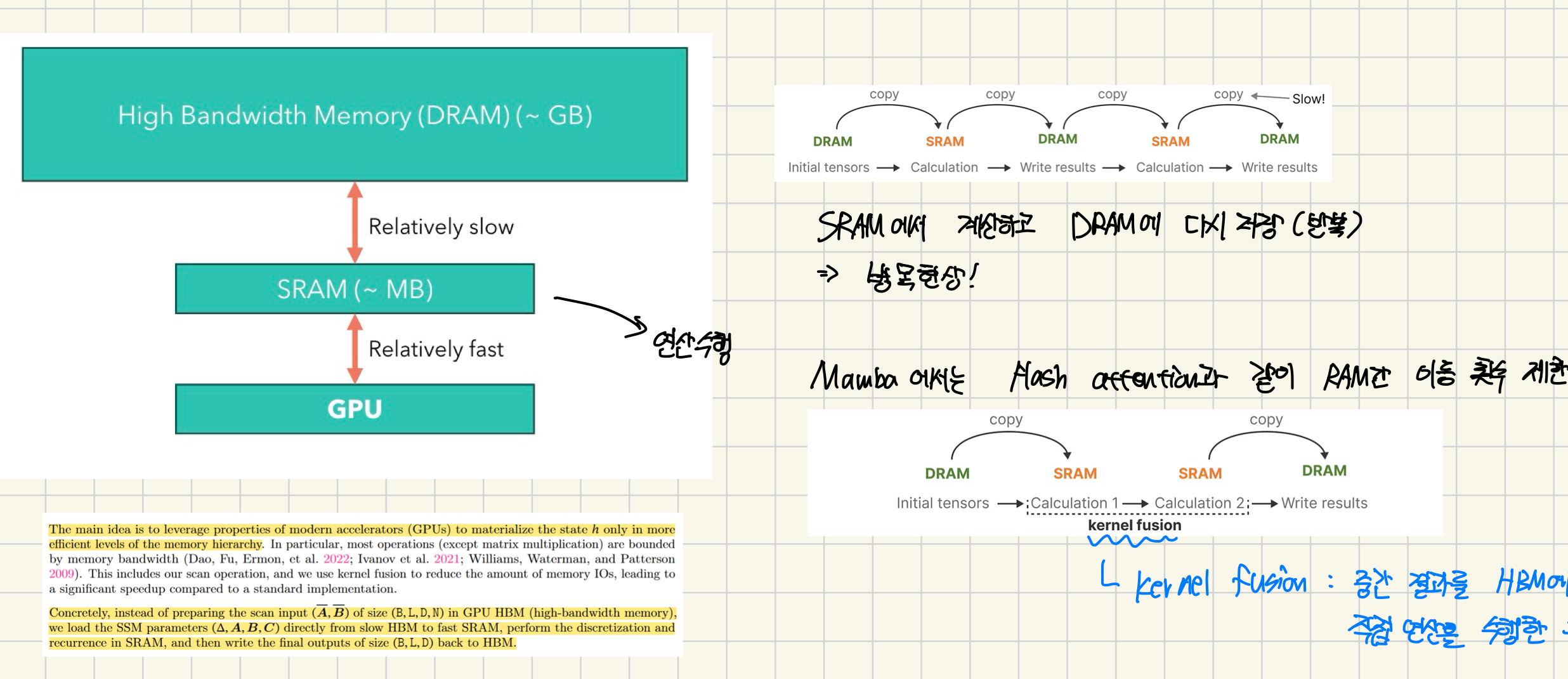
하드웨어 인식 알고리즘의 마지막 부분은 재계산 입니다.
중간 상태들은 저장되지 않지만, 그래디언트를 계산하기 위해 역방향 패스에서 필요합니다. 대신, 저자들은 역방향 패스 동안 이러한 중간 상태들을 재계산합니다. 이것이 비효율적으로 보일 수 있지만, 상대적으로 느린 DRAM에서 모든 중간 상태를 읽는 것보다 훨씬 비용을 절약할 수 있습니다.


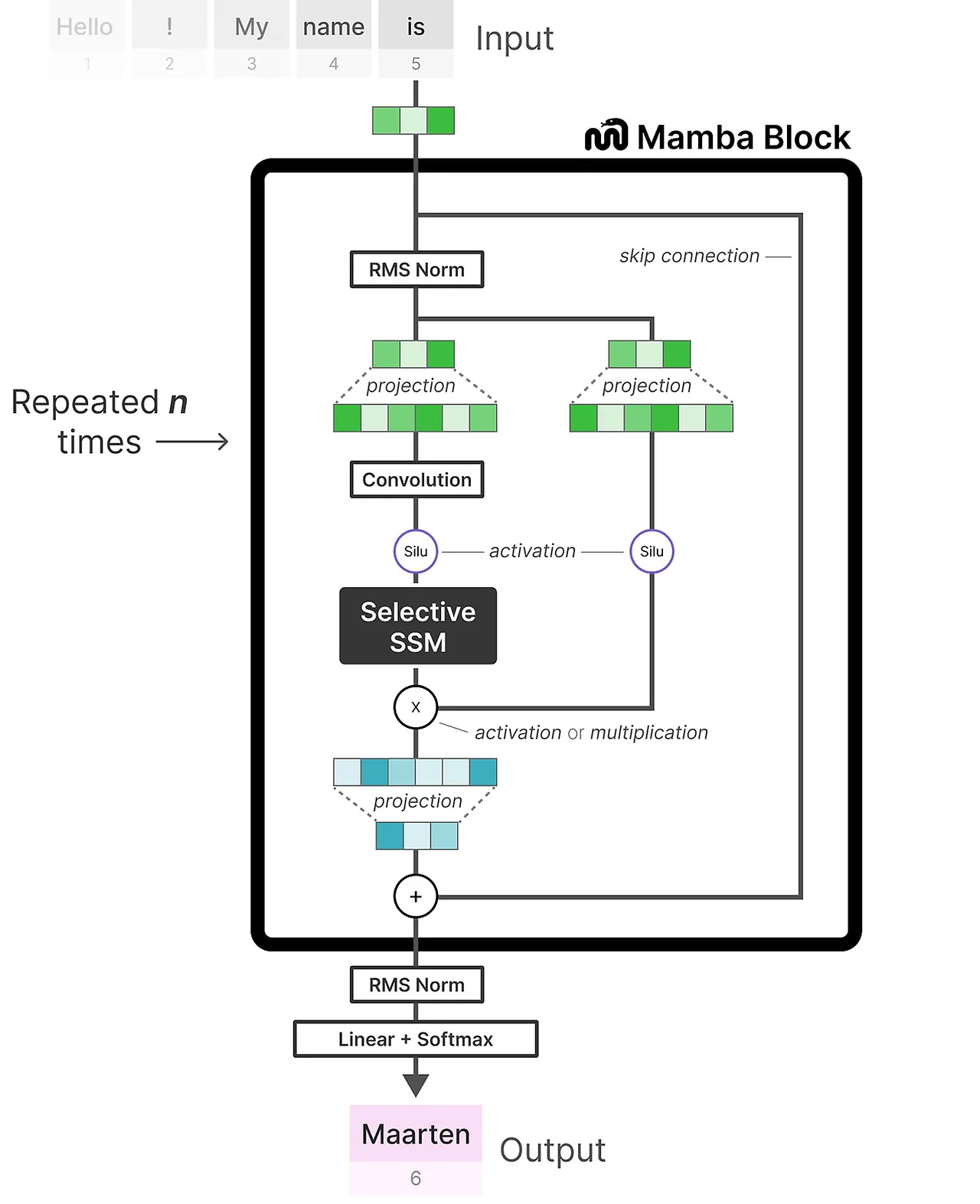
Mamba Contribution3. SSMs 아키텍처를 결합하여 이전 deep sequence model의 아키텍처를 단순화하는 것입니다. Transformer의 MLP 블록을 단일 블록으로 통합하여 상태 공간 모델을 기반으로 선택적 상태 공간을 통합하는 Mamba라는 간단한 SSMs 모델을 만들 수 있습니다.
Mamba Block은 Selective SSM이 디코더 블록에서 self-attention을 나타내는 것과 같은 방식으로 블록으로 구현될 수 있습니다.
디코더와 마찬가지로, 우리는 여러 맘바 블록을 쌓을 수 있으며, 그 출력을 다음 맘바 블록의 입력으로 사용할 수 있습니다.

선택적 SSM을 적용하기 전에 독립적인 토큰 계산을 방지하기 위한 컨볼루션이 사용됩니다.
선택적 SSM은 다음과 같은 특성을 가집니다:
- 이산화를 통해 생성된 재귀적 SSM
- 장거리 의존성을 포착하기 위한 HiPPO 초기화가 있는 행렬 A
- 정보를 선택적으로 압축하기 위한 선택적 스캔 알고리즘
- 계산 속도를 높이기 위한 하드웨어 인식 알고리즘
2. Related Work
Simplified State Space Layers for Sequence Modeling - 시퀀스 모델링을 위해 간소화된 상태 공간 레이어를 제안함 , 기존의 구조화된 상태 공간 모델을 단순화하여 효율성과 성능을 향상시킴
Long Range Arena: A Benchmark for Efficient Transformers - : 효율적인 Transformer 모델을 평가하기 위한 벤치마크 제안 , 장거리 의존성이 필요한 다양한 작업들로 구성되어 있음
Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks - 연속 시간 표현을 사용하는 Legendre Memory Unit (LMU)이라는 순환 신경망 모델 제안 , 연속 시간 표현을 통해 장기 의존성을 더 잘 포착할 수 있음
HiPPO: Recurrent Memory with Optimal Polynomial Projections - 최적의 다항식 투영을 사용하는 HiPPO (High-order Polynomial Projection Operator) 메모리 메커니즘 제안
Efficiently Modeling Long Sequences with Structured State Spaces - 구조화된 상태 공간을 사용하여 긴 시퀀스를 효율적으로 모델링하는 방법 제안 , 상태 공간 모델을 활용하여 계산 복잡도를 줄이고 병렬화 가능성을 높임
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers - 선형 상태 공간 레이어를 사용하여 순환, 합성곱, 연속 시간 모델을 결합하는 방법 제안 , 다양한 모델의 장점을 활용하여 시퀀스 모델링 성능을 향상시킴
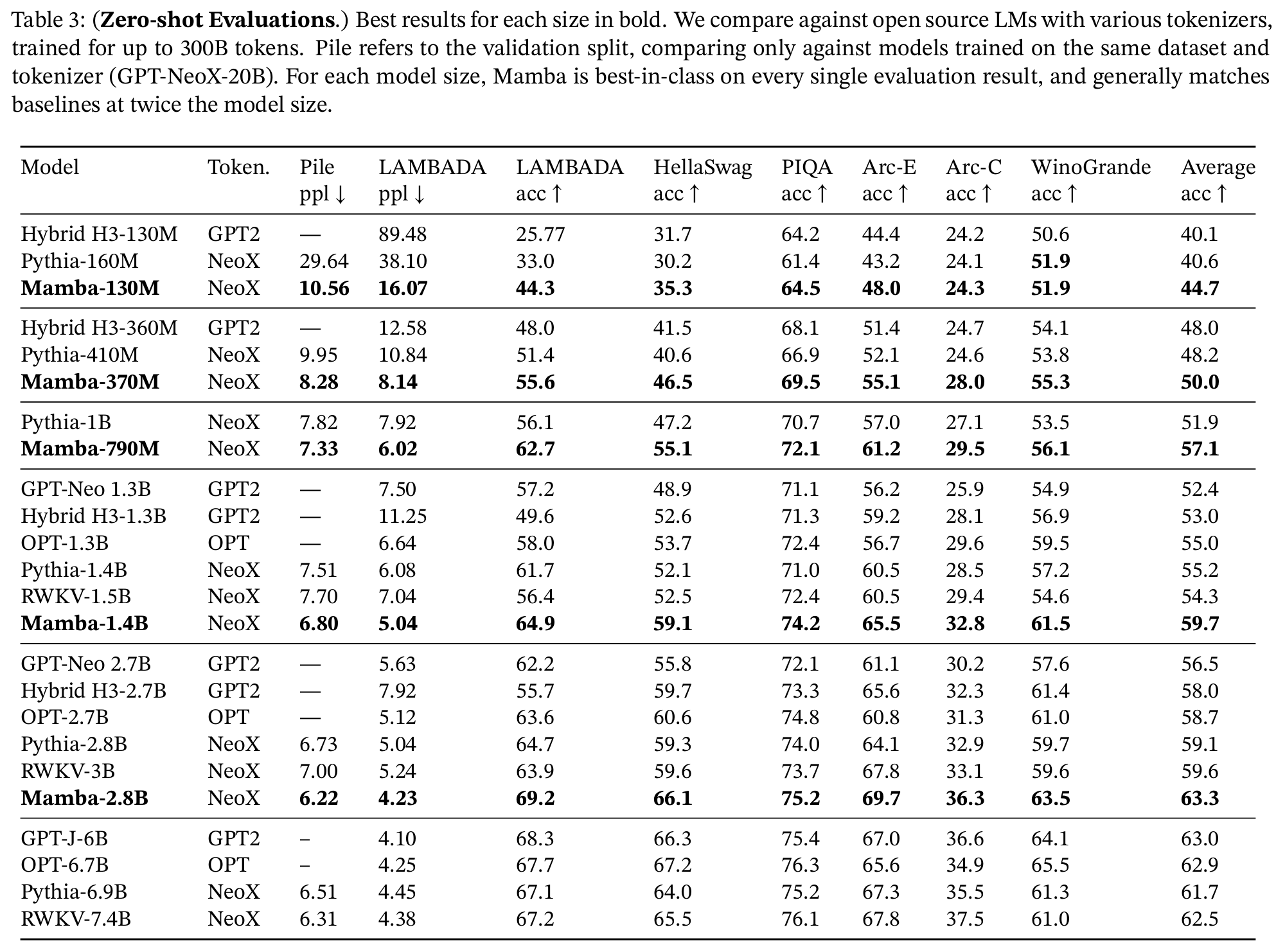
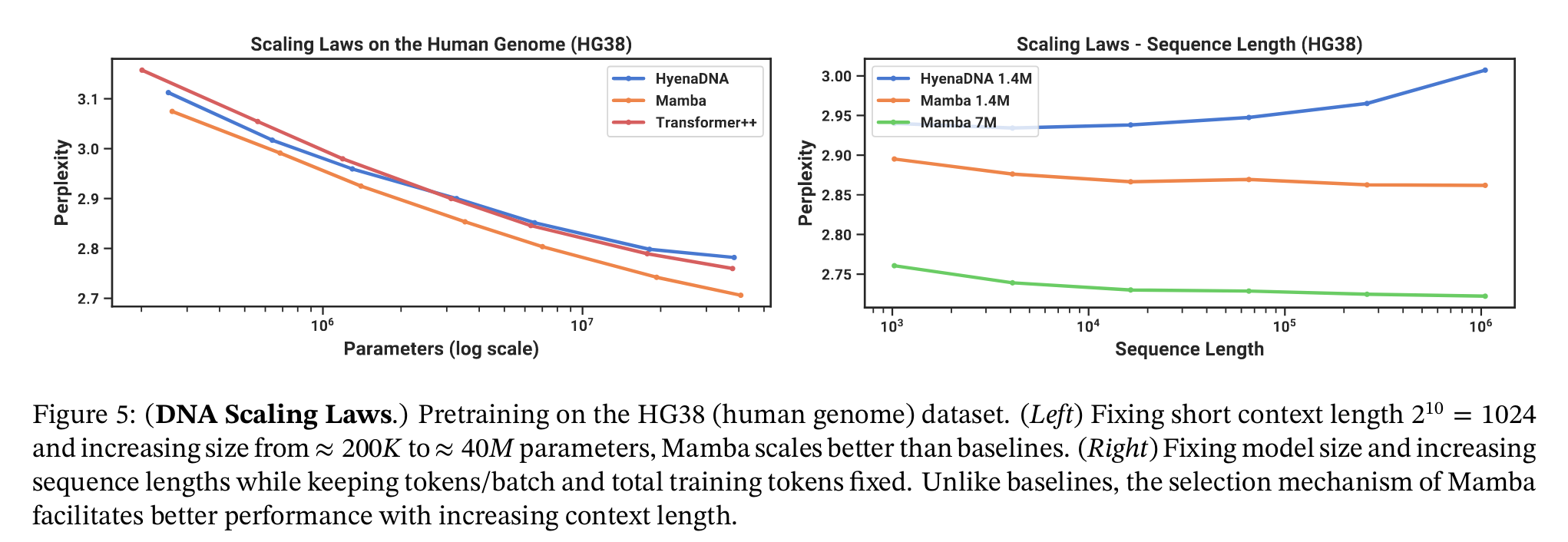
3. 실험 및 결과
Results

Conclusion
어렵다.. 맘바..