
1. Introduction
이전 Transformer 논문 리뷰 : https://minyoungxi.tistory.com/104
[논문리뷰] Attention is all you need - 트랜스포머를 모르면 취업을 못해요
Transformer의 탄생 배경 자연어 처리 분야에서 순환신경망(RNN)은 오랫동안 메인 모델로 사용되어 왔습니다. 하지만 RNN은 길이가 길어질수록 성능이 저하되는 단점이 있었습니다. 그래서 어텐션(Att
minyoungxi.tistory.com
원문 : https://arxiv.org/abs/2405.04517
xLSTM: Extended Long Short-Term Memory
In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they cons
arxiv.org
논문이 다루는 task
LSTM(Long Short-Term Memory) 모델을 확장하여 대규모 언어 모델링 작업에서의 성능을 향상시키는 것을 목표로 합니다. 이 논문은 LSTM을 수십억 개의 파라미터로 확장하고, 최신 기술을 적용하여 기존 LSTM의 한계를 극복하는 방법을 탐구합니다.
해당 task에서 기존 연구 한계점
1. 저장 결정 수정 불가능 : LSTM은 저장된 값을 더 유사한 벡터가 발견될 때 수정하는 능력이 부족합니다.
예를 들어, 가장 유사한 벡터를 찾아야 하는 최근접 이웃 검색 문제에서 LSTM은 이미 저장된 값을 수정하기 어려워합니다.
해결책: xLSTM은 지수 게이팅(exponential gating)을 도입하여 이 문제를 해결합니다.
2. 제한된 저장 용량 : LSTM은 정보를 스칼라 셀 상태로 압축하여 저장하기 때문에, 드문 토큰을 예측하는 데 있어 성능이 저하됩니다.
해결책: xLSTM은 매트릭스 메모리(matrix memory)를 도입하여 저장 용량을 확장합니다.
3. 병렬 처리의 부족 : LSTM은 메모리 혼합(memory mixing)으로 인해 시퀀스 처리에서 병렬화를 어렵게 합니다. 이는 연산을 순차적으로 처리해야 함을 의미합니다.
해결책: mLSTM은 메모리 혼합을 제거하고 완전 병렬화가 가능한 구조로 설계되었습니다.

2. Related Work
Linear Attention
- Synthesizer: 학습된 attention 가중치를 사용하여 토큰 간의 상호작용 없이 작동합니다 .
- Linformer: 저차원 행렬을 사용하여 self-attention을 실현하고 선형적으로 근사합니다 .
- Linear Transformer: attention 메커니즘을 선형화합니다 .
- Performer: 긍정적 직교 무작위 특징 접근법을 통해 주의 소프트맥스를 선형적으로 근사합니다 .
- SGConv 및 Hyena Hierarchy: 구조화된 글로벌 컨볼루션과 긴 컨볼루션을 사용하여 attention을 대체합니다 .
State Space Models (SSMs)
- Structured State Space (S4): 처음 제안된 모델로, 컨텍스트 길이에 대해 선형적이며 Transformer와 비교하여 유망한 성능을 보입니다.
- Diagonal State Space (DSS): 구조화된 상태 공간을 대각선으로 단순화한 모델입니다 .
- Gated State Space (GSS): 게이트를 추가하여 상태 공간 모델의 성능을 개선합니다 .
- Bidirectional Gated SSM (BiGS): 양방향 게이트를 사용하여 성능을 향상시킵니다 .
- H3 및 Mamba: 상태 공간 모델의 최근 발전을 반영하는 모델입니다.
3. 제안 방법론
Main Idea
기존 LSTM(Long Short-Term Memory) 모델을 확장하여 새로운 지수 게이팅과 메모리 구조를 도입함으로써, 대규모 언어 모델링 작업에서의 성능을 향상시키는 것입니다. LSTM의 한계를 극복하고 최신 기술을 적용하여 더 큰 모델을 구축하고, 이를 통해 LSTM이 트랜스포머(Transformers) 및 상태 공간 모델(State Space Models)과 경쟁할 수 있도록 합니다.
Contribution
지수 게이팅 ( Exponential Gating )
지수 게이팅(Exponential Gating)은 xLSTM에서 기존 LSTM의 Gating Machanism을 확장한 것입니다.
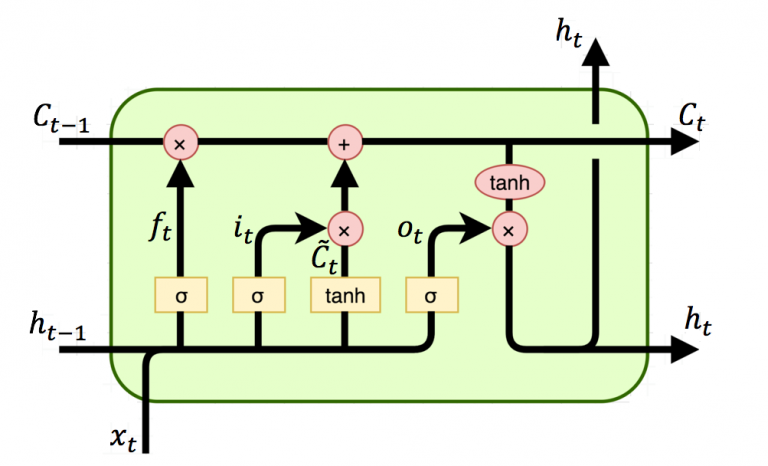
gate라는 것은 아래의 그림에 나와있는 것처럼 하나의 셀(cell)에 존재합니다.
Input gate, Forget gate, Output gate 이렇게 세 가지가 있습니다.
간단하게 설명하자면 이 gate들의 역할은 모델이 정보를 언제 저장하고 언제 삭제하며 언제 출력할지를 결정하는 데 사용됩니다.

기존 LSTM 모델의 gating 메커니즘은 이 게이트들이 시그모이드 함수를 사용하여 활성화 됩니다. 시그모이드 함수는 게이트의 출력값을 0~1 사이로 제한하여 정보의 흐름을 부드럽게 조절하는 역할을 합니다.
지수 게이팅(exponential gating)에서는 input gate 와 forget gate에 지수 함수(exponential function)을 사용합니다. 지수 함수는 게이트의 출력값을 더 넓은 범위로 확장하여 정보의 흐름을 더 강하게 또는 약하게 조절할 수 있도록 합니다.
이런 구조를 가지게 되면 모델이 저장된 정보를 더 유사한 정보로 대체할 수 있는 능력을 크게 향상시킵니다. 예를 들어, 새로운 입력이 기존에 저장된 정보보다 더 유사할 때, 모델이 이 정보를 쉽게 수정할 수 있습니다.
기존 LSTM 구조의 가장 큰 문제는 t-1에서 t로 넘어갈 때 t-1 의 정보를 모두 가져가는게 아니라 latent space 라는 하나의 벡터로 전달이 되죠? 이는 제한된 정보만을 넘겨주게 되므로 모델이 제대로 된 정보를 볼 수 없을지도 모릅니다.
지수 게이팅의 효과로는 정보 수정 능력이 향상된다는 것입니다. 또한 유연하게 정보를 조절할 수 있게 되죠. 게이트의 출력값 범위가 넓어지면서 모델이 조금 더 유연하게 정보를 조절할 수 있게 됩니다. 이는 모델이 다양한 상황에서 정보를 적절하게 처리하는 데 도움이 됩니다.
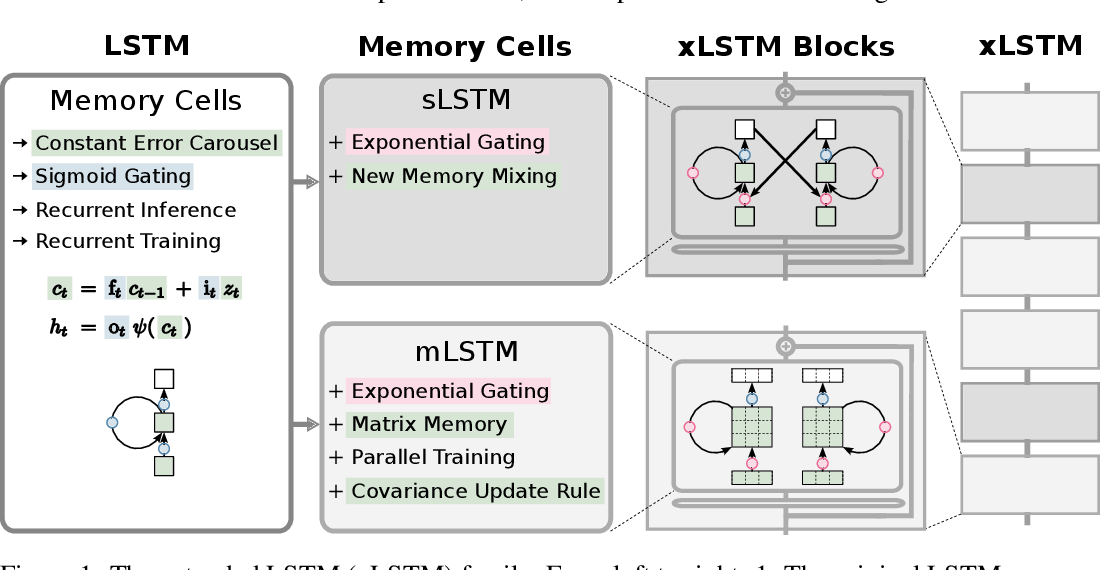
새로운 메모리 구조 (New Memory Structures): 두 가지 새로운 LSTM 변형을 제안합니다.
sLSTM : 스칼라 메모리와 스칼라 업데이트를 사용하며 새로운 메모리 혼합 기법(Memory Mixing)을 도입했습니다.
mLSTM : 메트릭스 메모리를 사용하며 공분산 업데이트 규칙을 도입합니다. 이렇게 함으로써 완전 병렬 처리가 가능해집니다.
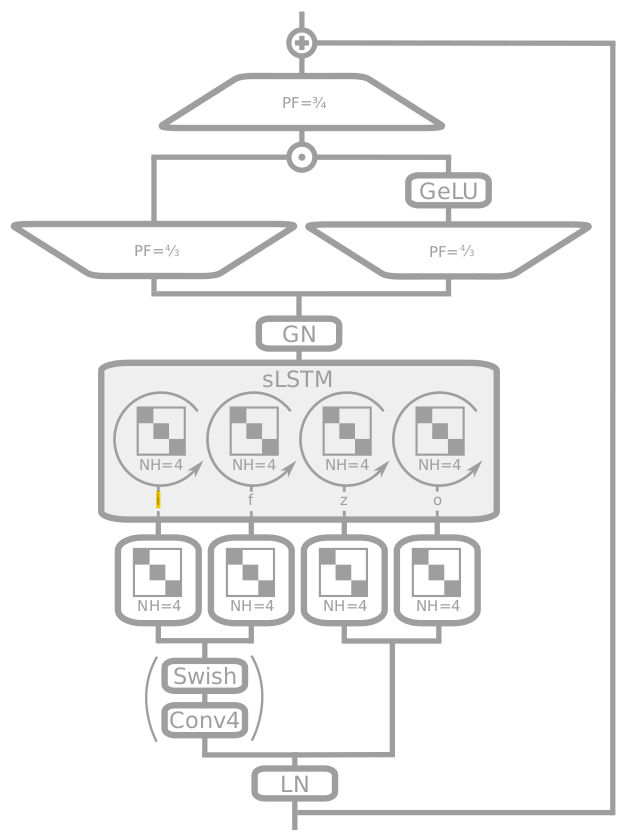

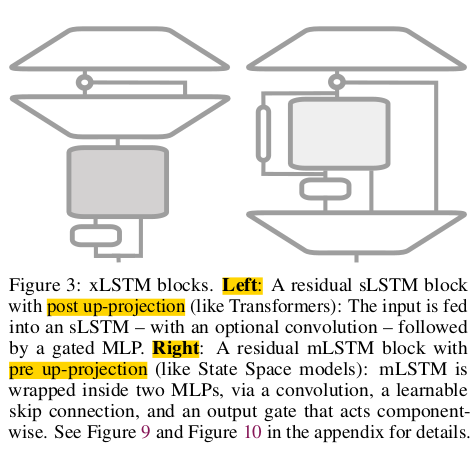
xLSTM 블록 : sLSTM과 mLSTM을 잔차 블록(Residual Block) 구조에 통합하여, xLSTM 블록을 설계합니다. 이 블록들을 계층적으로 쌓아서 xLSTM 아키텍쳐를 구축합니다. sLSTM 블록은 트랜스포머와 유사한 Post up-projection 구조를 , mLSTM 블록은 상태 공간 모델과 유사한 pre up-projection 구조를 채택했습니다.
4. 실험 및 결과
Dataset
실험에서 사용된 주요 데이터셋은 다음과 같습니다:
SlimPajama: 약 15B 토큰과 300B 토큰으로 구성된 대규모 언어 모델링 데이터셋입니다.
SlimPajama 15B: 15B 토큰으로 모델을 훈련하여 기본 성능을 평가합니다.
SlimPajama 300B: 300B 토큰으로 대규모 언어 모델을 훈련하여 확장 성능을 평가합니다.
Baseline
실험에서는 여러 기본 모델들과 xLSTM의 성능을 비교합니다:
Transformers:
- GPT-3: 350M 파라미터를 가진 트랜스포머 모델.
- Llama: 최근 트랜스포머 기반 언어 모델.
State Space Models (SSMs):
- H3
- Mamba
Recurrent Neural Networks (RNNs):
- RWKV-4
- RWKV-5
- RWKV-6
Linear Transformers:
- GLA (Gated Linear Attention)
- Retention
- Hyena
Results
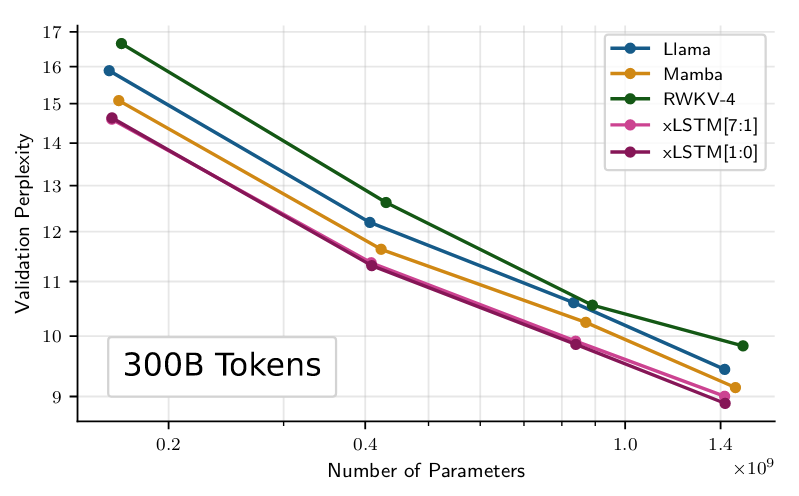
Validation Perplexity:
SlimPajama 15B 데이터셋에서의 결과:
xLSTM[1:0]: 13.43
xLSTM[7:1]: 13.48
이 결과는 다른 모델들(GPT-3, Llama, H3, Mamba, RWKV 시리즈 등)보다 우수함을 보여줍니다.
SlimPajama 300B 데이터셋에서의 결과:
xLSTM[1:0]과 xLSTM[7:1] 모두 8.89~9.00 범위 내에서 최고의 성능을 보였습니다.
Sequence Length Extrapolation:
긴 시퀀스 길이(최대 16384)에서 xLSTM 모델은 낮은 퍼플렉시티를 유지하며, 다른 모델들보다 더 긴 문맥에서 안정적으로 작동합니다.
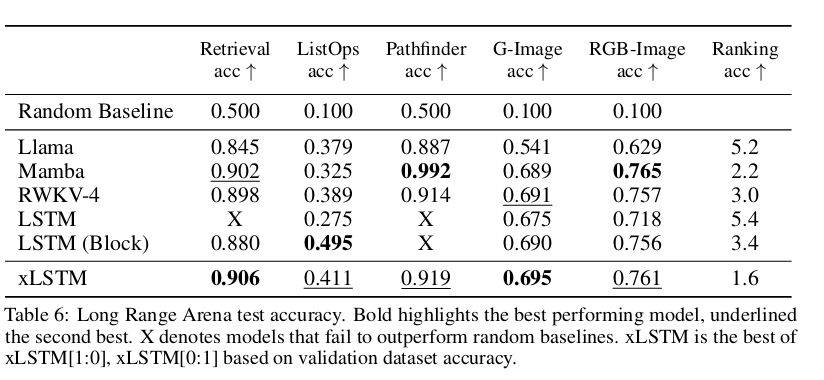
Downstream Tasks:
다양한 다운스트림 작업에서 xLSTM은 다른 모델들보다 우수한 성능을 보였습니다.
예를 들어, LAMBADA, HellaSwag, PIQA 등 다양한 작업에서 높은 정확도를 기록했습니다.
Scaling Laws:
모델 크기와 데이터 양이 증가함에 따라 xLSTM의 성능이 안정적으로 향상됨을 보여줍니다.
이는 xLSTM이 대규모 언어 모델로서 확장 가능성이 높음을 시사합니다.

Conclusion
본 논문은 시계열 연구나 LSTM에 관심이 많으신 분들이라면 매우 흥미롭게 읽으셨을 것이라 예상됩니다.
원문에는 수식의 비교가 매우 상세하게 설명되어 있으며 다른 논문에 비해 친절하게 가이드라인이 잡혀있습니다.
하지만 저자들은 한계점에서 sLSTM은 메모리 혼합(memory mixing) 때문에 병렬화된 연산을 허용하지 않아, 빠른 병렬 구현이 불가능하다고 합니다. CUDA 커널을 개발하여 sLSTM의 병렬 처리 성능을 향상시켰으나, 현재의 sLSTM CUDA 커널은 병렬 mLSTM 구현보다 약 1.5 배 느리다고 합니다.
mLSTM의 CUDA 커널은 최적화되지 않았기 때문에, 현재 구현은 Flash Attention이나 Mamba에서 사용되는 스캔보다 약 4배 느립니다.
이론적으로는 xLSTM의 속도가 더 빨라야 하는데, 막상 결과를 보니 Flash Attention이나 Mamba보다 느리다고 언급합니다.
이 논문의 저자 중 한 명은 LSTM을 1990년부터 연구한 사람입니다. 수학적으로 설명이나 이론에 매우 강하지만, 개인적으로는 아마 개발 능력이 뒷받침되지 못하지 않았나 생각이 드네요. 하지만 본 논문의 결과처럼 성능 면에서는 기존의 강력한 모델들보다 뛰어난 모습을 보여주었으니 기대가 됩니다 !