

1. Introduction

논문이 다루는 task
본 논문이 다루는 task는 온톨로지 엔지니어링에 딥러닝 기술, 특히 언어 모델을 통합하는 것입니다. 온톨로지 엔지니어링은 지식 표현과 추론을 위한 핵심 분야로, 온톨로지 설계, 구축, 평가, 유지보수 등 다양한 단계를 포함합니다. 온톨로지는 인간과 기계 모두 이해할 수 있는 개념과 관계의 체계를 제공함으로써 지식 공유와 활용을 촉진합니다.
최근 거대 언어 모델의 등장으로 기존 온톨로지 엔지니어링 방식의 한계를 극복할 수 있는 가능성이 열리고 있습니다. 예를 들어, BERT 등의 언어 모델은 풍부한 맥락 정보를 활용해 개념 간 유사도를 판단할 수 있어 온톨로지 정렬이나 완성 작업에 효과적입니다. 그러나 딥러닝 모델은 그 예측 과정이 불투명하고 대량의 학습 데이터를 필요로 한다는 한계도 있습니다.
해당 task에서 기존 연구 한계점
기존 연구의 한계점은 크게 두 가지로 볼 수 있습니다. 첫째, OWL API나 Jena 같은 기존 온톨로지 처리 도구는 안정적이고 표준 기반이지만, 딥러닝 프레임워크와 호환되지 않아 모델 개발과 적용이 쉽지 않습니다. 대부분 Java 기반인 반면 PyTorch, Tensorflow 등 주요 딥러닝 프레임워크는 Python 기반이기 때문입니다.
둘째, 딥러닝 기반 온톨로지 엔지니어링을 위해서는 온톨로지의 다양한 정보를 적절한 입력 형태로 변환하는 작업이 필수적이지만, 이를 지원하는 도구가 부족한 상황입니다. 단순한 용어 추출을 넘어 논리적 표현식의 자연어 변환, 그래프 구조로의 투영 등 보다 복잡한 처리가 요구되지만 기존 도구로는 수행이 쉽지 않습니다.
이에 본 논문에서는 Python 기반의 통합 온톨로지 엔지니어링 패키지 DeepOnto를 제안합니다. DeepOnto는 OWL API 기반의 핵심 처리 모듈과 다양한 부가 모듈을 제공해 온톨로지 정보를 딥러닝에 적합한 형태로 변환하고, 이를 활용한 정렬, 완성, 언어 모델 분석 등 다양한 태스크를 지원합니다. 이를 통해 딥러닝과 온톨로지의 상호보완적 통합을 도모하고자 합니다.
2. Related Work
related work 부분이 생략된 이유는 아마도 이 논문이 특정 태스크에 대한 새로운 모델을 제안하기보다는 포괄적인 온톨로지 처리 프레임워크를 소개하는 데 초점을 맞추고 있기 때문일 것 같습니다.
3. 제안 방법론
Main Idea
DeepOnto의 주요 아이디어는 온톨로지 엔지니어링을 위한 포괄적이고 유연한 Python 기반 프레임워크를 제공하는 것입니다. 특히 거대 언어 모델(LLM)과의 통합을 핵심 목표로 합니다.
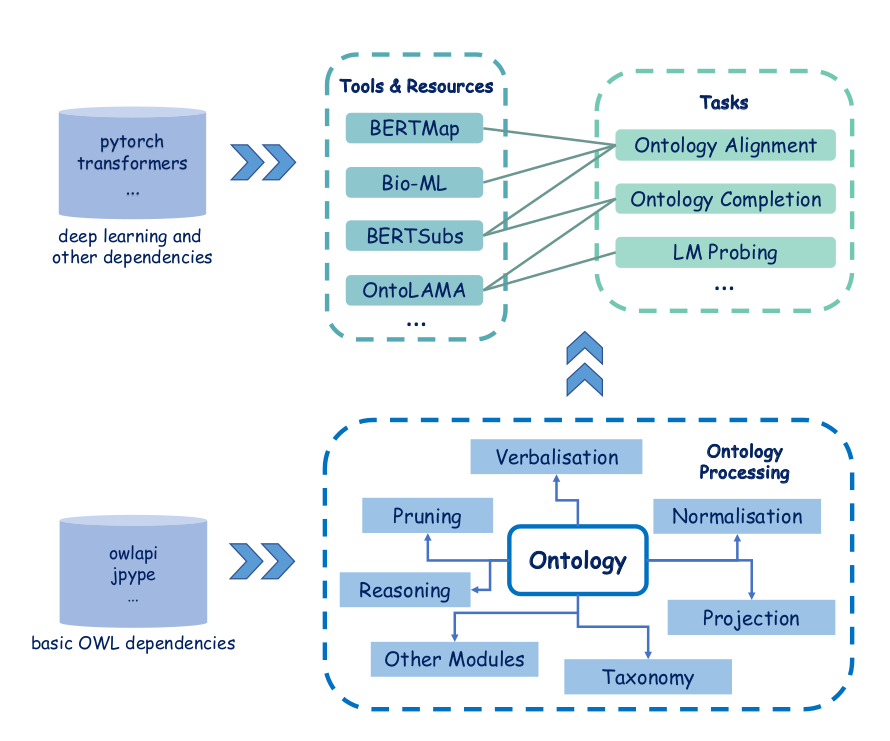
Figure 1은 DeepOnto의 전체 구조를 보여줍니다. 그 중심에는 OWL API 기반의 핵심 온톨로지 처리 모듈이 있습니다. 이 모듈은 기본적인 온톨로지 입출력과 조작 기능 외에도 추론(reasoning), 정규화(normalization), 자연어 변환(verbalization), 투영(projection) 등 다양한 부가 기능을 제공합니다. 이러한 기능들은 온톨로지를 딥러닝에 적합한 형태로 변환하는 데 핵심적인 역할을 합니다.
OWL API는 온톨로지를 생성, 조작, 직렬화하기 위한 고수준 프로그래밍 인터페이스를 제공하는 Java 기반 오픈소스 라이브러리입니다. OWL API는 온톨로지 언어 OWL(Web Ontology Language)을 기반으로 하며, 주로 시맨틱 웹 및 지식 표현 분야에서 널리 사용됩니다.
OWL 2 명세의 완전한 구현: OWL API는 OWL 2의 모든 프로파일(EL, QL, RL)과 직렬화 문법(Functional Syntax, RDF/XML, Turtle, Manchester Syntax 등)을 지원합니다.
온톨로지 생성 및 조작: 클래스, 속성, 인스턴스 등의 엔티티를 생성하고, 이들 간의 관계를 정의하는 axiom을 추가, 삭제, 수정할 수 있습니다.
온톨로지 추론 및 검증: HermiT, FaCT++, Pellet 등의 추론기와 연동해 implicit한 지식을 도출하고, 온톨로지의 일관성을 검사할 수 있습니다.
온톨로지 입출력 및 직렬화: OWL, RDF 등 다양한 형식으로 온톨로지를 읽고 쓸 수 있으며, 메모리 상의 온톨로지 객체를 직렬화할 수 있습니다.
모듈화 및 통합: OWL API는 모듈화된 구조를 가지며, OSGi 프레임워크를 통해 다른 시맨틱 웹 도구 및 라이브러리와 쉽게 통합될 수 있습니다.
핵심 모듈 위에는 개별 엔지니어링 태스크를 수행하는 다양한 도구와 자원이 구현되어 있습니다. 현재는 주로 언어 모델 기반의 온톨로지 정렬(BERTMap 등), 온톨로지 완성(BERTSubs), 언어 모델 프로빙(OntoLAMA) 등을 지원하고 있습니다. 그러나 모듈화된 구조 덕분에 임베딩, 개념 삽입 등 새로운 기능을 쉽게 추가할 수 있습니다.
그림에서 알 수 있듯이 Ontology 클래스와 함께 다양한 하위 모듈이 제공됩니다.
reasoning 모듈은 HermiT, ELK 등의 추론기를 사용해 implicit한 지식을 도출합니다.
verbalization 모듈은 복잡한 논리식을 자연어로 변환합니다.
normalization 모듈은 axiom을 정규형으로 변환하는데, 이는 모델 학습 시 입력 패턴을 단순화할 수 있습니다.
taxonomy 모듈은 개념 간 subsumption 관계를 그래프 형태로 추출합니다.
projection 모듈은 OWL 온톨로지를 RDF 트리플 집합으로 변환하는데, 이는 지식그래프 모델에 유용합니다.
이 외에도 pruning 등의 모듈이 포함되어 있습니다.
이러한 핵심 모듈 위에 개별 엔지니어링 태스크를 위한 도구와 자원이 구현됩니다.
BERTMap과 BERTSubs는 각각 온톨로지 정렬과 완성을 위한 BERT 기반 모델입니다.
Bio-ML은 정렬 모델 평가를 위한 벤치마크 데이터셋 및 프레임워크입니다.
OntoLAMA는 프롬프트 기반 subsumption 예측을 통해 언어 모델의 온톨로지 이해도를 진단합니다. 그림에서 점선으로 표시된 것처럼, 임베딩이나 개념 삽입 등의 새로운 태스크를 지속적으로 추가할 수 있습니다.
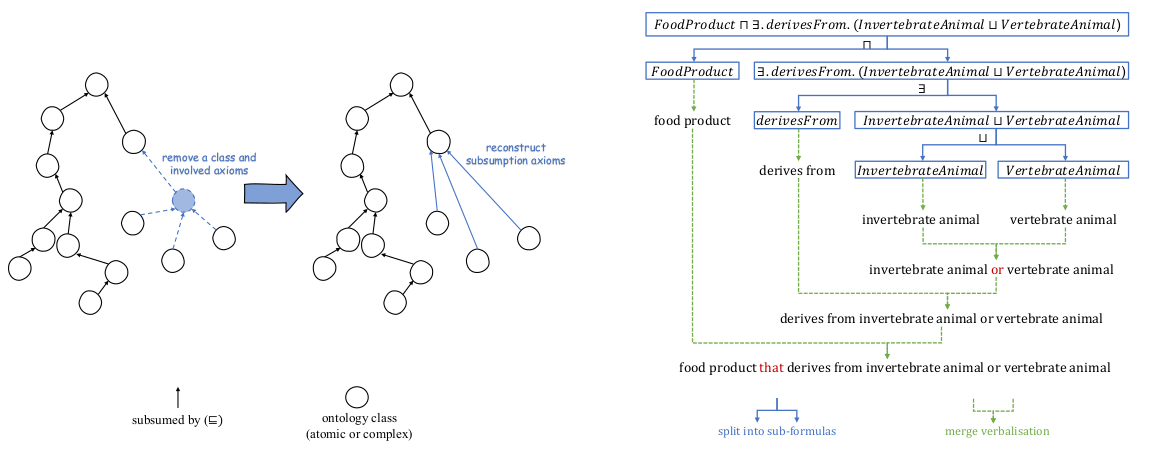
Figure 2는 DeepOnto가 제공하는 두 가지 주요 기능, 즉 온톨로지 pruning과 verbalization의 예시를 보여줍니다.
왼쪽 그림은 온톨로지 pruning 과정을 나타냅니다. Pruning은 온톨로지에서 불필요하거나 중복된 개념을 제거하여 온톨로지의 크기를 줄이는 기술입니다. 그러나 단순히 개념을 삭제할 경우 원래의 subsumption 계층 구조가 훼손될 수 있습니다.
이를 방지하기 위해 DeepOnto는 Bio-ML에서 제안된 pruning 알고리즘을 구현하고 있습니다. 이 알고리즘은 제거 대상 개념의 상위 개념과 하위 개념 간에 새로운 subsumption 관계를 추가함으로써 계층 구조를 유지합니다. 예를 들어, 그림에서 점선으로 표시된 개념을 제거할 때, 해당 개념의 상위 개념과 하위 개념을 직접 연결하는 파란색 실선의 subsumption 관계가 추가됩니다.
오른쪽 그림은 복잡한 개념 표현식(complex concept expression)을 자연어로 변환하는 verbalization 과정을 보여줍니다. 예시에서는 "FoodProduct ⊓ ∃derivesFrom.(InvertebrateAnimal ⊔ VertebrateAnimal)"이라는 표현식이 "food product that derives from invertebrate animal or vertebrate animal"이라는 자연어 문장으로 변환되고 있습니다.
DeepOnto는 OntoLAMA에서 제안된 재귀적 verbalization 알고리즘을 구현하고 있습니다. 이 알고리즘은 다음과 같은 절차를 따릅니다:
- 복잡한 개념 표현식을 구문 분석하여 트리 형태로 변환합니다.
- 트리의 잎 노드(leaf node)에 해당하는 원자 개념(atomic concept)과 역할(role)을 미리 정의된 자연어 템플릿에 따라 verbalization합니다.
- 내부 노드(internal node)에 대해서는 자식 노드의 verbalization 결과를 재귀적으로 합성합니다. 이때 논리 연산자(⊓, ⊔, ∃ 등)에 따라 적절한 자연어 표현을 사용합니다.
- 루트 노드에 도달할 때까지 위 과정을 반복하여 최종 verbalization 결과를 얻습니다.
Ontology Processing 논문 발췌 부분
- Ontology: DeepOnto의 기본 클래스로, OWL API의 핵심 기능을 래핑합니다. 온톨로지 파일 로드/저장, 엔티티 검색, 상위/하위 개념 탐색, axiom 수정 등의 작업을 수행할 수 있습니다.
- Ontology Reasoning: 온톨로지에 내재된 implicit한 지식을 추론하는 기능을 제공합니다. HermiT, ELK, Structural 등 다양한 추론 엔진을 지원하며, 개념 간 subsumption 관계, 불일치 검사 등을 수행할 수 있습니다.
- Ontology Pruning: 온톨로지에서 불필요한 개념을 제거하여 크기를 최적화하는 기능입니다. Bio-ML에서 제안된 알고리즘을 구현하여, subsumption 계층 구조를 보존하면서 pruning을 수행합니다.
- Ontology Verbalization: 개념, 속성, 제약 등 온톨로지의 주요 구성 요소를 자연어로 변환하는 기능입니다. 특히 OWL의 복잡한 논리식도 처리할 수 있는 재귀적 알고리즘을 제공합니다.
- Ontology Normalization: Axiom을 정규화된 형태로 변환하는 기능입니다. 정규화된 axiom은 패턴이 단순하므로 기계학습 모델의 학습을 용이하게 합니다.
- Ontology Taxonomy: 온톨로지의 개념 간 subsumption 관계를 추출하여 트리 또는 DAG 형태로 표현하는 기능입니다. 개념 계층 구조를 시각화하거나 분석하는 데 활용될 수 있습니다.
- Ontology Projection: OWL 온톨로지를 RDF 그래프로 변환하는 기능입니다. 변환 과정에서 익명 노드(blank node) 사용을 최소화하여, 그래프 임베딩 등의 작업에 적합한 형태로 투영합니다.
이들 기능은 상호 보완적으로 활용될 수 있습니다. 예를 들어, Reasoning을 통해 implicit한 subsumption 관계를 도출한 후 Taxonomy로 시각화하고, Verbalization을 통해 자연어 설명을 생성할 수 있습니다. 또한 Normalization과 Projection을 조합하면 온톨로지 임베딩에 적합한 입력 형태를 얻을 수 있습니다.
종합하면 Ontology Processing 모듈은 온톨로지에 대한 다각적인 접근을 지원함으로써, 온톨로지 기반 지식 그래프 구축, 온톨로지 정렬/통합, 온톨로지 기반 추론 및 설명 등 다양한 엔지니어링 태스크의 토대가 됩니다. 뿐만 아니라 딥러닝 모델과의 접점을 제공함으로써 신경-상징 통합 연구에도 기여할 것으로 기대됩니다.
Tools and Resources
- BERTMap: 두 온톨로지 간의 개념 정렬(alignment), 특히 동등 관계에 있는 개념 쌍을 찾는 도구입니다. BERT 언어 모델을 fine-tuning하여 개념 레이블 간 유사도를 계산하고, 이를 바탕으로 정렬 스코어를 산출합니다. 후보 개념 쌍 선정에는 서브워드 인덱싱을, 정렬 결과 확장에는 locality 원칙에 기반한 반복적 탐색을 활용합니다. BERTMap은 다양한 하이퍼파라미터 설정과 외부 리소스 활용을 지원하며, 경량화된 버전인 BERTMapLt도 제공합니다.
- BERTSubs: 단일 온톨로지 내에서 누락된 subsumption 관계를 예측하는 온톨로지 완성 도구(BERTSubs Intra)와, 두 온톨로지 간의 subsumption 정렬을 수행하는 도구(BERTSubs Inter)로 구성됩니다. 역시 BERT 기반으로, 개념 레이블을 Isolated, Path, Breadth 등의 방식으로 임베딩한 후 subsumption 여부를 분류합니다.
- Bio-ML: 의학 도메인 온톨로지들로부터 구축된 대규모 정렬 및 완성 벤치마크입니다. SNOMED-CT, FMA, NCIT, MONDO 등 7개 온톨로지 간의 조합으로 구성되며, 전문가 검증을 거친 Ground Truth 정렬을 제공합니다. 기존 벤치마크 대비 규모와 품질 면에서 개선되었을 뿐 아니라, subsumption 정렬을 포함하고 랭킹 기반 평가 지표를 도입했다는 점에서 기계학습 기반 온톨로지 정렬 연구에 기여할 것으로 기대됩니다.
- OntoLAMA: 기존 LAMA 프로빙 프레임워크를 온톨로지 도메인으로 확장한 벤치마크입니다. 다양한 온톨로지로부터 원자/복합 개념 간 subsumption 쿼리를 자동 생성하고, 이를 활용해 사전학습된 언어 모델의 개념적 추론 능력을 평가합니다. 특히 개념 verbalization 기술과 프롬프트 최적화를 통해, 적은 수의 Few-Shot 샘플로도 성능 향상을 달성했다는 점에서 의의가 있습니다.
각 도구는 DeepOnto의 핵심 모듈을 활용하여 구현되었으며, 모듈화된 설계 덕분에 쉽게 확장 및 개선될 수 있습니다. 특히 Bio-ML과 OntoLAMA는 단순히 평가 벤치마크를 넘어, 관련 태스크의 문제 설정과 방법론에 대한 통찰을 제공한다는 점에서 가치가 있습니다.
4. 실험 및 결과
Dataset
본 논문에서는 DeepOnto의 성능을 평가하기 위해 다양한 도메인과 규모의 온톨로지 데이터셋을 활용했습니다. 주요 데이터셋은 다음과 같습니다:
- Bio-ML: 의학 도메인의 SNOMED-CT, FMA, NCIT, MONDO 등 7개 온톨로지로 구성된 정렬 및 완성 벤치마크입니다. 전문가 검증을 거친 Ground Truth 정렬을 제공하며, 동등 관계와 subsumption 관계를 모두 포함합니다.
- OntoLAMA: 일반 도메인 온톨로지들로부터 추출한 subsumption 쿼리 데이터셋입니다. 원자 개념뿐 아니라 복합 개념 간의 subsumption 관계도 포함하며, 언어 모델의 개념적 추론 능력을 평가하는 데 활용됩니다.
- 산업 도메인 데이터셋: 삼성 리서치 UK의 Digital Health Coaching 프로젝트에서 사용된 NHS 건강 정보 온톨로지와 DOID 질병 온톨로지 간의 정렬 태스크를 수행했습니다.
Baseline
DeepOnto의 성능을 평가하기 위해 다음과 같은 기준 모델들과 비교했습니다:
- 온톨로지 정렬: LogMap, AML 등 기존 온톨로지 정렬 시스템과 String Matching 등 단순 문자열 기반 방법을 baseline으로 사용했습니다.
- 온톨로지 완성: TransE, DistMult 등 지식 그래프 임베딩 모델과 논리 기반 Reasoner를 baseline으로 삼았습니다.
- 언어 모델 프로빙: LAMA 벤치마크의 일반 도메인 태스크와 생의학 특화 벤치마크인 BLURB를 baseline으로 활용했습니다.
Results

실험 결과, DeepOnto는 대부분의 태스크에서 baseline 대비 우수한 성능을 보였습니다. 특히 Bio-ML 벤치마크에서 BERTMap과 BERTSubs는 각각 동등 관계와 subsumption 관계 정렬에서 가장 높은 정확도와 재현율을 달성했습니다.
OntoLAMA에서도 DeepOnto의 프롬프트 기반 접근법이 기존 방법 대비 현저히 적은 Few-Shot 샘플로 높은 성능을 얻을 수 있음을 확인했습니다.
산업 도메인 데이터셋에 대해서도 DeepOnto는 활용 가능한 수준의 정렬 품질을 보였습니다. 다만 out-of-domain 개념에 대한 오정렬이 관찰되었는데, 이는 도메인 특화 어휘 자원의 통합 등으로 개선될 수 있을 것으로 보입니다.
Conclusion
종합하면 DeepOnto는 온톨로지 정렬, 완성, 언어 모델 프로빙 등 다양한 엔지니어링 태스크에서 우수한 성능을 입증했습니다. 특히 딥러닝, 그 중에서도 언어 모델과의 통합을 통해 기존 방법론의 한계를 극복하고 새로운 접근법을 제시했다는 점에서 의의가 있습니다.
또한 Bio-ML, OntoLAMA 등 DeepOnto가 구축한 벤치마크 데이터셋은 관련 연구 커뮤니티에 유용한 자원이 될 것입니다. 온톨로지 정렬, 완성 등의 태스크에 머신러닝을 적용하고자 하는 연구자들은 이들 데이터셋을 활용해 보다 객관적이고 체계적인 실험을 수행할 수 있을 것입니다.
물론 아직 개선의 여지도 있습니다. 도메인 지식의 보다 효과적인 통합, 대규모 온톨로지에 대한 효율성 및 확장성 향상, 온톨로지 변경 사항의 실시간 반영 등은 향후 DeepOnto가 지속적으로 연구해야 할 주제들입니다. 그러나 현재의 성과와 발전 가능성에 비추어 볼 때, DeepOnto는 온톨로지와 딥러닝의 융합을 선도하는 플랫폼으로서 자리매김할 수 있을 것으로 기대됩니다.