
이전 논문 : Transformer - attentioon is all you need

1. Introduction
- 논문이 다루는 task
- Input : 무한한 길이의 시퀀스 (Infinitely long sequences)
- Output : 입력 시퀀스에 대한 처리 결과 (Processed output of the input sequence)
- 해당 task에서 기존 연구 한계점
- Transformer의 quadratic attention complexity로 인해 무한한 길이의 입력을 처리하는 데 한계가 있습니다.
- quadratic attention complexity란 어텐션 메커니즘의 계산 복잡도를 의미합니다. Transformer에서 사용되는 어텐션 메커니즘은 각 토큰이 다른 모든 토큰과의 관계를 계산하기 때문에, 입력 시퀀스의 길이가 증가함에 따라 계산량이 quadratic하게 증가합니다.
- 구체적으로, 입력 시퀀스의 길이를 L이라고 할 때, 어텐션 계산의 시간 및 공간 복잡도는 $O(L^2)$ 입니다. 이는 입력 시퀀스의 길이가 두 배로 늘어나면, 어텐션 계산에 필요한 시간과 메모리가 4배로 증가함을 의미합니다.
- Transformer는 어텐션 윈도우(attention window) 이전의 컨텍스트 정보를 잊어버리는 문제가 있음. 반면, LSTM은 이론적으로 정보를 무한히 전파할 수 있음.
- Self-Attention은 고정된 크기의 어텐션 윈도우(attention window)를 가지고 있어, 이 윈도우 바깥의 정보는 직접적으로 참조할 수 없습니다.
- 이론적으로, LSTM의 셀 스테이트는 그래디언트 소실(vanishing gradient) 문제 없이 정보를 무한히 전파할 수 있습니다.
- 하지만 실제로는 LSTM도 매우 긴 시퀀스에 대해서는 정보를 무한히 전파하기 어려우며, Transformer의 병렬 처리 능력과 확장성이 더 뛰어나다는 장점이 있습니다.
- 기존의 Sparse Attention, Linear Attention 등의 기법들은 1B 규모 이하에서는 효과적이지만, GPT-3 수준의 대규모 모델에서는 잘 작동하지 않음.
- Sparse Attention : 전체 토큰 간의 관계를 계산하는 대신, 중요한 토큰들 간의 관계만 선별적으로 계산함으로써 계산 복잡도를 줄입니다. Sparse Attention은 전역 어텐션(global attention)과 국소 어텐션(local attention)을 적절히 조합하여 사용합니다. 이를 통해 quadratic complexity를 줄이면서도, 중요한 정보는 유지할 수 있습니다.
- Linear Attention : Linear Attention은 어텐션 계산을 근사화하여 계산 복잡도를 $O(L^2)$ 에서 $O(L)$ 로 줄이는 방법입니다. Linear Attention은 이론적으로 어텐션의 계산 복잡도를 선형 시간으로 줄일 수 있지만, 근사화로 인한 정보 손실이 발생할 수 있습니다.
- 현재 SOTA 대규모 언어 모델(LLM)들은 대부분 근사화된 어텐션(approximated attention)에 크게 의존하지 않음.

Figure 1은 Sliding Window Attention(SWA)의 변형들에 대한 query-key attention mask를 비교하여 보여주고 있습니다.
(a) Sliding Window Attention (SWA):
- Attention이 현재 윈도우(window size=3)로 제한됩니다.
- Query는 같은 윈도우 내의 key들과만 어텐션을 수행합니다.
(b) Block Sliding Window Attention (BSWA) (block size=2, memory segment=1):
- Attention이 현재 블록과 이전 메모리 세그먼트 내의 블록들로 확장됩니다.
- Query는 현재 블록과 메모리 세그먼트 내의 이전 블록들의 key와 어텐션을 수행합니다.
(c) BSWA (block size=2, memory segment=2):
- 메모리 세그먼트가 확장되어, query가 더 많은 이전 블록들의 key와 어텐션을 수행할 수 있습니다.
- 즉, 더 큰 과거 컨텍스트에 대한 attention이 가능해집니다.
(d) BSWA의 receptive field (block size=2, memory segment=1, depth=4):
- 중괄호 안의 영역이 receptive field를 나타냅니다.
- Receptive field는 query가 어텐션을 통해 정보를 얻을 수 있는 과거 컨텍스트의 범위를 의미합니다.
- Receptive field의 크기는 대략 model depth × window size로 결정됩니다.
이 그림을 통해 SWA와 BSWA의 attention 패턴 차이와, BSWA에서 메모리 세그먼트 크기에 따른 과거 컨텍스트 참조 범위의 변화를 이해할 수 있습니다. 또한, BSWA의 receptive field 개념과 그 크기를 결정하는 요인을 파악할 수 있습니다. 이는 TransformerFAM을 이해하는 데 중요한 기초 지식으로 활용됩니다.

Figure 2는 TransformerBSWA와 TransformerFAM의 attention 패턴을 비교하여 보여줍니다.
(a) TransformerBSWA:
- Input query는 현재 블록과 두 개의 메모리 세그먼트에 attend하여 과거 컨텍스트를 참조합니다.
- 각 블록은 독립적으로 처리되며, 이전 블록의 정보는 메모리 세그먼트를 통해서만 전달됩니다.
(b) TransformerFAM:
- Input query는 현재 블록, 메모리 세그먼트, 그리고 이전 FAM에 attend합니다 (녹색 선).
- 이전 FAM은 과거의 압축된 글로벌 컨텍스트 정보를 포함하고 있어, input query가 더 풍부한 컨텍스트를 활용할 수 있게 합니다.
- FAM query는 이전 FAM에서 복사되어 (파란색 점선 화살표), 현재 블록을 압축하여 FAM을 업데이트합니다.
- FAM query는 이전 FAM에 조건화되어 동적으로 생성되므로, 과거의 글로벌 컨텍스트 정보를 고려하여 현재 블록을 압축할 수 있습니다.
- 업데이트된 FAM은 다시 다음 블록으로 전파되어, 글로벌 컨텍스트 정보를 재귀적으로 전달합니다.
- 이러한 피드백 루프를 통해 정보의 압축과 전파가 무한한 시퀀스 길이에 대해 이루어질 수 있으며, 이는 워킹 메모리의 역할을 합니다.
TransformerFAM의 핵심은 피드백 루프를 통해 FAM이 과거의 글로벌 컨텍스트를 압축하고 전파하는 것입니다. 이를 통해 TransformerBSWA 대비 더 풍부한 컨텍스트 정보를 활용할 수 있으며, 무한한 길이의 시퀀스에 대해서도 정보를 유지할 수 있게 됩니다. 이는 Transformer에 워킹 메모리의 개념을 도입한 것으로 볼 수 있습니다.
2. Related Work
- 긴 컨텍스트를 처리하기 위한 기존 연구
- Sparse Attention 기법
- 전체 어텐션 매트릭스 중 일부 토큰들 간의 관계만 계산하여 계산 복잡도를 줄이는 방법
- 대표적인 예: Sparse Transformer, Longformer, Big Bird 등
- Linear Attention 기법
- 어텐션 계산을 근사화하여 계산 복잡도를 $O(L^2)$에서 $O(L)$로 줄이는 방법
- 대표적인 예: Linformer, Performer, Linear Transformer 등
- Sparse Attention 기법
- 피드백 메커니즘을 Transformer에 도입한 연구
- 대부분의 연구는 최상위 레이어의 출력을 최하위 레이어로 전달하거나, 중간 레이어로 전달하는 방식을 사용
- 본 논문에서는 중간 레이어 간의 피드백 메커니즘을 제안하여 차별화
- 블록 단위로 정보를 압축하는 연구
- 기존 연구들은 블록 단위로 정보를 압축하지만, 압축된 정보가 재귀적으로 연결되지는 않음
- 본 논문에서는 Feedback Attention Memory(FAM)을 통해 압축된 정보를 다음 블록으로 전파할 수 있도록 함
- 최신 SOTA 대규모 언어 모델(LLM)
- GPT-3, PaLM, Chinchilla, Megatron-Turing NLG 등
- 대부분의 SOTA LLM들은 어텐션 근사화 기법보다는 모델 크기를 극대화하는 데 주력
- 수백억 개 이상의 파라미터를 가진 거대한 모델들은 full attention을 사용하며, 대규모 컴퓨팅 자원을 활용
본 논문은 기존 연구들과 달리, Transformer의 중간 레이어 간 피드백 메커니즘을 도입하고, 블록 단위로 압축된 정보를 재귀적으로 전파할 수 있는 Feedback Attention Memory(FAM)를 제안하여 차별화된 접근 방식을 취하고 있습니다. 이를 통해 대규모 언어 모델의 효율성을 높이면서도, 장기 의존성을 모델링할 수 있는 능력을 갖추고자 합니다.
3. 제안 방법론
Main Idea
- 해당 모델이 어떤 차별점을 가지나요 ?
- TransformerFAM은 피드백 루프를 통해 Transformer 내에 워킹 메모리를 생성하여, 무한한 길이의 시퀀스를 처리할 수 있도록 합니다.
- FAM은 블록 단위로 정보를 압축하고, 압축된 정보를 다음 블록으로 전파할 수 있어 장기 의존성을 효과적으로 모델링할 수 있습니다.
- TransformerFAM은 기존 Transformer에 새로운 가중치를 추가하지 않아 사전 학습된 모델과 쉽게 통합될 수 있습니다.
- 해당 모델은 어떤 모델을 토대로 만들어졌나요?
- TransformerFAM은 기본적으로 Transformer 아키텍처를 기반으로 합니다.
- 구체적으로는 Block Sliding Window Attention (BSWA) 기법을 적용한 TransformerBSWA를 토대로 FAM을 도입하여 개발되었습니다.
- 해당 모델의 pretraining 목적함수는 무엇인가요?
- 본 논문에서는 사전 학습된 언어 모델(예: Flan-PaLM)을 사용하였으며, 추가적인 사전 학습(pretraining) 없이 fine-tuning만 수행하였습니다.
- Fine-tuning 시에는 기존 언어 모델의 손실 함수(일반적으로 교차 엔트로피 손실)를 그대로 사용하였습니다.
- 실험에 사용하는 데이터는 무엇인가요?
- Fine-tuning에는 Flan 데이터셋의 instruction data를 사용하였습니다.
- 이상적으로는 장문의 연속적인 텍스트(예: 교과서, 소설 등)를 사용하는 것이 좋지만, 적절한 데이터셋을 찾기 어려워 Flan instruction data를 사용하였습니다.
- 평가를 위해서는 다양한 장문 컨텍스트 태스크(예: NarrativeQA, Scrolls-Qasper, Scrolls-Quality, XLSum 등)와 GPT-3 벤치마크 태스크를 사용하였습니다.
앞서 언급했듯이 'Attention is all you need' 논문에서는 모든 입력값의 시퀀스에 대해 full attention을 수행하는 구조입니다. 하지만 full attention은 시퀀스 길이가 길어질수록 메모리와 계산 복잡도가 quadratic하게 증가하는 문제가 있습니다. 이를 해결하기 위해 후속 연구들에서 SWA, BSWA와 같은 기법들이 제안되었습니다.
대표적인 예로, Transformer-XL(Dai et al., 2019)에서는 segment-level recurrence와 함께 fixed-size memory cache를 사용하여 긴 시퀀스를 처리할 수 있도록 했습니다. 이는 BSWA와 유사한 접근 방식입니다.
Longformer(Beltagy et al., 2020)에서는 sliding window attention과 global attention을 함께 사용하여 긴 시퀀스에 대한 어텐션을 효율적으로 계산할 수 있도록 했습니다.
이처럼 SWA, BSWA 등의 기법은 원래의 Transformer 이후에 제안된 개념이지만, 현재는 긴 컨텍스트를 처리하기 위한 Transformer 모델에서 널리 사용되고 있습니다. 본 논문의 TransformerFAM 역시 BSWA를 기반으로 하여 개발된 모델입니다.
메모리 세그먼트 (Memory Segment)가 뭘까 ?
메모리 세그먼트(Memory Segment)는 Block Sliding Window Attention(BSWA)에서 사용되는 개념으로, 현재 블록에서 참조할 수 있는 이전 블록들의 범위를 나타냅니다.
BSWA에서는 입력 시퀀스를 고정된 크기의 블록으로 나누어 처리합니다. 예를 들어, 블록 크기가 1024라면, 입력 시퀀스는 1024개의 토큰씩 나누어져 각각의 블록으로 처리됩니다.
이때, 현재 블록의 토큰들이 이전 블록들의 정보를 참조할 수 있도록 하는 것이 메모리 세그먼트의 역할입니다. 메모리 세그먼트의 크기는 하이퍼파라미터로 설정됩니다. 예를 들어, 메모리 세그먼트 크기가 2라면, 현재 블록은 바로 이전 2개의 블록까지 참조할 수 있습니다.
Figure 1의 (b)와 (c)를 보면 메모리 세그먼트의 개념을 시각적으로 이해할 수 있습니다.
(b)에서는 메모리 세그먼트 크기가 1입니다. 따라서 현재 블록은 바로 이전 블록의 정보만 참조할 수 있습니다.
(c)에서는 메모리 세그먼트 크기가 2입니다. 따라서 현재 블록은 이전 2개의 블록까지 참조할 수 있습니다.
메모리 세그먼트를 사용하면, 현재 블록이 이전 블록들의 정보를 참조할 수 있으므로, 일종의 컨텍스트 정보를 전달할 수 있게 됩니다. 이는 긴 시퀀스를 처리할 때 유용합니다. 다만, 메모리 세그먼트의 크기는 고정되어 있으므로, 참조할 수 있는 이전 정보의 범위에는 한계가 있습니다.
이러한 메모리 세그먼트의 한계를 극복하고, 보다 장기적인 정보를 전달할 수 있도록 하는 것이 본 논문에서 제안하는 Feedback Attention Memory(FAM)의 역할입니다.
예를 들어서, "나는 학생 입니다" 라는 문장이 있을 때,
- 메모리 세그먼트 크기가 1인 경우:
- 블록 1: ["나", "는"]
- 블록 2: ["학", "생"] + 블록 1의 정보
- 블록 3: ["입", "니"] + 블록 2의 정보
- 블록 4: ["다"] + 블록 3의 정보 각 블록은 바로 이전 블록의 정보를 메모리 세그먼트를 통해 참조할 수 있습니다.
2. 메모리 세그먼트 크기가 2인 경우:
- 블록 1: ["나", "는"]
- 블록 2: ["학", "생"] + 블록 1의 정보
- 블록 3: ["입", "니"] + 블록 1, 2의 정보
- 블록 4: ["다"] + 블록 2, 3의 정보 각 블록은 이전 2개 블록까지의 정보를 메모리 세그먼트를 통해 참조할 수 있습니다.
이 예시에서 볼 수 있듯이, 메모리 세그먼트는 현재 블록이 이전 블록들의 정보를 참조할 수 있게 해줍니다. 메모리 세그먼트의 크기가 클수록 더 많은 이전 블록들의 정보를 활용할 수 있지만, 그만큼 계산량도 증가하게 됩니다.
Contribution
- Feedback Attention Memory (FAM) 제안
- 저자들은 Transformer에 피드백 메커니즘을 도입한 새로운 아키텍처인 TransformerFAM을 제안합니다.
- FAM은 블록 단위로 정보를 압축하고, 이를 다음 블록으로 전파하는 피드백 루프를 통해 Transformer 내에 워킹 메모리를 구현합니다.
- 이를 통해 TransformerFAM은 긴 시퀀스에 대해서도 효과적으로 정보를 전달하고 장거리 의존성을 포착할 수 있게 됩니다.
- 무한한 길이의 시퀀스 처리 가능
- TransformerFAM은 FAM을 통해 이전 블록들의 정보를 지속적으로 압축하고 전달할 수 있으므로, 이론적으로 무한한 길이의 시퀀스를 처리할 수 있습니다.
- 이는 기존 Transformer의 고정된 컨텍스트 길이 제한을 극복한 것으로, 더 긴 문서나 시퀀스를 다룰 수 있게 합니다.
- 기존 사전 학습 모델과의 통합 용이성
- TransformerFAM은 기존 Transformer 아키텍처에 새로운 가중치를 추가하지 않고도 구현될 수 있습니다.
- 이는 기존의 사전 학습된 Transformer 모델들을 TransformerFAM으로 쉽게 전환할 수 있음을 의미합니다.
- 따라서 TransformerFAM은 기존 연구의 성과를 활용하면서도 긴 시퀀스 처리 능력을 향상시킬 수 있습니다.
- 다양한 태스크에서의 성능 검증
- 저자들은 다양한 크기의 언어 모델(1B, 8B, 24B)에 TransformerFAM을 적용하여 그 효과를 검증했습니다.
- 장문 컨텍스트 이해 태스크(NarrativeQA, Scrolls-Qasper 등)와 GPT-3 벤치마크 태스크 등에서 TransformerFAM이 기존 모델 대비 성능 향상을 보였습니다.
- 이는 TransformerFAM이 실제 응용에서도 효과적으로 사용될 수 있음을 시사합니다.
4. 실험 및 결과
Dataset
- Fine-tuning에는 Flan 데이터셋의 instruction data를 사용
- 최대 8.5k 토큰으로 패딩
- 장문의 연속적인 텍스트(예: 교과서, 소설 등)가 이상적이지만, 적절한 데이터셋을 찾기 어려움
- 평가를 위해 다양한 장문 컨텍스트 태스크 데이터셋 사용
- NarrativeQA, Scrolls-Qasper, Scrolls-Quality, XLSum 등
- 토큰 수, 평가 지표, 태스크 설명 등 데이터셋 세부 정보는 Table 10에 정리
- GPT-3 벤치마크 태스크도 평가에 활용
Baseline
- TransformerBSWA: Block Sliding Window Attention을 적용한 Transformer
- BSWA의 메모리 세그먼트 크기를 0에서 8까지 변화시켜가며 실험
Results
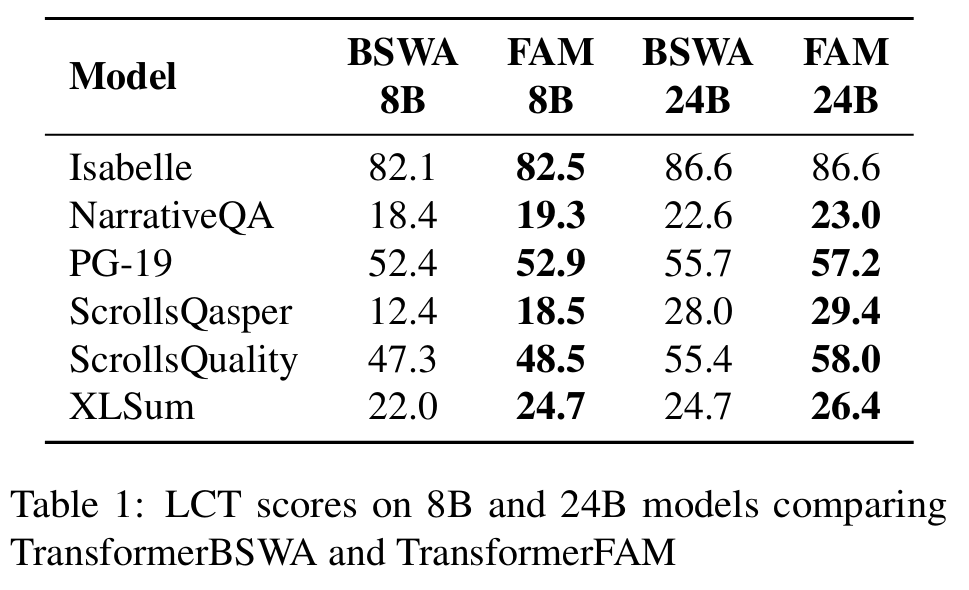
- Long Context Tasks (LCT)에서 TransformerFAM이 TransformerBSWA 대비 우수한 성능을 보임 (Figure 4)
- 특히 ScrollsQasper와 NarrativeQA 등 장문 이해가 중요한 태스크에서 큰 성능 향상
- BSWA의 메모리 세그먼트 크기에 관계없이 TransformerFAM이 더 좋은 성능

- 1B 모델뿐만 아니라 8B, 24B 대규모 모델에서도 TransformerFAM의 우수한 성능 확인 (Table 1)
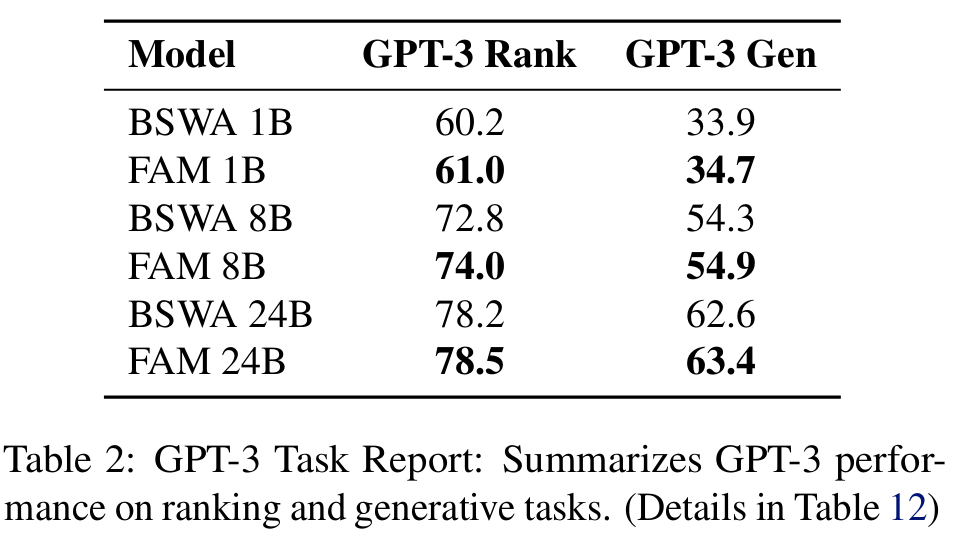
- GPT-3 벤치마크 태스크에서도 TransformerFAM이 약간의 성능 향상을 보임 (Table 2)
- FAM을 통해 컨텍스트 정보를 효율적으로 압축하고 전달하는 것이 전반적인 성능 향상으로 이어짐
- Ablation Study를 통해 FAM 길이, Random Position Offset, Random State Passing 등 세부 요소의 영향 분석 (Section 3.4, Figure 6, 7, Table 3, 4)
Conclusion
- TransformerFAM은 Feedback Attention Memory를 통해 Transformer에 워킹 메모리 능력을 부여
- 실험 결과, TransformerFAM은 장문 컨텍스트 이해 태스크에서 기존 Transformer 대비 우수한 성능을 보임
- TransformerFAM은 대규모 언어 모델의 장문 처리 능력을 향상시킬 수 있는 효과적인 방법으로 확인됨
- 향후 연구를 통해 TransformerFAM의 성능을 더욱 개선하고, 다양한 태스크에 적용할 수 있을 것으로 기대됨
4. 주요 질문
근데 전체를 보는 attention 기법이 transformer의 성능을 올리는 주된 방법이라고 생각하는데, 블록 단위로 나누면 RNN + attention 과 같은 문제가 발생하는거 아니야? 이전 정보만 확인하는거잖아 ! - 내 질문
블록 단위로 나누어 처리하는 것은 일종의 trade-off라고 볼 수 있습니다. 전체 시퀀스에 대해 full attention을 수행하는 것이 가장 이상적이지만, 이는 계산량과 메모리 사용량 측면에서 너무 많은 비용을 요구합니다. 특히 입력 시퀀스가 매우 길어지면 현실적으로 full attention을 적용하기 어려워집니다.
이러한 문제를 해결하기 위해 Block Sliding Window Attention(BSWA)과 같은 기법들이 제안되었습니다. BSWA는 전체 시퀀스를 블록 단위로 나누어 처리함으로써 계산량을 줄이면서도, 메모리 세그먼트를 통해 이전 블록들의 정보를 일부 참조할 수 있도록 합니다.
하지만 말씀하신 대로, 이 방식은 RNN + Attention과 유사한 문제를 가지고 있습니다. 현재 블록은 이전 블록들의 정보만 참조할 수 있고, 전체 시퀀스를 한 번에 보지는 못합니다. 이로 인해 장거리 의존성을 포착하는 데 한계가 있을 수 있습니다.
이러한 한계를 극복하기 위해 본 논문에서는 Feedback Attention Memory(FAM)를 제안합니다. FAM은 블록 단위 처리의 장점을 유지하면서도, 피드백 메커니즘을 통해 이전 블록들의 정보를 압축하여 전달함으로써 장거리 의존성을 더 잘 포착할 수 있도록 합니다.
FAM은 현재 블록의 정보를 압축하여 다음 블록으로 전달하고, 이렇게 전달된 정보는 다시 다음 블록의 입력으로 사용됩니다. 이 과정이 반복되면서, FAM은 전체 시퀀스에 대한 정보를 축약하여 가지고 있게 되며, 이를 통해 현재 블록이 먼 과거의 정보까지 참조할 수 있게 됩니다.
따라서 FAM은 BSWA의 한계를 극복하고, Transformer의 장점을 유지하면서도 RNN과 같은 순차적 모델의 장점을 일부 가져올 수 있는 방법이라고 볼 수 있습니다. 이러한 특성 때문에 FAM이 긴 시퀀스를 처리하는 데 효과적이라고 저자들은 주장합니다.