[논문리뷰] A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics - 헬스케어에 사용되는 LLM들을 조사해보자
ABSTRACT
논문 "A Survey of Large Language Models for Healthcare"는 헬스케어 분야에서 대규모 언어 모델(Large Language Models, LLMs)의 중요성과 발전에 대해 광범위하게 다룹니다. 이 연구는 기존의 사전 훈련된 언어 모델(PLMs)에서부터 최신 LLMs로의 진화를 추적하며, 이러한 모델들이 어떻게 헬스케어 응용 프로그램의 효율성과 효과성을 향상시킬 수 있는지 탐구합니다. 이는 환자 상담, 의료 질문 응답, 진단 지원과 같은 다양한 영역에서 LLMs의 활용 가능성을 시사합니다.
논문은 또한 PLMs와 최신 LLMs 간의 비교를 통해 LLMs의 진보된 능력과 한계를 분석하고, 헬스케어 분야에 적합한 훈련 데이터, 방법론 및 최적화 전략에 대해 설명합니다. 특히, 헬스케어 설정에서 LLMs를 배포하는 데 있어 고려해야 할 중요한 윤리적, 사회적 고려사항을 조사하며, 이는 공정성, 책임, 투명성 및 윤리적 문제를 포함합니다.
마지막으로, 논문은 헬스케어 분야에서 LLMs의 미래 개발 및 활용 방향에 대한 통찰력을 제공합니다. 이 조사는 컴퓨터 과학과 헬스케어 전문 분야의 관점에서 LLMs의 현재 상태와 미래 잠재력을 종합적으로 평가하며, 오픈 소스 자원을 포함하여 컴퓨터 과학 커뮤니티를 지원합니다. 이러한 연구는 PLMs에서 LLMs로의 패러다임 전환을 강조하며, 이 전환은 판별적 AI 접근 방식에서 생성적 AI 접근 방식으로, 모델 중심 방법론에서 데이터 중심 방법론으로의 변화를 포함합니다.
Main Idea
LLMs의 헬스케어 분야 진입: 대규모 언어 모델들(LLMs)이 헬스케어 분야에 도입되면서, 전문적 지식을 활용해 자유 형식의 질문에 효과적으로 응답할 수 있는 능력 때문에 큰 기대와 우려를 모두 불러일으키고 있습니다.
PLMs에서 LLMs로의 전환: 이 연구는 전통적인 사전 훈련된 언어 모델(PLMs)에서 최신 LLMs로의 발전을 추적합니다. 이는 판별적 AI 접근 방식에서 생성적 AI 접근 방식으로의 전환을 포함하며, 모델 중심 방법론에서 데이터 중심 방법론으로의 이동을 나타냅니다.
헬스케어 응용 프로그램에 대한 LLMs의 잠재력: LLMs가 다양한 헬스케어 응용 프로그램의 효율성과 효과성을 높일 수 있는 방법을 탐구합니다. 이는 환자 상담, 의료 질문 응답, 진단 지원 등 다양한 영역에 걸쳐 있습니다.
LLMs와 PLMs의 비교 분석: 이전 PLMs와 최신 LLMs 간의 비교를 통해 LLMs의 진보된 능력과 한계를 분석합니다.
헬스케어 분야의 훈련 데이터와 방법론: 헬스케어 분야에 적합한 훈련 데이터, 방법론 및 최적화 전략을 요약하고 설명합니다.
윤리적 및 사회적 고려사항: 헬스케어 설정에서 LLMs를 배포할 때 고려해야 할 윤리적, 사회적 고려사항을 조사합니다. 이는 공정성, 책임, 투명성 및 윤리적 문제를 포함합니다.
컴퓨터 과학 및 헬스케어 전문 분야의 종합적 조사: 이 연구는 컴퓨터 과학 및 헬스케어 전문 분야의 관점에서 LLMs의 현재 상태와 미래 잠재력을 종합적으로 평가합니다.
Key Points
LLMs의 헬스케어 분야 진입과 파급 효과 PLMs에서 LLMs로의 진화 헬스케어 분야에서의 LLMs 훈련 전략 이 연구는 컴퓨터 과학 및 헬스케어 분야에서 LLMs의 현재 상태와 미래 잠재력에 대한 종합적인 조사를 제공
Reading notes
논문 "A Survey of Large Language Models for Healthcare"는 헬스케어 분야에서 대규모 언어 모델(LLMs)의 진화와 응용 가능성을 조사합니다. 전통적인 사전 훈련된 언어 모델(PLMs)에서 LLMs로의 전환과 그들의 헬스케어 응용 프로그램에서의 잠재력을 탐구하며, 헬스케어 설정에서 LLMs의 도입이 윤리적, 사회적 고려사항을 포함한 다양한 도전에 직면하고 있음을 논의합니다.
Interesting Points in Paper
Summarily, we contend that a significant paradigm shift is underway, transitioning from PLMs to LLMs. This shift encompasses a move from discriminative AI approaches to generative AI approaches, as well as a shift from model-centered methodologies to datacentered methodologies.
PLMs에서 LLMs로의 중요한 패러다임 전환이 진행 중이며, 이 전환은 판별적 AI 접근 방식에서 생성적 AI 접근 방식으로, 모델 중심 방법론에서 데이터 중심 방법론으로의 변화를 포함합니다. -> 이 논문에서 말하는 '판별적 AI' 접근 방식은 주어진 데이터를 분류하거나 예측하는 데 중점을 두는 방식을 의미하고 '생성적 AI' 접근 방식이란 새로운 데이터를 생성하거나 예측하는 데 중점을 두는 방식을 의미합니다. "모델 중심 방법론"에서 "데이터 중심 방법론"으로의 전환은 AI 모델의 설계와 훈련에 있어 데이터의 중요성과 역할이 증가하고 있음을 나타냅니다.
PLMs(Pretrained Language Models)는 자연어 처리(NLP) 시스템의 일부로서 음석 인식, 메타포 처리, 감정 분석, 정보 추출, 번역 등에 주로 사용되었습니다. LLMs는 다양한 NLP 관련 작업(생물학, 화학, 의학 시험 등)에서 우수한 성능을 보여줍니다. 이러한 LLMs는 PLMs와는 다르게 독립적인 시스템으로 기능할 수 있는 능력을 보여줍니다.
Specifically, we recognize that different Healthcare scenarios require different capabilities from LLMs. For example, emotional comfort with patients needs more fluent conversations and empathy; hospital guide needs specific knowledge about the related buildings; and medical consultation needs more professional medical specialization.
헬스케어 분야에서 다양한 시나리오는 LLMs에게 각기 다른 능력을 요구합니다. 특정 임상 요구에 부합하는 LLMs의 정확한 선택을 도울 수 있도록 노력해야합니다.
특히, 우리는 먼저 헬스케어 응용 프로그램의 효율성과 효과성을 높일 수 있는 LLM의 잠재력을 탐구합니다. 이때 강점과 한계를 모두 강조합니다. 둘째로, 이전의 PLMs와 최신 LLMs를 비교하고, 서로 다른 LLMs 간의 비교도 수행합니다.
그 다음으로, 관련 헬스케어 훈련 데이터, 훈련 방법, 최적화 전략 및 사용법을 요약합니다. 마지막으로, 헬스케어 설정에서 LLM을 배포하는 데 따른 독특한 우려사항, 특히 공정성, 책임, 투명성 및 윤리에 대해 조사합니다.
우리의 조사는 컴퓨터 과학과 헬스케어 전문 분야의 관점에서 종합적인 조사를 제공합니다. 헬스케어에 대한 우려를 논의하는 것 외에도, 접근 가능한 데이터셋, 최신 방법론, 코드 구현 및 평가 벤치마크 등을 포함한 오픈 소스 자원 모음을 컴퓨터 과학 커뮤니티에 제공합니다.
요약하면, PLMs에서 LLMs로의 중요한 패러다임 전환이 진행 중이며, 이 전환은 판별적 AI 접근 방식에서 생성적 AI 접근 방식으로, 모델 중심 방법론에서 데이터 중심 방법론으로의 변화를 포함합니다.
본 논문의 survey 조직도. 각 섹션은 헬스케어분야에서의 PLMs와 LLMs의 적용, 기존 연구와 차이점, LLMs의 훈련 및 활용, 평가 방법, 그리고 공정성, 책임, 투명성, 윤리와 같은 주제들을 다룹니다.
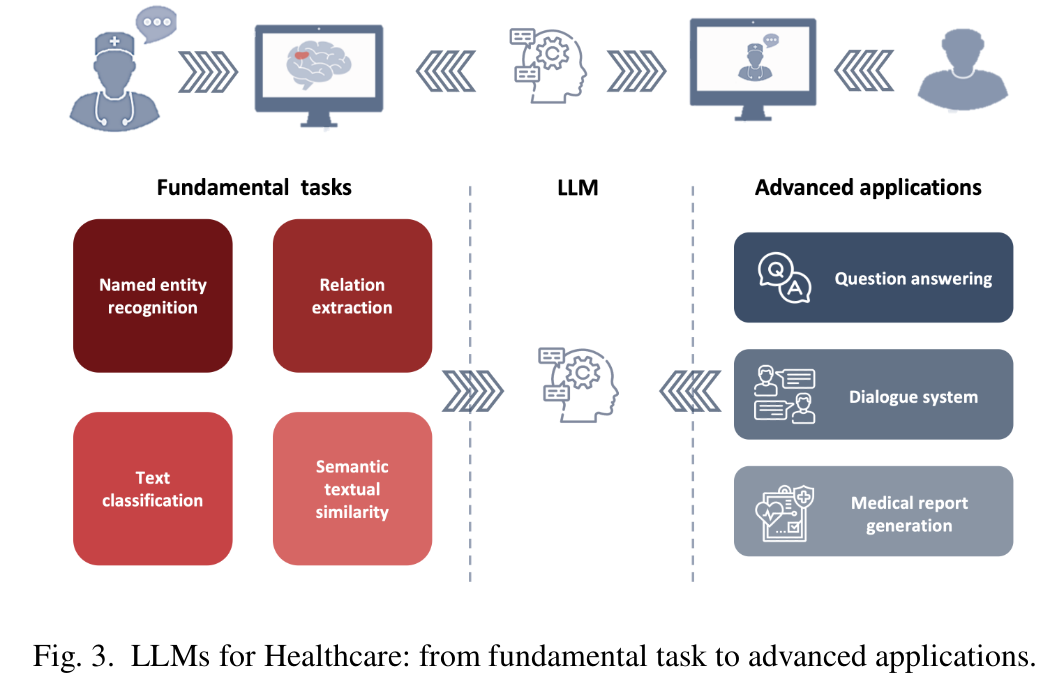
Fundamental tasks (기본 작업) : - 명명된 개체 인식(NER)과 관계 추출(RE) : 의학적 개체(약물, 부작용, 단백질, 화학 물질)를 추출하고 이들 간의 관계를 예측합니다. - 텍스트 분류(TC) : 다양한 길이의 텍스트에 라벨을 할당하는 작업으로, 전자 건강 기록에 수집된 환자 데이터를 분석 - 의미적 텍스트 유사성(STS) : 두 문장이나 구절이 얼마나 유사한지 측정하며 특히 EHR에서 중요
Advanced applications(고급 응용) : - 의료 질문 응답(QA) : 의료 전문가와 환자들이 필요한 정보를 찾는 것에 도움을 줌. 환자 상담 및 의료 문헌 검색 - 헬스케어 대화 시스템 : 환자와 의료 전문가를 지원하는 챗봇과 같은 시스템. 병원 안내나 약물 상담 등의 특정 작업에 초점을 맞춤 - Medical report generation(이미지로부터 의료보고서 추출) : 임상 결정을 돕고 보고서 작성 부담을 줄임
PLMs와 LLMs 기반 대화 시스템 비교 - PLMs 기반 시스템은 다수의 하위 모듈로 구성되어 있으며, 이러한 개별 모듈 각각이 시스템의 실제 응용에 있어서 잠재적인 병목 현상을 일으킬 수 있습니다. 반면 LLMs 기반 시스템은 강력한 LLM을 활용하여 원래의 파이프라인 시스템을 종단간 시스템으로 변환활 수 있으며 이를 통해 사용자의 선호도에 맞추고 특정 분야에 대해 미세조정(fine tuning)할 수 있습니다.
다양한 헬스케어 관련 LLM 모델들과 학습데이터를 정리해서 보여줍니다. 또한 어떤 task에 적합한지 나와있습니다.
**USMLE - 미국 의사 면허 시험. MedMCQA - 의학 분야에 관련된 다중 선택 질문과 답변 PubMedQA - PubMed 데이터베이스에서 추출한 의학적 질문과 요약
성능 결과를 보면 Med-PaLM2과 GPT-4의 성능이 사람과 비슷한 것을 확인할 수 있습니다. Med-Palm 2 논문에서 비슷한 결과를 봤던거 같은데, 역시 가장 좋은 퍼포먼스를 보여주는건 GPT-4 네요
LLM의 훈련 과정에서 사용되는 여러 구성 요소들 간의 관계 - pretraining(사전 훈련) : 모델이 대규모 데이터셋을 사용하여 일반적인 언어 이해 능력을 개발하는 초기 훈련 단계 - IFT(Instruction Fine-Tuning) : 모델을 특정 지시사항에 따르도록 미세 조정 - SFT(Supervised Fine-tuning) : 지도 학습 방식을 사용하여 모델을 특정 작업에 더 적합하게 만드는 미세 조정단계 - RLHF(Reinforcement Learning from Human Feedback) : 인간의 피드백에서 배우는 강화 학습 방법을 통해 모델의 성능 개선 - RLAIF(Reinforcement Learning with Augmented In-context fine-tuning) : 강화학습과 증강된 맥락 기반 미세 조정을 결합한 방법.
의료 시험 분야 , 의료 QA 분야, 의료 생성 분야 , 의료 포괄적 평가 분야에서 LLMs 의 평가를 여러 카테고리로 분류하여 요약하고 있으며, 각각의 항목에 대해 구체적인 연구와 모델을 나열하고 그 결과를 제시합니다.
Towards comprehensive and multitask evaluation. The current evaluation practices predominantly concentrate on assessing the performance of LLMs on one specific medical task, which might not provide a comprehensive understanding of their capabilities across the entire medical applications. Consequently, there is a clear need for a multitask evaluation system that can comprehensively evaluate the performance of LLMs across various medical tasks. Towards multi-dimensional evaluation. While current evaluation efforts have primarily centered around accuracy, there is a growing recognition of the need for a multidimensional evaluation framework. It should consider various aspects beyond accuracy, such as the correctness of interpretation, robustness, hallucination ratio, content redundancy, biased description, and ICL capability. Increase privacy protection in the evaluation process. Medical applications inherently involve sensitive data privacy concerns that surpass those of other NLP tasks. Consequently, safeguarding privacy during the evaluation process becomes of utmost importance. One potential solution to address this challenge is the adoption of federated learning approaches [337], which enable the implementation of large-scale evaluation systems while preserving privacy
종합적이고 다작업 평가로의 전환: 현재의 평가 관행은 주로 LLMs의 특정 의료 작업에 대한 성능을 평가하는 데 집중하고 있으며, 이는 전체 의료 응용 분야에서의 그들의 능력에 대한 포괄적인 이해를 제공하지 않을 수 있습니다. 따라서, 다양한 의료 작업에서 LLMs의 성능을 포괄적으로 평가할 수 있는 다작업 평가 시스템이 필요합니다.
-다차원적 평가로의 전환: 현재의 평가 노력이 주로 정확성을 중심으로 한 것에 비해, 다차원적 평가 프레임워크의 필요성에 대한 인식이 커지고 있습니다. 이는 정확성을 넘어 해석의 정확성, 강건성, 환각 비율, 내용 중복성, 편향된 설명, ICL(In-context Learning) 능력과 같은 여러 측면을 고려해야 합니다.
-평가 과정에서의 개인정보 보호 증가: 의료 응용은 다른 NLP 작업보다 민감한 데이터 개인정보 보호 문제를 포함합니다. 따라서 평가 과정에서 개인정보 보호를 보장하는 것이 매우 중요합니다. 이러한 도전에 대응하기 위한 잠재적 해결책은 연방 학습 접근법을 채택하는 것이며, 이는 프라이버시를 보존하면서 대규모 평가 시스템을 구현할 수 있게 합니다.
결론
이 논문은 survey 논문으로 healthcare 도메인에서 사용되는 LLM에 대해 깊은 내용을 담고있습니다.
분량도 매우 많아서 처음부터 정독으로 다 읽지는 못하고 그림 위주로 이해하며 전반적인 LLM 생태계를 파악하는데 도움이 된 것 같습니다.
LLM 모델의 전반적인 발전 과정과 medical 분야에서 다양한 task들에 LLM이 어떻게 쓰이는지 굉장히 자세하게 모델 별로 나와있습니다. LLM과 healthcare 도메인에 관심이 있으신 분들이라면 꼭 읽어보시면 좋을 것 같네요.
개인적으로는 이 논문에서도 가장 높게 평가한 GPT4와 Med Palm2 모델도 읽어보시면 도움이 되실거 같습니다.